NL-026, Multi-Task Deep Neural Networks for Natural Language Understanding (2019-ACL)
공유 링크 만들기
Facebook
X
Pinterest
이메일
기타 앱
0. Abstract
MT-DNN은 Multi-Task Deep Neural Network 의 약자이다.
여러 task의 많은 데이터를 이용하여 general representation을 표현하는 게 목적
이를 이용하여 새로운 task와 domain에 적용하는데 도움이 되는 연구라고 보면 됨.
이 논문의 base는 Liu(Multi-task learning에 관련된 것)와 BERT(pretrain model)를 기반으로 한다고 보면 됨.
1. Introduction
Representation을 배우는 방법은 크게 두가지가 있다.
Multi-task learning
Language model pre-training
이 논문에서는 두 가지를 잘 융합하는 것의 힘을 보여줌.
BERT는 LM pre-training + fine-tunning 의 느낌임
OpenAI-GPT는 LM pre-training의 느낌임.
MTL(multi-task learning)의 효과를 예를 들면 "사람이 스키타는 법"을 배운다고 하자. 이 때 스케이팅을 타본 사람과 아닌 사람 두 명을 비교해보면, 스케이팅 탄 사람이 배우기 쉽다는 것이다.
또한 Supervised 학습은 데이터 양이 많이 필요하고 항상 이용가능하지 않다.(한계 있음)
MTL은 특정 task에 overfiitting되어 학습되는 효과를 regularization을 하는 효과가 있다. 즉 이를 통하여 universal representation이 가능하도록!
최근 LM의 효과를 보여주는 ref 논문이 언급되어 있는데 대표적으로 BERT가 있음.
이 논문의 핵심은 MTL와 LM pre-training의 방법을 상호보완적으로 학습에 녹이도록 하는 것.
BERT와 유사한 점은, pre-training과 fine-tunning 두 가지 step으로 학습.
BERT와 다른 점은, fine-tunning 할 시, MTL 방법을 사용.
뒤에 실험에서 보이겠지만, label이 적은 task에 대해 BERT보다 MT-DNN을 사용하는 것이 훨씬 좋다.
이 논문에서 이것을 보이기 위해 실험한 데이터세트는, SNLI, SciTail 데이터를 사용함(0.1%, 1% 정도 사용함으로 써, 효과를 입증함).
2. Tasks
MT-DNN은 4가지 NLU task를 결합함.
Single-sentence classification
Pairwise text classification
text similarity scoring
relevance ranking
이러한 것은 GLUE 데이터세트가 있음.
Single-sentence classification
CoLA: 문법적으로 맞는 지.. O X
SST-2: 긍부정 문제
Text similarity
STS-B: 문장 유사도 scoring (0~1의 값)
Pairwise Text classification
RTE, MNLI: Entailment, contradiction, neutral 세 개 중에 고르기
QQP, MRPC: 문 장 두개의 의미가 같은 문장인지 O X
Relevance Ranking
QNLI: SQuAD의 한 버전인데.. 원래는 Paragraph이 주어지고 Question에 대해 올바른 정답을 할 수 있는지에 대한 문제(binary)이다. 여기서는 이를 pairwise-ranking task(뒤에서 설명)로 처리하였고 이렇게 하면 실제로 binary로 직접 처리하는 것보다 성능이 향상이 있다.
3. The proposed MT-DNN Model
모델
이 모델은 Task specific layers전까지 사실 BERT와 똑같다고 봐도 무방한 듯?
BERT처럼 Transformer encoder을 사용하였음.
Lexicon Encoder
맨 앞에 [CLS] 토큰을 추가
만약 문장쌍이 들어오면, 문장 사이에 [SEP] 토큰을 추가
Lexicon encdoer는 1. word-piece embedding, 2. segment embedding, 3. position embedding 3가지를 합쳐서 input embedding을 한 것이다.
Transformer Encoder
Pre-training을 하는 부분이다.
BERT와 다른 점은, fine-tunning 할 시, task 별로 fine-tunning을 하지 않고 MTL로 fine-tunning 하게 된다.
생각해보면, BERT에서 feature-extraction 할 때, 이 BERT 모델은 pre-trainig만 한 모델이겠군? 그러면 이것을 실제로 another task에 적용할 때(특히 fine-tunning할 데이터가 적거나 하는 것) 잘 될지를 생각해봐야 할 것 같은데 이 논문에서 짚은 것인 듯.
그런데 이렇게 MTL로 fine-tunning하면, 좀 더 general한 representation이 될 것이고, feature-extraction할 때도, task에 좀 더 덜 민감한 representation을 가져다 쓸 수 있다는 것이 핵심인 듯하다.
Single-Sentence Classification Output
SST-2(긍부정)와 같은 것을 말함.
[CLS]의 representation을 x라 했을 때, 다음과 같이 logistic regression predict를 한다.
Text Similarity Output
이것도 마찬가지로, [CLS] token의 representation을 x라 했을 때, 다음과 같은 식으로 similarity을 구한다(유사도는 0~1의 값이므로 sigmoid 사용한 듯).
Pairwise Text Classification Output
NLI task와 같은 것을 말하는 것임.
Premisie의 embedding 결과와 Hypothesis의 embedding을 잘 연관지어서 한다고 보면 되는데.. 이 네트워크는 SAN을 이용하였음.
뒤에 SAN이 NLI SOTA 네트워크이고 이것을 사용함으로써 그냥 BERT 처럼 간단히 하는 것보다 성능이 좋음을 실험했다고 함. 근데 그냥 SAN이 이 저자가 썼던 논문이어서 쓴 거 같음..
SAN이 동작하는 것은 논문을 한번 봐야겠음.
Relevance Ranking Output
QNLI task와 같은 것을 말함.
(Q,A)가 입력이고 이 때의 [CLS] embedding을 x라 할 때 다음과 같은 식을 따름.









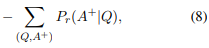









댓글
댓글 쓰기