NL-088, Cloze-driven Pretraining of Self-attention Networks (2019-EMNLP)
◾ Comment
- 이 논문을 보게 된 것은 NER task의 어떤 데이터세트에서 1등이길래 본 것인데, pretraining 논문이었다.
- 몰랐던 이 논문은 딱 보고 든 생각은 BERT에 가려진 비운의 논문의 느낌이다.
- 그래도 인용수가 58로 꽤 되고 Facebook에서 나와서 좀 읽어진 논문 같다.
- 이 논문의 주장의 끝은 많은 데이터로 pretraining을 했을 때 높은 성과를 낸다는 것이고 이 논문에서도 직접 BERT와 연구가 많이 겹친다고 언급을 한다.
- 하지만 억셉이 되었으니 다행이고 학습 방식은 BERT와 조금 다르다.
- 모델 학습 과정을 보면
- cloze style 학습이지만 BERT와 다르게 MASK 토큰은 안쓰고 가장 근접한 왼쪽 오른쪽 token의 query token을 결합하여 사용 (sum or concat)
- 또한 모델은 ELMo처럼 단일방향으로 2개를 사용하는데
- word emb + position emb -> Bi-Transformer 2개로 (왼->오, 왼<-오) representation을 구한다.
- ELMo와는 다르게 각각 학습이 아니고 한꺼번에 학습하고 transformer을 썼다는 점.
- Word embedding
- CNN vs BPE
- CNN이 약간 성능이 좋다는 것 같지만 큰 차이는 없고 BPE가 파라미터가 더 많지만 학습은 빠르다고 한다.
- CNN embedding은 Kim 방식의 char emb을 활용해서 단어 표현을 만들어내는 식인 것 같다.
- Fine-tune
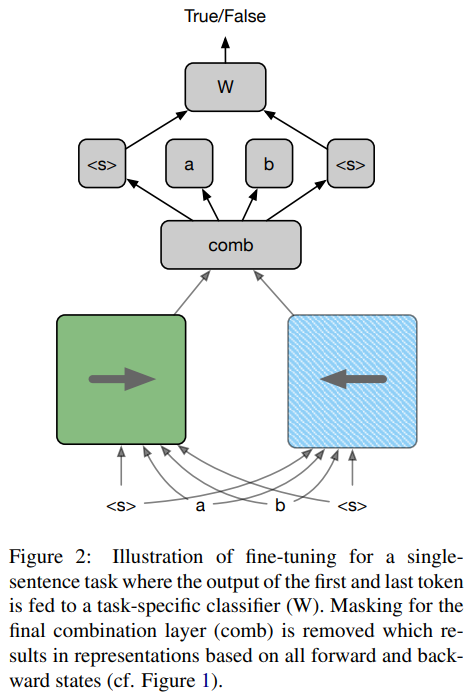
- pre-train과 다르게 special token <s>을 활용하는 방법이다. (그림 2참고)
- 참고로
- layer-normalization이 기존의 Transformer과 다른 것에 대해서 언급을 한다. (PLATO-2 정리 참고)
- FNN이전에 normalization을 하는 것인 pre-normalization을 수행하게 된다.
0. Abstract
- 우리는 bi-directional transformer 모델을 사용하는 새로운 모델을 제시하고, 이 모델은 다양한 NLU 문제에서 높은 성능 향상을 얻는다.
- 우리의 모델은 cloze-style word reconstruction task을 해결하고, 이 문제의 각 단어는 제거되고 주어진 나머지 텍스트로부터 예측하게끔 한다.
- BERT의 masked LM 학습과 다른 것인가?
- 실험들은 BERT 모델에서 소개되어 구성된 벤치마크들뿐만 아니라 GLUE, NER의 SoTA에비해 높은 성능차익을 얻는다.
- 우리는 또한 여러 요소들인 효과적인 pretraining, 데이터 도메인과 사이즈, 모델 용량, cloze objective의 다양함에대해 자세한 분석을 한다.
1 Introduction
- LM 모델 pretraining은 NLU의 여러 챌린지 문제들에서 중요한 성능 향상을 보여줘왔다.
- 그러나, 기존의 연구들은 unidirectional (left-to-right) LM 모델들과 bi-directional (both left-to-right and right-to-left) 모델들을 사용하였다.
- 각 방향은 독립적인 손실 함수로부터 학습된다.
- 이 논문에서는, 우리는 large language-model-inspired self-attention cloze model의 두 방향을 joint하게 pretrain하면서 성능 차이를 보여준다.
- Our bi-directional transformer architecture predicts every token in the training data (Figure 1).

- 우리는 cloze-style 학습 objective을 소개함으로써 모델이 왼-오와 오-왼 context representations가 주어졌을 때 중앙 단어를 예측하게끔한다.
- 우리의 모델은 masked self-attention 구조의 forward와 backward states을 분리해서 계산하며 이것은 LM와 비슷하다.
- 네트워크의 탑에서, forward와 backward states은 joint하게 결합되어서 중앙 단어를 예측한다.
- 이 접근 방식을 사용하면 단어를 예측할 때 두 컨텍스트를 모두 고려할 수 있으며 모델이 높은 likelihood(가능성)을 할당하지 않는 경우 학습 세트의 모든 단어에 대해 손실이 발생할 수 있습니다.
- GLUE 벤치마크에서의 실험들은 각 테스크의 SoTA보다 강한 이득을 보여주며, GPT의 RTE보다 9.1 포인트 게인을 획득한다.
- 이러한 개선사항은 동시에 개발 된 BERT 사전 훈련 접근 방식 (Devlin et al., 2018)에 의해 달성된 것에 약간 뒤처져 있지만 다음 섹션에서 자세히 설명합니다.
- 또한 pretrained representations 위에 NER 및 constituency parsing 분석을 위한 작업별 아키텍처를 쌓고 두 작업 모두에 대해 새로운 SoTA을 달성 할 수 있음을 보여줍니다.
- 우리는 이러한 결과에 대해 더 잘 이해하기위해 실험분석을하여 다음을 보여준다.
- (1) cross sentence pretraining is crucial for many tasks;
- (2) pre-training continues to improve performance with up to 18B tokens and would likely continue to improve with more data; and finally
- (3) our novel cloze-driven training regime is more effective than predicting left and right tokens separately.

2 Related work
- ELMo
- GPT
- BERT
- 그들의 작업과 우리의 작업 사이에는 상당한 겹침이 있지만 중요한 차이점도 있습니다.
- 우리 모델은 시퀀스의 모든 단일 토큰을 예측하는 양방향 변환기 언어 모델입니다.
- BERT는 또한 전체 입력에 액세스 할 수있는 트랜스포머 엔코더로, 양방향으로 만들지 만이 선택에는 특별한 훈련 체계가 필요합니다.
- 특히 노이즈 제거 자동 인코더와 유사한 마스킹 된 입력 토큰의 하위 집합 예측과 다음 문장 예측 작업 사이에서 멀티 태스킹을 수행합니다.
- 이에 비해 우리는 모델이 모든 주변 토큰에 대해 입력 문장의 각 토큰을 예측하도록 요구하는 단일 손실 함수를 최적화합니다.
- 우리는 모든 토큰을 훈련 대상으로 사용하므로 문장의 하위 집합이 아닌 모든 단일 토큰에서 학습 신호를 추출합니다. (즉 MASK 토큰만 학습하는 개념이 아니란 것)
- BERT는 다음 문장 예측 작업을 통해 문장 간의 종속성을 캡처하고 두 문장의 토큰을 구별하는 입력 마커를 사용하여 문장 쌍의 학습 예제를 구성하도록 사전 학습을 조정합니다.
- 우리의 모델은 학습 예제를 최종 작업 데이터와 유사하게 조정하지 않고 학습 중에 노이즈 제거 작업을 해결하지 않기 때문에 고전 언어 모델과 유사하게 학습됩니다.
- 마지막으로, BERT와 Radford et al.(2018)는 BooksCorpus(Radford et al., 2018) 또는 BooksCorpus(Devlin et al., 2018)와 추가적인 Wikipedia 데이터(Devlin et al., 2018) 중 하나의 데이터 소스만을 고려하는 반면, 우리의 연구는 다양한 양의 훈련 데이터와 다른 데이터 소스의 효과를 약화시킨다.
3 Two tower model
- 우리의 cloze model은 n개의 tokens t1, . . . , tn을 가지는 문장의 p(ti |t1, . . . , ti−1, ti+1, . . . , tn) 확률분포를 표현한다.
- 여기에는 두 개의 self-attentional towers가 각각 N개의 blocks으로 쌓여있다.
- the forward tower operates left-to-right and the backward tower operates in the opposite direction.
- 토큰을 예측하기 위해, 우리는 두 개의 towers의 표현을 결합하여 아래에서 자세히 설명한다.
- 이 때, 어떤 representation에도 현재 대상 토큰에 대한 정보가 포함되지 않도록 주의 합니다.
- forward tower은
토큰의 representation을 i번째 layer에서 이전의 layer들의 forward representation인
을 기반으로 self-attention을 통하여 계산한다.
- backward tower은 반대 방향인
으로부터
representation을 계산한다.
- 길이가 고르지 않은 examples를 일괄 처리하면 towers 중 하나가 처음에 컨텍스트가 없을 수 있습니다.
- 우리는 self-attention 메커니즘이 수반할 수있는 extra zero state를 추가하여이 문제를 처리합니다.
- zero-padding?
- 우리는 학습 코퍼스에서 발생하는 개별 example에 대해 pretrain 한다.
- News Crawl의 경우 이것은 개별 문장이며 Wikipedia, Bookcorpus 및 Common Crawl는 paragraph 길이입니다.
- Sentences are prepended and appended with sample boundary markers <s>.
3.1 Block structure
- blocks의 구조는 Transformer의 구조를 따른다.
- 각 구조는, 두 개의 sub-blocks으로 구성된다.
- the first is a multi-head self-attention module with H = 16 heads for which we mask out any subsequent time-steps, depending on if we are dealing with the forward or backward tower.
- The second sub-block is a feed-forward module (FFN) of the form ReLU(W1X + b1)W2 + b2 where W1 ∈ R(e×f), W1 ∈ R(f×e).
- Vaswani와 달리, 우리는 layer normalization을 self-attention을 하기 전에 적용하고 FFN blocks을 그 후에 적용한다.
- 이것이 학습에 더 효과적인 것을 발견한다. (GPT와 같은 pre- 방법인 듯)
- Sub-blocks are surrounded by a residual connection (He et al., 2015).
- Position는 fixed sinusoidal position embeddings을 통해 인코딩되며 단어 기반 모델에 대한 입력 토큰의 character CNN 인코딩을 사용합니다 (Kim et al., 2016).
- Input embeddings은 두 타워간에 공유됩니다.
3.2 Combination of representations
- forward and backward representations은 두 towers으로부터 계산되고 ablated word을 예측하는데 결합된다.
- 그들을 결합하기 위해, 우리는 self-attention 모듈을 사용하고 이는 FFN block을 따른다.
- FFN block의 출력은 V classes로 project된다.
- V는 vocab의 type을 나타낸다.
- 모델이 token i을 예측할 때, attention 모듈에 대한 입력은 forward states는
...
이고 backward states는
...
이다.
- 여기서 n은 시퀀스 길이고 L은 layers의 갯수이다.
- 우리는
와
을 마스킹을 한다.
- 이것은 코딩적으로 말하는 개념인 듯
- 즉 attention 라이브러리를 쓸 때, 양방향을 하게끔 되어있으니, 실제로 attention안하는 부분은 masking 처리를 해야한다.
- 토큰에 대한 attention query는
- 이 부분이 BERT와는 다른 점인데
- 원래 BERT에서는 예측하려는 토큰은 [MASK] 토큰이고 이것의 query을 사용하면 되는데
- 여기서는 [MASK] 토큰이 아닌, 그냥 바로 예측하는 것이기 때문에 forward와 backward 가장 근접 토큰의 query을 결합하여 사용하겠다는 것이다.
- base model의 경우, 우리는 두 representation을 더하고 더 큰 모델에서는 그들을 concat한다.
- keys와 values는 forward와 backward states을 기반으로하여 attention 모듈에 넣어주게 된다.
- 요약하면 이 모듈은 현재 대상 토큰을 둘러싼 전체 입력에 대한 정보에 접근할 수 있습니다.
- 학습에서는, 우리는 이 방법으로 매 토큰을 예측한다.
- 이 모듈의 출력은 ouput classifier에 넣어서 중앙 토큰을 예측하게 된다.
- 우리는 word based models에서는 adaptive sofrmax을 사용하고 BPE based models에서는 regular softmax을 사용한다.
- 학습 때, 현재 target word에 대한 정보를 포함하는 모든 states는 final self-attention block에서 마스킹되지만 우리는 이것이 fine tuning 할 때는 비효율적이라는 것을 알아냈다.
- 이는 모델이 토큰 자체를 포함하여 전체 컨텍스트에 액세스 할 수 있도록 허용하므로 NER와 같이 각 토큰에 레이블을 지정하는 작업의 경우 특히 그렇습니다.
- forward 기준으로 생각하면 target token을 기준으로 뒷 부분의 token을 attention에 사용안하고 pretrain 학습을 하게 된다.
- 근데 finetune때는 이와 똑같이 하기 보다는, 그림 2와 같이 하겠다는 것이다.
- 예로 "나의 회사는 애플이다."와 같은 문장에서 NER task을 한다고하자.
- "애플"이 target word일 때
- "나의 회사는 <s>애플<s>"을 forward 입력으로보고 애플 뒤의 <s>토큰과
- "<s>애플<s>이다."을 backward 입력으로보고 애플 앞의 <s>의 토큰을 결합하여 예측하겠다는 것이다.
4 Fine-tuning

- Classification and regression tasks.
- Structured prediction tasks.
- No Masking.
- Optimization.
5 Experimental setup
5.1 Datasets for pretraining
- Common Crawl.
- News Crawl.
- BooksCorpus + Wikipedia.
5.2 Pretraining hyper-parameters

6 Results
6.1 GLUE
- 결과를 보면, CNN과 BPE 뭐가 딱 좋은 것 같지는 않지만, CNN이 좀 더 낫다는 거 같고 다른 실험 표에서도 CNN 임베딩을 사용한다.

- 표 2는 우리 접근 방식의 세 가지 구성에 대한 결과를 보여줍니다 (표 1 참조).
- BPE 모델은 CNN 모델보다 더 많은 매개 변수를 갖지만 전체적으로 더 잘 수행되지는 않지만 학습하는 것이 더 빠릅니다.

6.2 Structured Prediction
6.2.1 Named Entity Recognition
- 이 논문의 시작이 애초에 NER 쪽에서 보고 들어온 것이고 실제로 성능이 BERT보다 좋게 나오기는 하는것을 표에서 볼 수 있다.
- 근데 dev에서는 거의 비슷한 수준이라고 보여진다.


6.2.2 Constituency Parsing
- ELMo만 사용하는 것과 ELMo+CNN Large 임베딩 사용하는게 효과를 얻으려면 fine-tune을 해야한다는 결과이다.
- 근데 constituency parsing task의 이해가 낮아서 그런 거겠지만 어떻게 fine-tune 을 안하고 합쳐서 한다는 것이지..?

- 또한 Penn Treebank 선거구 구문 분석에 대한 구문 분석 F1을보고합니다.
- 우리는 현재의 최첨단 아키텍처를 채택했습니다 (Kitaev and Klein, 2018).
- 우리는 다시 분석 인코더에서 학습률과 계층 수에 그리드 검색을 사용하고 언어 모델 미세 조정에 8E-04, 구문 분석 모델 매개 변수에 8E-03, 인코더에 2 개의 계층을 사용했습니다.
- 결과를 표 4에 나타냈다. 여기서는 ELMo 임베딩을 사용했던 이전의 기술 수준에 비해 이득을 얻으려면 미세 조정이 필요합니다.

6.3 Objective functions for pretraining

6.4 Domain and amount of training data
- 결과들을 보면 학습 데이터의 토큰이 높아질 수록 성능이 높아지는 것을 보여준다.
- 2.25B~9B가 겅체되는 기간이기는 하다.




7 Conclusion
- 우리는 bi-directional transformer 모델을 기반으로 pretraining 구조를 소개하고 학습 데이터에서 각 토큰을 예측한다.
- 모델은 cloze-style objective으로 학습되고 왼,오 context가 주어질 때 중앙 단어를 예측한다.
- GLUE 벤치마크에 대한 결과는 GPT에 비해 높은 게인을 얻었고 모델 스택을 사용한 실험은 parsing 및 named entity recognition을 위한 새로운 최첨단 성능 수준을 설정했습니다.
- 우리는 이러한 결과를 더 잘 위해하기 위해 광범위한 분석을 하여서 다음을 보여준다.
- (1) cross sentence pretraining is crucial for many tasks;
- (2) pre-training continues to improve performance up to 18B tokens and would likely continue to improve with more data; and finally
- (3) our novel cloze-driven training regime is more effective than predicting left and right tokens separately.
- In future work, we will investigate variations of our architecture.
- 특히, 우리는 매개 변수 수를 늘리지 않고 훨씬 더 깊은 모델을 훈련할 수 있도록 two towers의 parameter를 공유하는 초기 성공을 거두었습니다.
Reference
댓글
댓글 쓰기