NL-041, XLNet, Generalized Autoregressive Pretraining for Language Understanding (2019-NIPS)
XLNet은 Bert 모델 이은 pre-trained 모델로 이슈를 불러온 논문이다. 물론 이미 리뷰한 MT-DNN, GPT-2도 있고 이 뒤에 읽을 Mass도 있지만 specific task의 성능을 SOTA로 가져가고 싶다면 XLNet을 이용하는 것이 좋아 보이긴 한데...
Reference
0. Abstract
- BERT처럼 Bidirectional contexts, denoising autoencoding의 기반을 둔 modeling을 통한 성능은 autoregressive language modeling보다 성능이 월등히 뛰어난다. (BERT는 양뱡향 contextual embedding with Transformer 느낌이니까)
- 그러나 BERT pretrain을 생각해보면 token을 [MASK] 처리하고 학습을 하는데, 이는 [MASK] 간의 position에 대한 dependency을 고려하지 않는다.
- 즉 15% token을 random masking하여 학습을 진행할 때, [MASK] 처리 된 token의 위치가 매번 다르고 이들 간의 dependency을 따로 고려안하는 문제가 있다고 함.
- 생각해보면 [MASK] 된 token을 DAE(denoising autoencoder) 방식으로 맞추게 되는데, [MASK] token 각각을 맞추도록 학습이 진행이 된다.
- 즉 맞춰야 할 token이 여러 갠데, 이들 서로 간의 dependency을 고려한 학습 방법이 아니라는 것!
- 또한 pretrain-finetune간의 discrepancy가 있다고 함
- finetune할 때는 [MASK] 처리를 안하기 때문에 생기는 문제를 말하는 듯 하다.
- 따라서 두 가지 방법으로 generalized autoregressive pretraining을 한 다.
- bidirectional context을 permutation of the factorization order을 통하여 maximizing likelihood을 하게 학습한다.
- 이 글만 봐서 드는 느낌은, 문장을 shuffling을 하고 [mask] 처리 한 후, autoregressive하게 likelihood가 크도록 학습을 하면 결국은 이는 bidirectional 으로 학습하는 것과 같다는 것 같은데...?
- autoregressive formulation으로 BERT의 한계를 극복한다.
무슨 말이지?- 또한 Transformer-XL을 사용한다. 이는 SoTA autoregressive model이다.
- 경험적으로 XLNet은 20개의 task에서 BERT보다 성능이 좋음을 보여준다. (꽤 큰 margin으로)
- 그리고 18 task에서 (QA, NLI, sentiment analysis, document rankings) SoTA을 달성한다.
1. Introduction
- Unsupervised representation lerarning은 NLP에서 성공적인 연구를 보이고 있다.
- 그 중에서 autoregressive (AR) language modeling 과 autoencoding (AE) 방법이 성공적인 pretraining 방법이다.
- AR language modeling은 다음과 같다.
- 시퀀스
가 주어질 때
로 forward product를 factorize the likelihood을 하는 것이다.
- 혹은 backward 하게는
가 되는 식
- 즉 한 방향으로 현 step에서 이전 step 값들 만을 가지고 예측한다는 것. (신호처리에선 casual 그 개념)
- AR language model은 uni-directional 하게 encode context 하도록 모델이 학습되기 때문에 deep bidirectional context 을 모델링 할 때 효과적이지 않다.
- 반대로 downstream language understanding task에서는 종종 bidirectional context 정보를 필요로 한다.
- 이 결과가 AR language modeling과 effective pretraining 간의 gap을 만들어 낸다.
- 즉 AR은 uni-directional이고 task가 bidirectional context 정보를 필요로 하는 상황일 땐, AR pretraining이 별로라는 결론!
- AE를 기반으로한 pretraining은 정확한 density estimation을 예측하는 것이 아니라 corrupted input에서 original data을 복구하는 것이 목표이다.
- 대표적으로 BERT가 있고 입력에 special symbol [MASK] 으로 특정 부분만큼 token을 대체하는 것이다.
- 모델은 [MASK] token을 original token으로 복구하는 작업으로 학습이 된다.
- BERT의 density estimation이 objective의 일부분은 아니므로 양뱡항 context을 이용하여 reconstruction을 할 수 있다.
- 즉 BERT는 앞서 말한 AR language modeling에서 발생하는 bidirectional information gap에 대한 문제가 없어서 성능 향상을 이끌어 낸다.
- 하지만 BERT에서 사용하는 인공적인 [MASK] token은 real data로 finetuning 할 시에는 사용하지 않기 때문에 pretrain-finetune discrepancy가 발생한다.
- 또한 predicted tokens은 masked된 입력이기 때문에 BERT는 AR modeling 에서의 product rule(autoregressive 하게)을 이용한 joint probability을 사용할 수 없다.
- 다른 말로는 unmasked tokens들이 주어지면, BERT가 예측하는 predicted tokens은 서로가 독립적이라는 것을 가정한다.
- 이는 high-order하게 oversimplified이다.
- long-range dependency는 일반적으로 natural language에서 행해진다.
- 즉 BERT 학습을 생각해보면, [MASK] token을 예측할 때, 각각을 독립적으로 예측하는 loss을 가지고 있다.
- AR 모델처럼, 현재 step에서 token을 예측할 때 지금 까지 예측했던 token을 이용한 product rule 같은 것을 사용하지 않는다.
- 그렇게 되면, 너무 과한 단순화라는 문제점을 말하는 것이고 long-ragne 문제점도 있다는 것 같다. (길이가 긴 context일 수록 이 문제점이 깊어진다?)
- XLNet에서는 일반화된 autoregressive 방법으로 AR langugae modeling과 AE 에서의 한계점을 피한 best들을 이용한다.
- AR model처럼 단방향으로 (forward or backward) maximize expected log likelihood 으로 학습을 한다.
- 단 이 때 all possible permutations of the factorization order을 가지는 sequence을 다룬다고 한다.
- 따라서 각 위치의 context는 left, right 둘다에서 올 수 있다고 한다.
- 따라서 모든 방향에서 부터의 contextual information을 사용한다는 것이다. (bidirectional context 처럼.. 하지만 무작위 방향으로 왔다리 갔다리 느낌)
- XLNet은 입력을 corruption을 하지 않음으로써 pretrain-finetune간의 discrepancy을 없앴다.
- 또한 autoregressive로 product rule로 predicted tokens의 joint probability을 학습하는 식으로하여 BERT의 independence 가정을 없앴다.
- Transformer-XL에서 사용한 recurrence mechanism과 relative encoding scheme을 이용하여 longer text sequence에 대한 성능을 향상을 이뤄냈다.
- 기존의 Transformer-XL 구조를 permutation-based language modeling에 적용하는 것은 factorization 순서가 임의적이고 target이 모호하기 때문에 적절하지 않다고 한다.
- 따라서 reparameterize Transformer으로 이러한 ambiguity을 없애준다.
- 뒷 부분에 나오겠지만 이 부분이 개인적으로 궁금하다. 어떤식으로 permutation을 했지만, factorization 순서의 모호성을 없앴는지!
- XLNet은 18 task에서 SOTA이다.
- 7개 GLUE language understanding tasks
- 3개 reading comprehension (SQuAD, RACE)
- 7개 text classification task (Yelp, IMDB)
- ClueWeb09-B document ranking task
- Related Work
- Permutation-based AR 모델링은 이전 연구에도 있었지만, 그 논문들과 key difference가 다르다고 하다.
- XLNet은 positional encoding과 함께 order-aware가 필수적이다.
- Orderless model은 일반적으로 bag-of-words, 표현력 부족 등으로 변질된다.
- XLNet은 AR language model이 bidirectional context을 학습할 수 있도록 하는 것이 motivate다.
2. Proposed Method
2.1 Background
- Conventional AI language modeling과 BERT을 비교한다.
- Text sequence
가 주어졌을 때 AR modeling은 다음과 같이 pretraining을 하게 된다.

은 모델에 의해 생성된 context representation (RNN or Transforemer와 같이)
- e(x)는 embedding of x이다.
- 즉 현재 t step에서 token을 예측할 때, t step 이전까지의 context representation과 모든 token들과의 비교를 해서(내적으로) x_t가 나오도록 theta을 학습하겠다는 것
- BERT는 15% 비율로 랜덤하게 x tokens을 special symbol [MASK]로 치환한다.
는 corrupted version이라고 하자.
는 masked tokens이다.
- 이 때 학습 objective는

가 masked 일 때,
=1의 값을 가진다. 즉 masked 된 입력에 대해서 recon 하는 loss 설정한다는 것
는 Transformer을 의미한다.
- length-T의 text sequence에 대한 hidden vectors은
과 같이 된다.
- 예를 들면) masked token x3을 recon 할 때 m3=1이 되고 H(x)3 (x3의 transformer 결과)와 모든 token embedding과 비교해서 가장 x3과의 확률이 가장 크도록 학습을 하겠다는 것
- 두 가지 pretraining objectives의 장점과 단점이 다음의 관점에서 있다.
- Independence Assumption
- 식 (2)를 보면 ≈ 으로 되어 있다. 즉 같은 것은 아니고 유사하다는 것인데 이것은 BERT가 joint conditional probability
을 계산할 때, all masked tokens
- 즉 masked tokens이 각각 재구성이 되도록 한다는 것이다.
- 반면 AR language modeling obj인 (1)은 independence 가정없이
을 factorize하는 식이다. (순차적으로 token을 예측하기 때문에)
- Input noise
- BERT에서 [MASK] 심볼은 downstream에서는 없는 것이기 때문에 pretrain-finetune discrepancy가 있다.
- [MASK]을 original tokens으로 대체한 것은 BERT에서 이 문제를 해결해주지 않는다고 한다.
- 왜냐하면 original tokens은 작은 확률만을 사용하기 때문이다.
- 좀 더 자세히 보면) BERT 논문의 C.2절에서 다음의 그림과 같이 실험을 하였다.

- 여기서 2번째행이랑 4번째행을 비교해보면, MASK가 100에서 80으로 줄이고 대신 SAME을 20가져갔음에도 성능이 좋아지지 않았다는 것이다.
- 따라서 MASK을 줄인다 해도 큰 효과가 없다라는 것 같은데
- 개인적으로 MASK,SAME,RND을 0,100,0 비율로 한 결과는 어떨지 궁금하다... 왜 SAME은 작은 확률만 사용했는지.
- 끼워맞춰서 생각하면 SAME을 큰 비중으로 가져가면 context 정보를 알아서 token을 예측하기 전에 이미 입력이 정답 token을 포함하기에 진정한 context embedding의 개념은 잘 학습이 안될 것 같기도..
- 좀 더 궁금증을 해결하기 위해 일반적으로 AE가 아닌 DAE를 사용했을 때의 장점은 다음 링크를 참조하면 좋을 것 같다. (링크1, 링크2)
- AR language modeling 입력의 corruption에 의존하지 않기 때문에 이러한 문제가 없다.
- Context dependency
- AR representation
는 양방향의 (left, right) 정보를 이용한다.
- 따라서 BERT는 양방향 context을 잘 캡쳐한 pretrained model이다.
2.2 Objective: Permutation Language Modeling
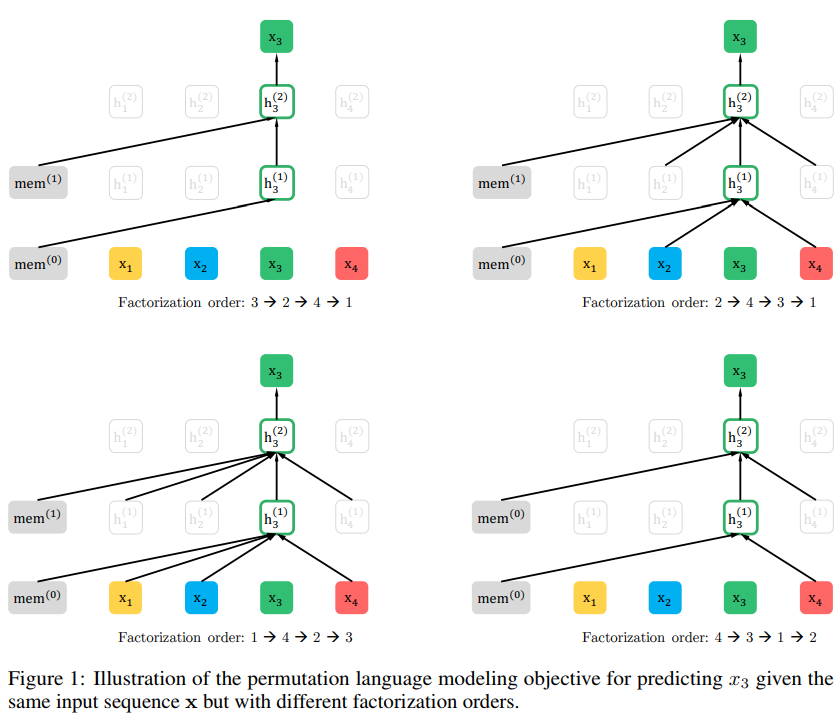
- 그림을 보면, Factorization 순서가 2, 4, 3, 1 이면 token 3을 LM을 맞춰야하는 상태에서 previous 2, 4,token을 joint probability로 활용하는 식이다. (그림 처럼)
- AR language modeling과 BERT 모두 각각의 장점이 있고 이의 약점은 없고 장점만을 가져오는 pretraining objective가 있을까 의문이다.
- 순서가없는 NADE(ref)로 부터 영감을 얻어, permutation language modeling objective을 제안한다.
- 이는 AR model의 장점을 유지할 뿐 아니라 model이 bidirectional context을 capture 할 수 있도록 한다.
- 만약 길이 T의 sequence x가 있다면, T!의 다른 order을 통한 autoregressive factorization을 할 수가 있다.
- 직관적으로 모델이 모든 factorization 순서를 고려한다면, 이 모델은 모든 방향으로 부터의 양쪽 방향을 학습할 수 있다.
- 즉 어느 token에서 다음 token의 순서가 왼쪽, 오른쪽 모두 가능하다.
- 모든 permutation에 대해 고려를 한다면, 모델은 모든 위치에서 양방향에 대한 정보를 얻을 수 있다.
가 길이 T인 sequence
에서 가능한 모든 permutations의 set이다.
는 t번째 element이고
는 permutation
의 앞의 t-1번째 element이다.
- 여기서 제안하는 permutation language modeling objective는 다음과 같다.

- 즉 이 뜻은 text sequence x에서 factorization order z을 샘플링하고 여기서 likelihood
을 재구성하는 식이다.
- 학습시 permutation에 따라 모델이 같은 parameter
을 공유하면
- 게다가 이는 AR framework 방식의 objective기 때문에 token들 간의 independence 가정과 pretrain-finetune discrepeancy도 피할 수(입력에 노이즈를 않넣기 때문에) 있다.
- Remark on Permutation
- 제안된 objective 는 단순히 factorization order만을 바꾸는 것이다.
- 즉 sequence order을 바꾸는 것이 아니라 기존의 sequence order은 유지하고 positional encodings만 바꿔서 Transformer의 attention mask에 적용한다는 것이다.
- 이렇게 해야하는 이유가 모델이 finetuning 때에는 natural order과 함께 text sequence을 적용해야 하기 때문이다.
- 당연한 말인 것 같은데 코딩 때 고려해야하는 부분이란건가? 결국 개념은 학습시 sequence order가 바뀌는 것으로 LM을 학습하는거 같은데. finetune 때는 sequence order가 안바뀌므로 엄밀히 말하면 sequence order은 그대로이고 positionial encoding을 이용한다는 거 같음. 근데 Transformer-XL에서 recurrence mechanism을 이용할 땐, 똑같이 permutation된 순서로 previous 정보를 가져오는 거겠지?
2.3 Architecture: Two-Stream Self-Attention for Target-Aware Representations
- Permutation Language modeling objective에서 navie한 방법은 (standard Transformer) 제대로 작동하지 않는다.
- 이 문제를 알아보기 위해 next-token distribution을
와 같이 표기한다.
- 이는 softmax formulation을 통하여 다음과 같이 된다.
는 proper masking후 shared Transformer network로 생성된
의 hidden representation이다.
- 리마인드로 z는 permutation의 위치라 생각하면 되고 x는 sequence이다. 예를 들어) x_(z3)은 permutation 했을 때 3번째 순서가 5라고 하면 x5에 해당하는 x토큰을 의미하는 것이다.
- 위와 같이 학습을 한다고 생각하면 zt의 위치에 상관없이 학습을 하게 된다는 것이다.
- 부록 A.1을 참고해보면 다음과 같다.

- 위의 말은, permutation이 z1과 z2가 있고 각각 t-step이전의 시퀀스는 같고 t-step에서의 값은 i와 j로 각각 다른 값을 가진다고 하자.
- 그러면 t-step에서 학습을 할 때 condition인 z<t는 같고 z1t=i가 되는 것과 z2t=j가 되는 것은 다른 확률을 가져야 하는데 위와 같이 같은 수식으로 학습이 된다는 것이다.
- 즉 target position에 상관없이 예측을 한다는 것이고 이는 효과적인 representation을 학습할 수 없게 된다.
- 위의 문제를 풀기 위하여 re-parameterize next-token 분포를 target position을 고려하여 다음과 같이 한다.

라는 term으로 바뀌었는데 이는 새로운 type의 representation이다.
- 이 때,
- Two-Stream Self-Attention
- 위와 같이
을 계산하는 것은 사소한 문제가 아니고 standard Transformer 구조를 사용하는데 다음과 같은 문제가 있다.
- token
을 예측할 때,
는 사용하지 않는다. 반면에 obj는 사소해진다.(?)
인 다른 tokens을 예측할 때 (j>t)
- 예를 들어) "나는 집에 가고 싶다" →(permutation) "집에 싶다 나는 가고" 가 되었다고 하자.
- 즉 z=(2, 4, 1, 3)가 되는 상황이다.
- step-1
- t=3인 상황이라고 하면, z<t = (2,4)이고
=(집에, 싶다)가 되는 것이다.
- 여기서 t=3일 때 token
- step-2
- 그러나 t=4일 때에는 예측해야하는 token
- 여기서 "나는"이라는
이 필요한 것이다.
- 그러면 step-1과는
- 즉 step-1과 step-2에서 모델이 접근을 할 수 있는 범위가 다르게 된다.
- 다시 이해해보면 contextual information을 할 때에 (tokens)들만을 가지고 attention하는 경우와 (tokens+현 step

- 그림을 그려서 설명을 돕자면, (t=3) step-1과 (t=4) step-2에서 "나는"과 다른 token들 간의 attention을 구할 때 step-1에서는 "나는"의 position 값만, step-2에서는 postion+word embedding이 들어가기 때문에 한 모델로 학습하면 안된다는 것
- Content representation은
=
으로 표기한다. 이는 context와
을 모두 이용한 encode의 결과이다. (일반적인 transformer에서의 representation)
- Query representation
=
으로 표기한다. 이는 contextual information
와

- 따라서 위의 그림처럼 두 가지 stream을 가져가게 된다.
- 계산상으로 첫 번째 층의 query stream은 trainable vector
으로 한다.
- Context stream의 첫 번째 층은 word embedding에 해당하는
으로 한다.
- 즉 그림의 왼쪽열의 위아래를 처럼 두 개의 모델을 attention 과정을 통해 h,g를 구하는 것이다.
- 학습을 할 때는 context representation은 standard self-attention과 똑같은 것이고 finetuning할 때는, query stream은 날리고 context stream을 normal Transformer-XL로써 사용한다.
- 그런데 이러면 inference할 때 context stream에는 g의 값을 안쓰는데 position에 대한 정보는 어떻게??? (2.4부분에서 설명)

- 식 (4)에서의 g에 해당하는 값이 여기서 query representatioin의 마지막 층의 값이 된다.
- 정리하자면) g의 초기값은 position을 담은 정보인데 학습 가능한 parameter을 초기값을 가지게 한다.
- 여기서 자세하게 설명은 안하는데, w라는 것은, i에 따라 다른 값을 가지는 것일 것이다. (그래야 position에 해당하는 정보니까)
- 예를 들면, i=3이면, [0,0,1,0,...] x W matrix = w_3 이런 식이 되는 형태로 학습을 할 것이다.
- 즉 Transformer에선 position embedding으로 sinusoid을 사용하였는데 여기서는 학습하겠다는 것인 듯
- 기존 Transformer에서는 h는 word의 embedding을 가지는데 원래는 여기다가 positional embedding을 추가하는데 position이라는 정보를 g로 분리했으니 h에는 추가를 안한 것 같다.
- Partial Prediction
- permutation language modeling objective (3)은 여러 장점을 가지고 있다.
- 그러나 preliminary experiments에서 permutation때문에 수렴 속도가 느리고 optimization이 어렵다.
- 이러한 optimization 어려움을 해결하기 위해, factorization order중 뒷 부분의 tokens들만을 예측한다.
- 즉
을 non-target
와 target
로 나눈다. (c가 cutting point)
- 따라서 objective 는 다음의 식 (5)을 maximize the log-likelihood을 하는 것이다.

- 여기서 hyperparameter K을 정의하는데 이는 1/K tokens 만ㅇ 선택하여 predictions을 하겠다는 것이다.
- 즉 cutting point 뒷 부분의 tokens수가 전체의 1/K만큼 되는 것으로
을 따른다.
- 선택되지 않는 (predict 안하는) query representation은 계산할 필요가 없다.
- 이렇게 하면 왜 optimization이 잘 될까? 에 대해서는 언급이 따로 없다.
- 예상하건데 이렇게 뒷 부분을 학습할 때는, permutation과 상관없이 모델이 많은 tokens을 참조하기 때문에 예측하는 것이 쉬워서 그럴 것 같다.
- 만약 앞 부분 token, permutation된 sequence의 2번째 token을 예측하는 걸 학습하는 것을 생각해보자.
- 그러면 2번째 token은 실제로 동떨어진 위치의 어떤 한 token만을(permutation된 sequence의 1번째) 가지고 autoregressively하게 학습을 해야하는데 잘 안될 것이다.
- 왜냐하면 그 참조하는 token은 실제로 2번째 token과 상관없을 가능성이 크기 때문이다.
- 하지만 permutation이 안된 sequence 경우는 바로 앞의 token을 이용하기 때문에 token끼리 관련성이 있기 때문에 문제가 안되었던 것 같다.
2.4 Incorporating Ideas from Transformer-XL
- 위에서 말한 AR language model에 Transformer-XL을 결합한다.
- Transformer-XL에서 중요한 기술인 relative positional encoding과 segment recurrence mechanism을 결합한다.
- long sequence에서 두 개의 segment을 가지고 있다고 하자.
- 1st segment:
,
- 2nd:
- 1st segment permutation of [1...T]:
- 2nd segment permutation of [T+1...2T]:

- 두 번째 segment에서 진행되는 것을 생각해보자.
는 각 layer m에서의 content representation이다.
- m layer에서의 h를 구할 때, m-1 layer에서의 hidden 결과가 Q가 되고 m-1 layer + t step 까지의 hidden layer(
)+m-1 layer의 content representation(
)가 KV의 입력이 되는 것이 된다.
- 여기서
- mem이란 이전 segment content representation을 의미하고 이는 이전 segment에서 계산된 h을 의미하는 것이다.
- 즉 Transformer-XL처럼 정해진 길이의 이전 만큼 hidden 결과를 가져다가 쓰는데 현재 segment가 아닌 이전 segment에 해당하는 context representation에도 접근하는 식이다.
와 독립적이다.
- 다시 말하면, 이전 segment의 factorization order(
- query stream도 같은 방법으로 계산될 수 있다.
- figure. 2 (c)을 참고하면 된다. (Appendix A.4에 더 자세히)
- 2.4절의 자세한 부분은 Appendix A.2에 설명이 되어있다.

- 여기서 보면, RelAttn으로 relative attention을 하게 된다.
- 즉 여기서 relative positional encoding이 결합이 되는 것이다. (위에서 궁금했던 부분)
- 즉 애초에 figure 2.a에서의 attention block이라는 것은 relative position attention을 말하는 것이고 query stream도 똑같은 방법이라고 했으니 figure 2.a도 relative position attention을 말하는 것 같다.
- 따라서 h는 word embedding을 의미하나, attention을 통과하면서 position embedding이 추가되는 것!
- RelAttn에 대해서 따로 언급이 없으므로 position embedding은 (아마) 기존 방법대로 sinusoid을 쓸 것이며 이는 위에서 학습한 g와는 다른 거다.
2.5 Modeling Multiple Segments
- 실제 finetuning할 때의 downstream task는 많은 입력이 들어간다. 대표적으로 question과 context가 들어가는 question answering 같이.
- 이 장에선, 이걸 처리하기 위해 XLNet을 pretrain을 어떻게 하는지 multiple segment을 autoregressive framework에 넣는 방법을 설명한다.
- 임의로 두 segment을(문장이라고 생각하자) 뽑는다. (같은 context 아니여도 됨)
- 두 segment을 concatenation을 하여 permutation language modeling을 한다.
- 여기서 두 개의 segment A, B를 각각 permutaiton을 하고 concat을 하는 것이겠지?
- 왜냐하면 4번에서 입력 구성이 A, B는 구분되어 있는 상태니까...
- memory를 같은 context에 속한 것들만 재사용한다.
- 이 부분이 핵심인 것 같은데 설명이 너무 간략하다.
- 정확한 개념은 모르겠음 ㅜ
- BERT와 비슷하게 [A, SEP, B, SEP, CLS]로 구성한다. (A, B는 segment)
- 두 개의 segment data format을 따르고 BERT처럼 next sentence prediction으로 XLNet-Larnge을 pretrain해도 일관된 향상을 보여주지 않기 때문에 이를 사용하지 않는다.(ablation study에서 보임)
- Relative Segment Encodings
- BERT에서는 word embedding + abs segment embedding을 했었다.
- 여기서는 segment을 concat해서 permutation을 하는 것이기 때문에 segment relative encodings을 한다.
- (permutation) sequence의 위치 i와 j에 대한 쌍이 주어져있다고 하자.
- 만약 i와 j가 같은 segment라면, 우리는
로, 다른 segment면
로 segment encoding을 한다.
와
은 learnable model parameters for each attention head 이다.
- 이것은 두 개의 위치가 같은 segment인지 아닌지만 고려한다고 한다.
- 어떠한 segment인지는 고려안한다는 말
- 즉 segment A=segment A와 segment B=segment B가 같은 상황
- 이것은 relative encodings와 같은 개념이다.
- i위치에서 j위치를 attend을 할 때 segment encodings은
라고 하고 이는 attention weight
로 계산에 쓰인다.
- 여기서 q는 query vector
- b는 학습가능한 head-specific bias vector
- a는 계산된 후, normal attention weight에(Q,K로 구해지는 것을 말하는 듯) 더해진다.
- 이것을 사용함으로써 두 가지 장점이 있다.
- inductive bias of relative encoding은 일반화를 좋게 한다.
- task에 맞는 finetuning을 할 때, 두 개의 segment 이상을 받을 수 있다. (abs segment을 사용하지 않음으로써)
- 정리하자면)
- XLNet의 입력에 [A, SEP, B, SEP, CLS]와 같이 들어온다.
- 이를 permutation하여 LM을 학습한다.
- two stream self-attention, 즉 transformer 구조가 2개이다.
- Transformer은 Transformer-XL에서 사용한 relative encoding(permutation 순서에 따른)와 segment recurrence(memory 이용하는 개념)을 사용한다.
- segment encoding도 BERT와는 다르게 abs encoding 대신 같은 segment 인지 아닌지에 따른 s vector을 이용한다.
- [MASK] token을 사용하지 않고 (permutation) AR Language modeling이다.
- BERT와는 다르게 next prediction을 학습하지 않았고 이는 성능 효과를 가져다 주지 못하였다고 함.
2.6 Discussion and Analysis
2.6.1 Comparison with BERT
- 식 (2)와 (5)를 비교하면 BERT와 XLNet의 차이를 알 수 있다.
- 두 모델다 문장의 일부분 tokens만을 예측하도록 학습한다.
- BERT에서는 모든 token을 [MASK] 처리하면 당연히 제대로 학습이 안되기 때문에 저쩔수 없는 선택이다.
- BERT와 XLNet은 충분한 context와 함께 일부분만 token을 예측하도록 하면 optimization의 어려움을 줄일 수 있다.
- BERT에서는 2.1에서 말했던 것처럼 targets간의 model dependency를 고려하지 못한다.
- 논문에서 예시를 들어 설명한다)
- 입력: [New ,York, is, a, city]
- target prediction: [New, York]
- logp(New York | is a city)을 최대화 해야하는 문제
- XLNet의 factorization order: [is, a, city, New, York]
- objective function은 다음과 같다.

- 즉 XLNet은 (New, York)간의 dependency을 고려할 수 있는 반면에 BERT는 못한다.
- 또한 같은 sample에 대해 XLNet은 언제나 더 많은 dependency을 학습할 수 있다. (denser effective training signals 이라고 함)
- (좀 더 formal하게 표현해보자) sequence
- target-context pairs of interest
((x,U)의 조합들)
는 context을 구성하는 set of tokens (predict 해야할 x이전에 나왔던 token들의 조합들)
- 직관적으로 model이
의 loss term을 통하여 학습을 하게 되고 예시로 다음과 같다.

- 즉 예측하려는게 지금 York이고 이전에 나온 context을 구성하는 단어들로 조합한 것들이
은 가상의 개념이다 (
- (일반적으로 써보면) 학습
은 주어진 target tokens
은 non-target tokens (x에서
- BERT와 XLNet은 모두
을 maximize해야 한다.

- BERT에서는 N이 위에서의 가능한 U의 조합이 되는 것 / XLNet은 N과 T의 합집합이 가능한 U의 조합들이 됨
은
- objective는
으로 구성된 multiple loss
- Vx는 N or N U Tx을 말하는 듯
에 대해
가 존재한다면, loss term
- Definition에 의해 두 가지 case가 있다.

- 이렇게 복잡하게 수식적으로 설명하였지만, 결국은 XLNet이 BERT보다 더 많은 dependency을 다룰 수 있다.
- 따라서 XLNet objective function은 좀 더 효과적인 학습이 가능하고 section 3에서 실험적으로 더 좋은 성능을 보여준다.
2.6.2 Comparison with Language Modeling
- GPT와 같은 경우는 (x=York, U={New})에 대한 dependency는 다룰 수 있지만, (x=New, U={York})은 다룰수 없다. (GPT는 uni-direction LM이니까)
- XLNet은 모든 factorization orders에 대해 다룰 수 있다.
- 이러한 AR language modeling은 실제 세계의 application에서 문제가 됨을 예시를 통해 보여준다.
- Context: “Thom Yorke is the singer of Radiohead”
- Question: “Who is the singer of Radiohead”
- 여기서 정답은 Thom Yorke인 것을 알텐데, Thom Yorke은 Radiohead의 앞부분에 있기 때문에 Radiohead에 dependent하지 않다.
- 무슨 말이냐면, Thom York가 주어지고 Radiohead은 나오도록 학습이 되었기 때문에 Radiohead가 주어지고 Thom York을 뽑아내는데는 취약하다 이런 의미
- 수식적으로 보면 context-target pair
가 주어진 상황이다.
- (
는 기존 sequence에 있는 x의 앞에 있는 tokens라고 정의)
이면 AR language modeling은 dependency을 cover할 수 없다.
- 앞에서 기호가 의미하는게 다르다..왜이리 복잡하게 써놨는지.. 여기서는 x가 context이고 U가 target이다.
- 즉 target 부분을 예측할 때 target이전에 나오는 token들과 context가 겹치는게 없다면, dependency을 학습할 수 없다.
- 이렇게 써놓으면 복잡하니까 그냥 위의 예시대로 이해했다면 넘어가는거 추천 (똑같은 말임)
- ELMo는 forward와 backward language models을 concat한 모델로써 이러한 문제가 없다.
2.6.3 Bridging the Gap Between Language Modeling and Pretraining
- Density estimation의 근간이 되는 language modeling은 빠르게 발전하고 있다.
- 하지만 language modeling와 pretraining 사이의 gap은 bidirectional context modeling의 능력에 차이가 있다. (LM의 pretraining은 bidirectional 하지 않다는 뜻인듯)
- Downstream task를 직접 향상시키지 않는다면, language modeling이 정말로 의미있는지에 대한 의문점이 있다.
- XLNet은 language modeling의 gap을 해소했고 그 결과 language modeling 연구를 정당화 했다.
- 좀 더 나아가서, 이는 pretraining을 위한 language modeling에 대한 가능성을 보여주었고 Transformer-XL을 XLNet에 적용함으로써 LM 연구의 유용함을 보였다.
- 개인적인 생각으로 이 단락은, Transformer-XL이 학회에서 reject 당했었는데, 그 reject 당한 것에 대해서 Transformer-XL의 연구가치를 말하고 싶었던 거 같음...
3. Experiments
3.1 Pretraining and Implementation
- BookCorpus, English Wikipedia 총 13GB text 결합하여 p[retraining에 사용
- Giga5 16GB text와 ClueWeb 2012-B, Common Crawl은 pretraining을 위해 사용
- ClueWeb 2012-B 와 Common Crawl은 low-quality와 short article은 걸러낸 후 19GB, 78GB의 text 데이터임.
- Tokenization은 SentencePiece을 사용하였고 2.78B, 1.09B, 4.75B, 4.30B, and 19.97B subword pieces for Wikipedia, BooksCorpus, Giga5, ClueWeb, and Common Crawl respectively, which are 32.89B in total.
- XLNet-Large는 BERT-Large와 같은 구조의 hyperparameter와 비슷한 모델 사이즈임.
- Sequence length와 memory length는 512와 384로 설정
- memory는 Transformer-XL에서 이전 segment을 얼마나 참조할지를 의미하는 것이겠지?
- XLNet-Large은 512 TPU v3 chips for 500k steps with Adam optimizer
- linear learning rate decay and a batch size of 2048, which takes about 2.5 days.
- 이 만큼 학습했을 때 모델은 underfit이지만 더 학습한다 하여도 downstream task에 큰 효과가 없었음
- 즉 모델이 data scale을 다 이용할만큼 충분하지 않다.
- 하지만 모델을 더 큰 것에 대해서는 finetuning을 하는데 제한이 있을 수 있어서 사용하지 않았음.
- 너무 모델이 크면 실질적으로 사용하는데 힘들기 때문에 안했다고 함.
- 모델이 크면, finetuning에 필요한 데이터가 많이 들어갈 것이라 제한이 있을 수 있고 모델을 불러오고 inference 하는데 시간도 많이들고 메모리도 많이 필요하니까 너무 크면 문제가 있다?
- we use a bidirectional data input pipeline where each of the forward and backward directions takes half of the batch size.
- 밑의 글에서 이어서 설명
- XLNet-Large을 학습시 K = 6으로 설정
- 문장의 뒷 1/6 부분만 predict 하게 학습하겠다는 것
- finetuning 절차는 특별한 말없는 부분은 BERT와 똑같다.
- finetuning 때, L이란 sample length의 hyper parameter을 설정하여 span-based prediction을 이용하였다.
- L은 1부터 5까지 중에서 샘플링
- K*L tokens중 랜덤으로 고른 연속된 L tokens을 예측하는 것이라 하는데 정확히 뭔지는 모르겠고 검색해도 안나오는데.. 혼자서 생각해보자면 !!
- 단순히 말만 봐서는 만약 문장 전체길이 c=600이고 K=6이라 하면 z=500으로 stop point가 된다.
- 그러면 뒤에 100개를 prediction하는게 일반적인 설명이고 L은 100을 가리키는 것이다.
- (근데 여기서의 학습 방법은 조금 다른 개념인건데) 그대로 이해하면 K*L(<=30) 단위로 문장을 학습한다는 것인데 그럼 short sentence을 기준으로 학습하겠단 건데.. 아마 다음과 같지 않을까 싶다.
- 예시) "나는 이 말을 이해하기 어려워 짱나지만 노력하고 있다" 문장이 있다.
- K=3, L=2 이면 K*L=6으로 문장을 짜르면 "나는 이 말을 이해하기 어려워 짱나지만" 까지이다.
- 여기서 L=2이므로 랜덤한 연속된 token(단어)로 [말을, 이해하기]을 골랐다고 하자
- 그럼 문장은 "나는 이 L1 L2 어려워 짱나지만"이 되겠다.
- Note that this choice is necessary, since the model will only encounter text sequences with the natural order during finetuning.
- Finetuning 때는, natural order을 사용한다고 되어 있고 위의 bidirectional data input pipeline을 사용한다는 것을 종합해보면..
- [나는, 이] tokens이 조건이고 이 tokens을 이용한 L1과 L2를 예측하는 식으로 forward AR
- [짱나지만, 어려워] tokens이 조건이고 이 tokens을 이용한 L2과 L1를 예측하는 식으로 backward AR
- 이렇게 두 방향으로 batch를 반으로 줄여서 bidirectional input을 이용한 finetuning을 진행한다.
- 이것으로 bidirectional input이 필요한 task에 맞는 finetunning 과정인 것 같다..
- 그런데 pretraining 때는 max sequence length를 512인데 finetuning 때는 max length = K*L <= 6*5 = 30 이다.
- 위 말을 종합하면 finetuning 때는 L sampling에 따른 짧은 문장으로 pretraining 같이 다시 한번 학습해 준 건데...
- ablation study 부분에서 언급하길 span-based prediction은 필수라고 한다.
3.2 RACE Dataset
- 생략
3.3 SQuAD Dataset

3.4 Text Classification

3.5 GLUE Dataset

3.6 ClueWeb09-B Dataset

3.7 Ablation Study

- 다음 3가지를 희망하면서 연구를 하였다고 함.
- The effectiveness of the permutation language modeling objective, especially compared to the denoising auto-encoding objective used by BERT.
- The importance of using Transformer-XL as the backbone neural architecture and employing segment-level recurrence (i.e. using memory).
- The necessity of some implementation details including span-based prediction, the bidirectional input pipeline, and next-sentence prediction
4. Conclusions
- XLNet은 AR pretraining 방법의 일반화한 것이다.
- Permutation language modeling objective는 AR과 AE의 장점을 결합한 것이다.
- XLNet의 구조는 AR objective을 작업하는데 적용되고 Transformer-XL와 two-stream attention mechanism을 결합하여 신중히 설계하였다.
- XLNet은 여러 task에서 SOTA을 달성하였고 vision과 reinforcement learning으로도 확장된 연구를 하도록 계획중이다.
안녕하세요. 질문있는데, two stream attention에서 왜 시점이 다른데도 불구하고 같은 representation을 써야하는지 아실까요?? 하나는 t이고, 하나는 j>t인데, 왜 같은 representation을 사용하고 이로 인해 contradiction이 발생하는지 이해가 안되서요.
답글삭제