Meta-002, Siamese Neural Networks for One-shot Image Recognition (2015-JMLR)
공유 링크 만들기
Facebook
X
Pinterest
이메일
기타 앱
0. Abstract
머신러닝에서 좋은 특징을 학습하는 것은 계산이 많이 들며, 사용 가능한 데이터가 별로 없다면 매우 어려울 것이다.
One-shot learning이란 새로운 클래스에 대해서 데이터 샘플이 단 한개만 주어지고 이를 구별하는 것이다.
이 논문에서는 siamese neural networks을 학습하는 방법으로 입력간의 유사도를 rank하는 구조를 제안한다.
네트워크가 조정되면, 새로운 데이터 뿐만 아니라 unknown 분포에서 온 데이터 또한 잘 예측할 수 있게 된다. (여기서 말하는 새로운 데이터는 같은 클래스의 test data를 의미하는 것인 듯)
Convolutional 구조를 사용하며 one-shot classification task에서 이 당시 SOTA을 달성하였다.
사람은 새로운 개념을 빨리 이해하는 능력이 있다.
머신러닝도 그러길 원하는 것!
현재 머신러닝은 다양한 분야 (web search, spam detection, caption generation, speech and image recognition) 등에서 연구가 활발히 되고 있다.
하지만 이러한 알고리즘들은 supervised learning으로써 데이터가 부족하면 작동하지 않는다.
따라서 이 논문은 데이터에 한계로 retraining이 불가능할 때, unfamiliar categories에서 일반화 하려는 목적을 가지고 있다. (online prediction setting such as web retrieval)
Classification task에서 text 해보기 전에 한 개만의 example이 주어지는 조건이 걸리는 것을 one-shot learning 이라고 부른다.
이는 zero-shot learning과는 다르다.
zero-shot learning은 target class에 대한 example을 아예 못보는 것이다.
GPT-2 리뷰 포스팅에서 다룬 것처럼 GPT-2가 하는 것들이 zero-shot learning이다.
One-shot learning에서 domain-specific 특징 or inference procedures을 target task 속성에 맞춰서 설정해서 해결할 수 있다.
하지만 다른 문제의 type에는 robust 하지 않다는 점이 있다.
이 논문에서는 novel approach는 입력의 어떠한 가정이 없고 자동적으로 모델이 feature을 잘 얻을 수 있도록 generalize을 하는 것이다.
모델 구조는 많은 layer의 non-linearities을 부과하여 input space에서 transformation을 캡쳐한다고 한다.
지금봤을 땐 뭐 특별한 것은 없는 듯 한데..?
1. Approach
일반적으로 image representation을 supervised metric을 통하여 siamese neural network을 학습한 후, 이를 재사용하여 one-shot learning 에서 feature을 뽑아낸다. (without retraining)
여기서는 character recognition에 대해서 실험을 하지만 일반적으로 다른 곳에도 적용할 수 있고 다음과 같은 특징을 가진다. (장점)
a) capable of learning generic image featuresuseful for making predictions about unknown class distributions even when very few examples from these new distributions are available
b) easily trained using standard optimization techniques on pairs sampled from the source data
c) provide a competitive approach that does not rely upon domain-specific knowledge by instead exploiting deep learning techniques.
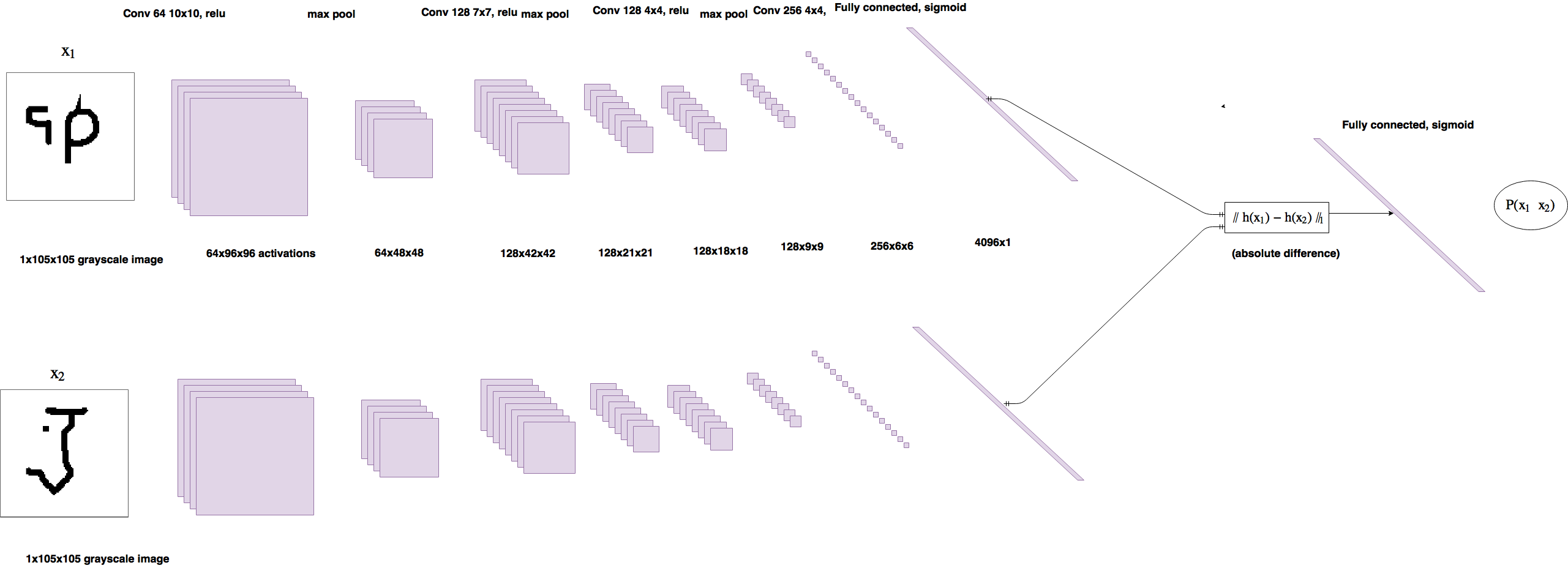
one-shot image classification 모델을 학습하기 위해서 첫 번째로 이미지 쌍의 class-identity에 초점을 맞춘다.
그림 2처럼, same, different을 내뱉은 모델
Verification model즉 입력 쌍을 구별하는 것을 배우고 출력으로 same or different class에 대한 probability을 내뱉는다.
그런 다음 모델은 새로운 이미지들에 대해 (test image) inference을 할 수 있다.
모델이 만약 alphabets의 하나의 set에 대해서 제대로 학습을 했다면 (deny or identity) 특징을 학습하기 위해 알파벳의 다양한 변화에 노출이 되었을 테고 다른 알파벳에 대해서도 잘 구별할 것이다.
2. Related Work
One-shot learning은 비교적 관심을 제한적으로 받았고 미숙하지만, 몇 개의 key lines가 있다.


개의 units을 가지고 있으며,
은 첫 번째 twin에서 layer l에서의 hidden vector이고
은 second twin에 대한 hidden vector이다.

은 3차원 tensor로 layer l에 대한 feature maps이고 *는 valid convolutional operation 이다. (valid는 conv할 때, 입력과 출력 사이즈를 맞추려고 padding을 안하겠다는 것)


, momentum은
, L2 regularization weights는
로 표기하고 각각 layers(j)에서 정의한다
으로 1 epoch당 1%씩 유니폼하게 감소

을 가지고 있으며
는 [-10, 10]의 원소
는 [-0.3, 0.3]의 원소
는 [0.8, 1.2]의 원소
는 [-2, 2]의 원소이다.



가 주어진다. (categories: C개)




댓글
댓글 쓰기