Text Generation Evaluation 06 - ROUGE
ROUGE도 BLEU만큼 상당히 전통적으로 유명한 evaluation 방법이다. Text generation 중에서도 summarization task을 평가하는데 사용되는 것이다.
한국어로 잘 정리된 포스팅은 못 찾았고 영어로 잘 정리된 포스팅을 참고하자.
Reference Summary (gold standard – usually by humans) :
If we consider just the individual words, the number of overlapping words between the system summary and reference summary is 6. This however, does not tell you much as a metric. To get a good quantitative value, we can actually compute the precision and recall using the overlap.
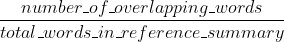
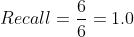
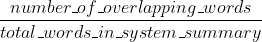
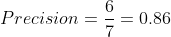
The Precision now becomes:
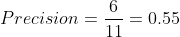
Reference Summary :
System Summary Bigrams:
Reference Summary Bigrams:
Based on the bigrams above, the ROUGE-2 recall is as follows:
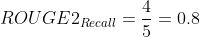
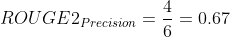
Reference
한국어로 잘 정리된 포스팅은 못 찾았고 영어로 잘 정리된 포스팅을 참고하자.
- 간단히 요약하면 BLEU는 precision 기준으로 평가하는 것이다.
- ROUGE는 이러한 문제점을 들면서 recall 부분도 같이 봐야 한다고 한다.
- 즉 ROUGE-N은 일반적으로 n-gram recall으로 평가한 metric이라고 생각하면 되는데 ROUGE-N recall/precision/F1 score 식으로 표기를 하는 것 같다.
- ROUGE precision은 BLEU와 비슷한 개념인데 BLEU에는 penalty가 존재하고 한 개의 n-gram만 사용하지 않은 점이 조금 다르다고 볼 수 있다.
- 단순히 n-gram에서 n을 지정할게 아니라 좀 더 일반적으로 ROUGE-L, ROUGE-S가 나왔다고 생각하면 된다.
- ROUGE-L은 두 문장 X, Y가 가장 겹치는 문장 길이를 이용한다. 이것으로 sentence level word order을 평가한다고 보면 된다.
- ROUGE-S은 skip-gram을 허용한다는 것인데 "I am good"이면 [I, am], [am, good] 뿐 아니라 [I, good]도 bi-gram에 포함하는 개념이다.
- ROUGE-L, ROUGE-S는 논문에서 자주 봤던거 같은데.. 좀 더 자세히 알려면 논문을 참조하길...
- 논문에서는 ROUGE-W도 소개하고 있다.
<펌 내용>
ROUGE stands for Recall-Oriented Understudy for Gisting Evaluation. It is essentially of a set of metrics for evaluating automatic summarization of texts as well as machine translation. It works by comparing an automatically produced summary or translation against a set of reference summaries (typically human-produced). Let us say, we have the following system and reference summaries:
System Summary (what the machine produced):
1
2
3
4
|
the cat was found under the bed
|
Reference Summary (gold standard – usually by humans) :
1
2
3
4
|
the cat was under the bed
|
If we consider just the individual words, the number of overlapping words between the system summary and reference summary is 6. This however, does not tell you much as a metric. To get a good quantitative value, we can actually compute the precision and recall using the overlap.
Precision and Recall in the Context of ROUGE
Simply put, Recall in the context of ROUGE means how much of the reference summary is the system summary recovering or capturing? If we are just considering the individual words, it can be computed as:
In this example, the Recall would thus be:
This means that all the words in the reference summary has been captured by the system summary, which indeed is the case for this example.
Whoala! this looks really good for a text summarization system. However, it does not tell you the other side of the story. A machine generated summary (system summary) can be extremely long, capturing all words in the reference summary. But, much of the words in the system summary may be useless, making the summary unnecessarily verbose. This is where precision comes into play. In terms of precision, what you are essentially measuring is, how much of the system summary was in fact relevant or needed? Precision is measured as:
In this example, the Precision would thus be:
This simply means that 6 out of the 7 words in the system summary were in fact relevant or needed. If we had the following system summary, as opposed to the example above:
System Summary 2:
1
2
3
4
|
the tiny little cat was found under the big funny bed
|
The Precision now becomes:
Now, this doesn’t look so good, does it? That is because we have quite a few unnecessary words in the summary. The precision aspect becomes really crucial when you are trying to generate summaries that are concise in nature. Therefore, it is always best to compute both the Precision and Recall and then report the F-Measure. If your summaries are in some way forced to be concise through some constraints, then you could consider using just the Recall since precision is of less concern in this scenario.
So What is ROUGE-N, ROUGE-S & ROUGE-L ?
ROUGE-N, ROUGE-S and ROUGE-L can be thought of as the granularity of texts being compared between the system summaries and reference summaries. For example, ROUGE-1 refers to overlap of unigrams between the system summary and reference summary. ROUGE-2 refers to the overlap of bigrams between the system and reference summaries. Let’s take the example from above. Let us say we want to compute the ROUGE-2 precision and recall scores.
System Summary :
1
2
3
4
|
the cat was found under the bed
|
Reference Summary :
1
2
3
4
|
the cat was under the bed
|
System Summary Bigrams:
1
2
3
4
5
6
7
8
9
|
the cat,
cat was,
was found,
found under,
under the,
the bed
|
Reference Summary Bigrams:
1
2
3
4
5
6
7
8
|
the cat,
cat was,
was under,
under the,
the bed
|
Based on the bigrams above, the ROUGE-2 recall is as follows:
Essentially, the system summary has recovered 4 bigrams out of 5 bigrams from the reference summary which is pretty good! Now the ROUGE-2 precision is as follows:
The precision here tells us that out of all the system summary bigrams, there is a 67% overlap with the reference summary. This is not too bad either. Note that as the summaries (both system and reference summaries) get longer and longer, there will be fewer overlapping bigrams especially in the case of abstractive summarization where you are not directly re-using sentences for summarization.
The reason one would use ROUGE-1 over or in conjunction with ROUGE-2 (or other finer granularity ROUGE measures), is to also show the fluency of the summaries or translation. The intuition is that if you more closely follow the word orderings of the reference summary, then your summary is actually more fluent.
Short Explanation of a few Different ROUGE measures
- ROUGE-N – measures unigram, bigram, trigram and higher order n-gram overlap
- ROUGE-L – measures longest matching sequence of words using LCS. An advantage of using LCS is that it does not require consecutive matches but in-sequence matches that reflect sentence level word order. Since it automatically includes longest in-sequence common n-grams, you don’t need a predefined n-gram length.
- ROUGE-S – Is any pair of word in a sentence in order, allowing for arbitrary gaps. This can also be called skip-gram coocurrence. For example, skip-bigram measures the overlap of word pairs that can have a maximum of two gaps in between words. As an example, for the phrase “cat in the hat” the skip-bigrams would be “cat in, cat the, cat hat, in the, in hat, the hat”.
For more in-depth information about these evaluation metrics you can refer to Lin’s paper. Which measure to use depends on the specific task that you are trying to evaluate. If you are working on extractive summarization with fairly verbose system and reference summaries, then it may make sense to use ROUGE-1 and ROUGE-L. For very concise summaries, ROUGE-1 alone may suffice especially if you are also applying stemming and stop word removal.
Reference
댓글
댓글 쓰기