NL-049, Learning Semantic Sentence Embeddings using Pair-wise Discriminator (2018-COLING)
0. Abstract
- 이 논문에서는 sentence-level embeddings에 집중을 한다.
- 일반적으로 word-level embedding은 연구가 많이되어 왔는데 sentence-level embedding은 연구가 부족하고 이 논문에서는 novel method을 제시한다.
- sequential encoder-decoder 모델로 paraphrase을 생성하면 의미론적으로 기존 문장과 비슷한 의미를 담는 문장을 생성할 수 있다.
- 한 가지 방법은 true paraphrase embeddings은 가깝게, unrelated paraphrase candidate sentence embeddings은 멀게 제약을 추가하는 것이다.
- 이것은 sequential pair-wise discriminator을 사용하는 것으로
- discriminator가 encoder와 가중치를 공유하고
- encoder은 적절한 loss로 학습이 된다.
- 모델의 loss는 paraphrase sentence embedding 거리가 멀게 penalize한다.
- 이 loss는 encoder-decoder 네트워크와 결합되어 있다. (모델을 봐야 이해할 듯)
- 모델 검증은 sentiment analysis task에서 하게 된다.
- 결과는 이 당시 SoTA이고 통계적으로 중요한 결과를 보여준다.
1. Introduction
- 문장의 semantic embedding을 얻는 문제는 related sentence와는 closer하게 unrelated sentence와는 farther하는 것이 언어를 이해하는 core의 방향이다.
- 이것은 MRC의 wide 변형과 sentiment analysis와 같은 task와 연관성이 있다.
- 이 논문에서는 sequential encoder-decoder의 supervised method을 제시하였다.
- paraphrase을 생성하는 것은 semantic sentence embedding과 매우 연관성이 높다고 주장한다.
- 따라서 이 논문에서는 generated paraphrase embedding과 corresponding sentence와는 가깝게, unrelated sentence와는 far하게 하는 것을 초점으로 삼는다.
- 이런 embedding이 SoTA을 달성하는데 도움을 주었다고 한다.
- 모델은 sequential encoder-decoder로 구성되어 있는데 이는 pairwise discriminator을 이용해서 학습이 된다.
- encoder-decoder 구조는 번역에 넓게 쓰이는 구조이고 일반적으로 'local' loss라 정의되는 것으로 학습한다.
- local loss는 word token이 적절한 위치에 있도록 학습하지만 전체적인 문장이 제대로 생성되는 것을 보장하지 않는다. (각 step cell에서 word와 비교해서 정의하는 loss임)
- 따라서 여기서는 'global' loss라는 것을 정의해서 sentence embedding이 다른 related sentence embeddings와 의미론적으로 비슷하게 한다.
- 이것이 SoTA을 달성하는데 도움을 줬다고 한다.

- Contribution
- a) We propose a model for obtaining sentence embeddings for solving the paraphrase generation task using a pair-wise discriminator loss added to an encoder-decoder network.
- b) We show that these embeddings can also be used for the sentiment analysis task.
- c) We validate the model using standard datasets with a detailed comparison with state-of-the-art methods and also ensure that the results are statistically significant.
2. Related Work
- 시간될 때 읽어봐야지..
3. Method
- 패러프레이징을 위하여 pairwise discriminator을 사용한 encoder-decoder기반으로 text representation을 제안한다.
- 이는 seq2seq의 확장 버전
3.1 Overview
- 입력 문장:
- 생성해야할 문장:
- 총 M쌍:
- 여기서 L과 T는 고정된 길이는 아니다.
- X와 Y가 각각 패러프레이지를 하는 것이다.

- 3가지 step이 있다
- Encoder는 LSTM으로 구성
- Decoder도 LSTM로 구성
- Discriminator는 encoder와 파라미터를 공유한 것
- 뒤의 fully connected layer도 있긴한거 같은데 논문에서는 언급안함.
- 여기서 discriminator을 다른 parameter을 안쓴 것은 local loss와 global loss로 학습하면서 embedding을 학습하기 위함이다.
- 이 효과가 좋다고 주장하는 것
- 이 text embedding은 sentiment analysis와 같은 다른 task에도 사용할 수 있다.
- 생각해보면, 생성+specific task로 학습하는 것이 specific task에 더욱 효과적일 수도 있겠다.
- Test time에서는 encoder와 decoder만을 이용해서 생성하는 것
3.2 Encoder-LSTM
- 입력 문장
- One-hot encoding을 vector 표현인 word embedding
로 표현
- 표현을 할 때는 embedding matrix가 아니고 여기서는 Temporal CNN을 사용한다.
- Temporal CNN은
함수로 표현을 하고
는 temporal CNN의 parameters이다.
- 참고로 TCN은 다음의 그림과 같다.
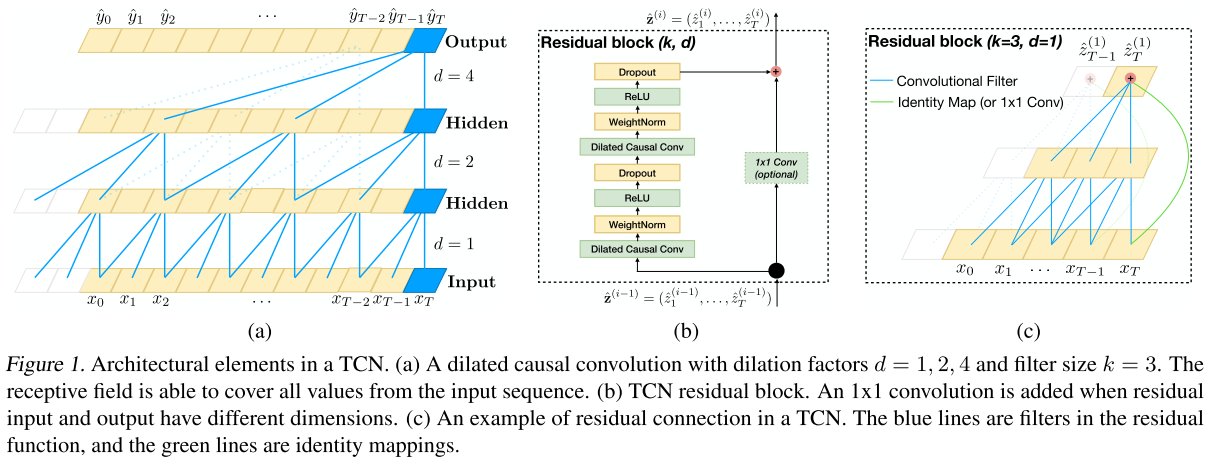
- 그 다음
- L번째(마지막) 단어에서의 hidden state
가 문장 전체의 semantic represetation을 표현하는 것이고 이것을 condition으로
단어들을 생성한다.
- Question sentence encoding feature:
는 LSTM을 통과한 것의 결과이다.
- LSTM의 함수는
료 표현하고
은 LSTM의 weights이다.
3.3 Decoder-LSTM
- Input sentence의 embedding
와 같은 condition으로 token을 예측한다.
는 step t에서의 hidden state다.
의 조건으로 만들어지는 것
- 즉 encoder의 출력과 이전 step의 hidden state을 이용하여 현재 step을 예측하는 것
- 생성되는 문장 feature은
이다.
- 이는
함수을 이용하여 parameterized 되어 있는 LSTM으로 얻어진다.
는 LSTM의 weights
는
으로부터 예측되는 question tokens이다.
,
은 START와 STOP의 special token이다.

- 즉 X가 encoder에 들어와 출력
- zero vector이런거 대신 쓰는 개념인 듯
- 약간 내용이 이상한데 위에서는
- 어찌되었든 d-1이든
- 그리고 여기서도 TCN을 통과시키고 teacher-forcing 개념으로 predict한 다음 Loss을 계산하는 식
3.4 Discriminative-LSTM (번역)
- Discriminative-LSTM의 목표는 그림 2와 같이 예측 된 문장 포함 fpi 및지면 진실 문장 포함 fgi를 구별 할 수 없게 만드는 것입니다.
- 여기서 우리는 π를 공유 인코더로 전송합니다 fgi를 얻기위한 LSTM. 판별 기 모듈은 생성 된 사실과 실제 진실의 문구 사이의 손실 함수를 추정합니다.
- 일반적으로 판별 기는 이진 분류기 손실이지만 여기서는 반복 신경망 (LSTM)의 마지막 숨겨진 상태에 작용하는 (Reed et al., 2016)과 유사한 전역 손실을 사용합니다.
- 이 손실의 주요 목표는 생성 된 패러 프레이즈 임베딩을 그라운드 트루 패러 프레이 임베드에 더 가깝게하고 다른 그라운드 트러스트 패러 프레이 임베딩 (배치의 다른 문장)에서 멀어지게하는 것입니다.
- 여기에 우리의 판별 기 네트워크는 생성 된 임베딩이 더 나은 패러 프레이즈를 재현 할 수 있도록합니다.
- 우리는 로컬 손실 (크로스 엔트로피)을 최소화 할뿐만 아니라 글로벌 손실을 최소화하는 임베딩 학습을 시행하기 위해 인코더 네트워크와 판별 변수를 공유하는 아이디어를 사용하고 있습니다.
3.5 Cost function

4 Experiments
- 생략





5 Conclusion
- 이 논문에서 우리는 한 쌍의 discriminator가 있는 순차적인 인코더 디코더를 사용하여 sentence embedding하는 것을 제안했다.
- 우리는이 sentence embedding 방법을 실험하여 구문 분석 및 감정 분석을 수행했습니다.
- 우리는 또한 쌍별 판별 기가 NLP 작업에 대한 이전의 최첨단 방법을 능가한다는 것을 정당화하는 실험 분석을 제공했습니다.
- 우리는 또한 방법에 대한 절제 분석을 수행했으며, 우리의 방법은 BLEU, METEOR 및 TER 점수 측면에서 이들 모두를 능가합니다.
- 우리는 이것을 다른 텍스트 이해 과제로 일반화하고 비전 영역에서 동일한 아이디어를 확장 할 계획입니다.
Reference
댓글
댓글 쓰기