NL-104, Unsupervised paraphrase generation using pre-trained language models (2020-Preprint)
◼️ Comment
- 논문 형식보니 ICLR? Neurips 등에서 떨어졌을 거 같은데..
- 논문의 제목처럼 LM을 만들때와 비슷하게 단순히 코퍼스만 필요하다.
- 이 부분이 상당히 매력적인 방법이라고 생각된다.
- 사실 이런 접근은 이전에도 있었던 거 같지만, 처음 보는 것일 뿐이고 pre-trained LM을 활용한 실험이기 때문에 성능이 좋아질만한거 같기도 하고.. ㅎㅎ
- 학습 방식을 보면 상당히 간단하다.
- (기존 S) 나는 멋진 외모를 가지는 홍길동이야.
- (변형 T) 나는 외모를 가지는 홍길동
- T->S로 재구성하도록 모델 학습 (S에 랜덤으로 단어 20%를 동의어로 대체)
- 이렇게 재구성 하도록 학습한 모델을 이용해서 paraphrasing을 한다는 것이다.
- 그렇다면 변형 T는 어떻게 만드는 것일까?
- stop words(불용어)를 삭제해서 만든다고 한다.
- 인퍼런스시, 문장을 생성할 떄는 top-k sampling으로 10개 문장을 생성한다.
- 그리고 Sentence Transformers Library [25]을 이용해서, 기존 문장과 cosine 유사도가 0.75 이하는 버린다고 한다.
- BERTscore을 써도 될 것 같은데란 생각이 듬
- 자동평가시 기존의 unsupervised 보다 좋고, supervised와 비슷한 성능을 낸다고 한다.
- 평가할 때는, gold reference가 있는 QQP 데이터를 사용한다.
- 사람 평가시, gt와 같은 뜻인지를 물어봤는데 75.5% 정도라 하니 나름 효과적인 것 같다.
- 또한 다운스트림 테스크에 (SST) 패러프레이징을 통한 데이터 증가시 성능 효과가 입증이 된다.
- 사실 이 부분은 약간 의아한게, 베이스라인 모델에 비해 성능이 좋아진 건 OK
- 근데 베이스라인을 BERT or GPT와 같은 모델로 하면 성능이 향상 안될 것 같다.
- 왜냐하면, 이 모델은 결국 LM와 같은형식으로 데이터 증강을 시킨 것이기 때문이고 애초에 다운스트림 테스크에 GPT을 이용하면 비슷한 거 아닌가? 싶음
- (조금다르지만) 개인적으로 실험한 것에서도 느낀거와 같이
- 모델의 학습 epochs의 수가 correctness와 diversity 사이의 trade-off가 있다고 한다.
0 Abstract
- Large scale Pre-trained Language Models은 다양한 자연어 테스크에서 매우 강력한 것임이 증명되었다.
- OpenAI’s GPT-2는 유창하고, well-formulated, 문법적으로 일관성있는 텍스트를 생성하고 phrase 완성의 능력으로 유명하다.
- 이 논문에서, 우리는 GPT-2의 생성 능력을 활용해서 어떠한 labelled data으로부터의 supervision없이 paraphrase을 생성한다.
- 우리는 얼마나 다른 supervised와 unsupservised와 결과를 비교하고 classification과 같은 다운스트림 테스크들에서 data agumentation을 위한 paraphrase의 효과도 조사한다.
- 우리의 실험들은 우리의 모델로 생성된 paraphrases들이 좋은 퀄리티이고 다양하고 data agumentation을 사용할 때, 다운스트림 테스크 성능을 향상시킴을 보여준다.
1 Introduction
- Paraphrasing은 data augmentation, data curation, intent mapping, semantic understanding을 포함하는 광범위한 어플리케이션을 가지는 NLP에서 잘 알려진 문제이다.
- Paraphrasing은 synthetic 데이터를 생성하여 학습을 위한 기존의 부족한 데이터세트를 증강시키고, classification과 같은 다운스트림 테스크들 성능을 강화시킨다.
- 또한 기존의 데이터세트를 좀 더 변형을 주도록 확장시킬 수 있고, 그래서 패러프레이징을 추가함으로써 언어의 가변성 때문에 좀 더 일반화가 된다.
- 패러프레이징을위한 supervised 접근법은 domain specific parallel data의 부족으로부터 고통을 겪는다.
- paraphrasing을 향한 unsupervised 접근법은 bilingual parallel data corpus가 여전히 필요한 기계번역에 크게 의존한다.
- 또한, back-translation을 기반으로하는 기계번역의 성능은 기계 번역 시스템을 구성하는 성능에 의존적이다.
- supervised 접근법과 기계번역을 기반으로하는 패러프레이징은 모두 인퍼런스 동안, 큰 도메인 변경이 있을 때 고통받는다. [Six challenges for neural machine translation.]
- GPT-2은 언어생성에서 예외적이다.
- 이는 이전에 주어진 모든 토큰들의 시퀀스에서 다음 토큰을 예측한다.
- 이는
을 최적화한다.
- GPT-2의 pre-trained 버전은 어떠한 목표없이 bland text을 생성한다.
- Source S을 조건으로 Target T을 생성하도록 모델을 만듬으로써, GPT-2의 언어 생성은 의미있는 text을 생성하도록 활용될 수 있다.
- 이 논문에서, 우리는 GPT-2을 사용해서 새로운 unsupervised paraphrasing 기술을 제안한다.
- unsupervised 접근법으로써, 모델은 직접 domain specific 독립 문장들에대해 학습될 수 있고 domain 이동으로부터의 고통없이 paraphrases을 생성한다.
- 즉 back-translation 등을 안하고 걍 단일 언어 코퍼스 자체에서 학습가능하다는 뜻 같음
- 우리는 corrupted 입력으로부터 문장을 재구성하는 테스크로써 unsupervised paraphrasing을 형식화한다.
- 문장으로부터, 우리는 stop words을(불용어) 누락하여 corrupted 문장을 만들고, 이를 Source S로하고 originals 문장을 Target T로 사용한다.
- We use GPT-2 to generate the Target sentence given Source. i.e P(T |S)
2 Related Work
- textual paraphrasing의 테스크는 NLP 연구에서 높은 관심을 가지고 있고 여러 접근법을 이용하여 해결해왔다.
- [3], [4], [5]와 같은 패러 프레이징에 대한 초기 접근 방식은 대부분 언어 구조를 기반으로했습니다.
- 지난 몇 년 동안 Seq2seq 작업 [6] [7] [8]으로 paraphrases 생성을 프레이밍하는 작업이 많이있었습니다.
- 패러레이징은 또한 reformulations을 통합하여 학습을 더욱 강인하게 만들어 [9] 및 [10]의 Question answering을 개선하는 수단으로 탐색되었습니다.
- Deep generative 모델과 패러 프레이징을위한 discrete latent 구조 [11]도 탐색되었으며 [12] 소스 문장에서 인코더와 디코더를 모두 조건화하여 VAE 및 Seq2Seq 모델의 접근 방식을 결합한 방법을 제안했습니다. (Else 방법, [13] 및 [14] 강화 학습을 포함합니다.)
- [15]는보다 다양하고 강력한 변형을 생성하기 위해 여러 generators를 사용하는 것을 제안하는 반면, [16]은 특정 target syntactic form을 따르는 의역 생성을 조사합니다.
- Unsupervised paraphrasing은 패러 프레이징 관련 연구 작업에서 많은 속도를 내고 있습니다.
- [17] 및 [18]과 같은 접근 방식은 learned latent space에서 paraphrases 을 샘플링하기 위해 variational autoencoders를 사용합니다.
- [19]는 VectorQuantized AutoEncoders [20] 기반 모델을 사용하여 입력에서 의미 적으로 더 가까운 문장을 생성하면서 더욱 다양하게 생성 할 수 있다고 주장합니다.
- [21] stochastic searching 문제로 패러 프레이징을 공식화하고 비지도 검색 알고리즘, 시뮬레이션 어닐링을 포함하여 패러 프레이즈를 생성합니다.
- 이러한 비지도 접근 방식과 우리의 접근 방식의 차이점은 우리는 대규모 사전 훈련 된 언어 모델의 힘을 탐구하는 것을 목표로합니다.
- 이 모델은 학습 된 말뭉치의 크기와 폭으로 인해 다운 스트림 작업에서 매우 잘 수행됩니다.
- 이러한 모델은 주로 컨텍스트를 이해하여 다음 단어를 예측하는 방법을 효과적으로 학습하는 방식으로 학습되므로 paraphrasing problem setup에서 그 효과를 탐색합니다.
- 이를 위해 사전 훈련 된 대형 언어 모델의 패러 프레이징 사용과 관련된 유일한 다른 작업은 [22]에 있습니다.
- [22]: Paraphrasing with large language models
- 우리의 작업은 [22]에서 제안한 아키텍처와 유사하지만, 레이블이 지정된 패러 프레이징 데이터 세트에서 GPT-2를 미세 조정하기 때문에 취하는 접근 방식이 완전히 다릅니다.
- 대조적으로 모델을 학습하여 완전히 감독되지 않은 상태로 수행하는 것을 목표로합니다.
- 레이블이 지정된 의역 데이터에서 배우는 것보다 재구성 작업에 더 많이 있습니다.
- [22]의 평가도 상당히 다릅니다.
- 우리는 철저한 정량적 평가를 실행하고 동일한 데이터 세트에서 supervised 및 unsupervised 방법을 포함한 다른 방법의 standard metric numbers을 리포트하여 비교한다.
- 여기서 paraphrasing 품질, 다양성 및 정확성에 대한 평가와 함께 그 효과를 더 잘 보여줍니다.
3 Methodology
3.1 Paraphrase Generation using GPT-2
- Paraphrasing은 reference 문장 P에 대해 Target 문장 T을 생성하는 기술이다.
- 이 때 새롭게 생성된 T는 의미적으로 P와 비슷하다.
- GPT-2은 auto-regressive 모델로 많은 벤치마크 테스크들에서 SoTA 결과를 달성해왔다.
- 이는 최대 1.5 Billion parameters을 가지고 있고 인터넷 텍스트의 40GB에서 다음 단어를 예측하도록 심플하게 학습되었다.
- 우리는 Huggingface Transformers 라이브러리를 활용하고 GPT-2 모델을 paraphrases을 생성하는 문장 재구성 테스크에서 finetune한다.
3.2 Data Preparation
- 우리는 Paraphrase generation을 향한 unsupervised 접근법을 취하고 그래서 패러프레이징을 위한 어떠헌 parallel 코퍼스도 활용하지 않는다.
- 대신 우리는 sentence re-construction task을 위한 dummy 데이터세트를 만든다.
- 우리는 입력 문장에서 모든 stop words을 제거하여 corrupt 하고, 더 나아가 우리는 랜덤으로 남아 있는 단어 20%을 shuffle하고 replace한다.
- 우리는 corrupted 문장을 source sentence S로 하고 original uncorrupted sentence을 target T로 한다.
- Goal is to reconstruct the sentence T from the keywords/corrupted sentence S, P(T |S).

- Our stop word set has total of 252 words.
- Source S 형태의 문장에서 stop words을 제거하고나서, 우리는 모델이 다양한 paraphrase을 생성할 수 있도록 단어들의 20%을 shuffling한다.
- 모델이 문장을 재구성할 때, original 문장에 없는 새로운 단어들을 가지게 하기 위해, 단어들의 20%는 랜덤으로 syn-net을 사용한 동의어로 교체된다.

3.3 Model Fine-tuning for Paraphrase Generation
- 우리는 pre-traeind GPT-2 체크포인트를 활용하고 더 나아가 문장 재구성 테스크에 모델을 finetune한다.
- 우리는 input 시퀀스 X의 형태를 special symbol로 구분되게 Source와 Target 시퀀스를 concat한다.
- Let
- Source 시퀀스:
- Target 시퀀스:
- Special character [SEP]은 source tokens와 target tokens 사이에 추가되고 이것은 인퍼런스동안 promt 역할을 한다.
3.4 Candidate Paraphrase Generation and Scoring
- 주어진 입력 문장에서 한 개이상의 paraphrase을 생성하기 위해, 우리는 top-k sampling을 사용한다.
- 우리는 매 입력 문장에서 10개의 paraphrases을 생성하고, parphrased sentence을 R이라 부른다.
- 우리는 original sentence T와 같거나 몇 개의 characters만 다른 것은 제거한다.
- paraphrase가 입력 문장 T와 의미적으로 유사함을 보장하기 위해, 우리는 Sentence Transformers Library [25]으로 Sentence T와 Prarphrase R을 embed하여 consine 유사도를 구한다.
- 우리는 이러한 paraphrases중 threshold 0.75을 넘는 것만 유지하여 valid candidate을 구성하고 그래서 의미가 보존되도록 한다.
- 지금까지, candidate set은 valid candidate set을 의미한다.
- paraphrases의 몇 예제들은 테이블 1에서 볼 수 있다.


4 Experiment (번역)
4.1 Dataset
- 교육 및 평가 목적으로 Quora Question Pair (QQP) dataset1을 사용합니다.
- QQP 데이터 세트에는 40 만 개의 레이블이 지정된 예제가 있으며 그 중 140k 예제는 실제 의역이며 레이블이없는 문장 쌍은 300k입니다.
- QQP 데이터 세트의 각 항목에는 (question1, question2, is_duplicate) 필드가 있습니다. 여기서 question1 및 question2는 문장이고 is_duplicate는 이들이 의역인지 여부를 나타냅니다.
- 14 만 개의 실제 의역 문장 쌍 중에서,보다 쉬운 비교를 위해 [21]과 [18]에서 수행 된대로 테스트 세트에 대해 무작위 30k 문장 쌍을 취합니다.
- 우리는 레이블이있는 나머지 370k와 레이블이없는 300k 샘플에서 모든 고유 한 question1을 가져와 총 523010 개의 고유 한 문장을 제공합니다.
- 우리는 훈련을 위해 463010 문장을, 문장 재구성 작업을 검증하기 위해 60000 문장을받습니다.
- 데이터 증대를위한 패러 프레이징 사용의 성능 향상을 입증하기 위해 6920 개의 학습 예제와 1821 개의 테스트 예제가있는 [19]에서 수행 된대로 Stanford Sentiment Treebank (SST-2) 데이터 세트 [26]를 사용합니다.
4.2 Training
- 우리는 우리의 모델을 345M parameters을 가지는 GPT-2 medium로 초기화한다.
- 모델은 GPT-2가 [1]에서 훈련 된 것과 같은 방식으로 문장 재구성 작업에서 미세 조정됩니다.
- 검증 세트의 난이도는 early stopping를 수행하는 데 사용됩니다.
- 이 모델은 Nvidia V100 DGX 머신 1 대에서 2-5 Epoch 동안 미세 조정되며, Epoch 당 28 분이 소요됩니다.
4.3 Evaluation Metric
- We use different evaluation metrics to measure quality, correctness, diversity and usefulness of the generated paraphrases.
- Quality :
- We use ROUGE-L [27] and METEOR [28] for measuring the quality of generated paraphrase while BLEU-n calculates n gram overlap, ROUGE-L measures longest matching sequence, and it does not require consecutive matches but in-sequence matches that reflect sentence level word order.
- METEOR compares the texts using not just word matching, but stemming and synonym matching, which is more desirable to gauge in paraphrasing quality.
- Diversity :
- To measure the diversity of candidate paraphrases, we use self-BLEU from [29].
- Given set of paraphrase candidates for an input sentence, every candidate is picked once and others are used as references to compute BLEU score.
- And the average of all the BLEU scores computed for this candidate set is self-BLEU.
- A lower self-BLEU score indicates better diversity.
- Usefulness :
- Using paraphrases for data augmentation for a downstream task can answer questions such as how good/diverse are paraphrases and do they provide any signal that was not provided by the original sentence and hence improving the downstream task’s performance.
- We report % increment in performance of the downstream task.
- Correctness :
- Though we filter the paraphrase candidates using high threshold on cosine similarity, it doesn’t promise 100% correctness.
- To measure what percent of the generated paraphrases are semantically similar to input sentence, we make human evaluation of the model output.
4.4 Results
4.4.1 Quality and Diversity
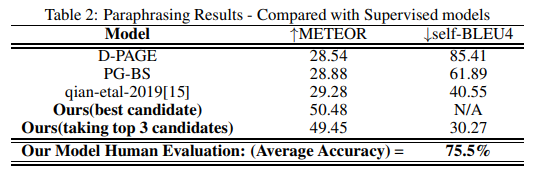
- 모든 30k 예제에 대해 QQP 테스트 세트에서 생성 된 의역 R과 question2 사이의 METEOR을 계산합니다.
- 우리는 후보 의역에서 최종 의역 선택과 관련하여 여러 실험을 수행합니다.
- 실험 중 하나에서 우리는 모든 candidates 중에서 best one을 선택하고, 두 번째 실험에서는 question2에 대한 각 candidate의 값을 계산하고 평균을 취합니다.
- 의역 후보 중 self-BLEU를 추가로 계산했습니다.
- 이 모든 값은 표 2에서 볼 수 있습니다.

- 우리는 우리의 결과를 감독 및 비 감독 방법과 비교합니다.
- 우리의 방법을 표 2에서 비교하는 선택적 감독 방법은 D-PAGE [30] 및 Beam-search (PG-BS)를 사용한 포인터 생성기 (PG-BS) [31] 및 [15]입니다.
- 표 2에 표시된 값은 이러한 모든 방법에 대해 [15]에 따라보고됩니다. 우리가 결과를 비교하는 비지도 방법은 VAE [17], CGMH [18] 및 UPSA [21]입니다.
- 표 3에 나와있는이 논문의 값은 [21]에서 가져온 것입니다.

- [21]에 사용 된 정확한 테스트 세트에 액세스 할 수는 없지만 [21], [18], [15]의 정확한 가이드 라인을 따르며 QQP 데이터 세트에서 140k 패러 프레이즈 중 임의의 30k 샘플을 취한다고 언급합니다.

4.4.2 Usefulness
- 다운 스트림 작업에서 의역의 유용성을 입증하기 위해 SST-2 및 TREC 데이터 세트에서 NB-SVM 및 Random Forest Classifier를 교육했습니다.
- 데이터 보강을 위해 의역을 사용하기 전과 후에 정확도의 백분율 변화를보고했습니다.
- 표 4는 [19]와 비교했을 때 성능 향상이 현저하다는 것을 보여줍니다.
- 기준 결과는 [19]와 일치하지 않지만 훈련 데이터를 제외한 % 증가를 측정하기 위해 데이터 증가 전후의 모든 설정을 동일하게 유지하므로 절대 숫자는 중요하지 않습니다.

- [19]란 패러프레이징과 이 논문 방법과 비교한 거같은데 왜 다른 모델로 실험했지?
- 이것만 보면 [19]는 이미 베이스라인이 성능이 높기 때문에 패러프레이징 효과가 작은 것이라 생각할 수 있을 거 같은데..?

4.4.3 Human Evaluation for Correctness: Higher[/Lower] BLEU does "not" mean better[/worse] Paraphrase
- BLEU score은 candidate text가 reference text와 얼마나 비슷한지를 n-grams가 겹치는 것을 보고 측정한다.
- 주어진 evaluation set의 paraphrase와 비교했을 때 example xi가 낮은 BLEU을 가진다면, 이것은 xi가 올바른 paraphrase가 아님을 의미하나 xi는 evaluation set의 reference sentence보다 다른 toknes의 set을 가진다는 것을 의미한다.
- self-BLEU가 diversity을 캡쳐하는동안, 우리는 human evaluation으로 correctness을 측정한다.
- 모델이 생성한 paraphrase sentence R과 ground truth paraphrase sentence(question2)을 갖는 QQP 데이터 세트에서 각각 100개의 예제를 포함하는 두 사람 evaluation set를 구성하고, 영어에 능통한 2명의 인간에게 R과 question2가 패러 프레이즈인지 여부를 표시하도록 요청했습니다.
- 쉽게 말해서, QQP를 테스트세트로 하고 생성 vs gt 가 비슷한지 물어봤다는 것
- 각 어노 테이터는 0 또는 1로 레이블을 지정하도록 요청 받았습니다.
- 여기서 Label = 0은 패러 프레이즈가 아님을 의미하고 Label = 1은 패러 프레이즈임을 의미합니다.
4.4.4 Takeaway
- 테이블 2는 우리의 모델이 METEOR 점수가 supervised 모델들보다 훨씬 높고, paraphrase의 퀄리티가 높음을 강조한다.
- 우리의 모델로 생성된 candidates 사이의 낮은 self-BLEU은 candidate sentences들이 다른 supervised methods로 생성된 candidate paraphrases들보다 좀 더 다양함을 가리킨다.
- 테이블 3은 ROUDE metric을 사용하여 Quora 데이터세트에서 더욱 다양한 모델과 함께 우리의 모델로 생성된 paraphrase의 퀄리티를 비교한다.
- 그리고 우리의 모델은 모든 unsupervised methods와 비교하여 좋고, supervised methods와 비교하여 매우 비슷하다.
- 우리 모델의 paraphrases의 human evaluation은 75.5%의 correct을 보여준다.
- 또한 다운 스트림 작업에서 data agumentation를 위해 paraphrase을 사용할 때 두 모델을 사용하여 두 작업의 성능 향상을 보여줌으로써 생성된 paraphrase가 쓸모없지않고 유용하다는 것을 보여줍니다.
- 마지막으로, 테이블 4에서, 우리는 SST-2 학습 데이터세트에서의 우리 모델을 이용한 데이터증가는 [19]에서 보여준 실험들과 비교하여 높은 gain을 보여준다.
5 Conclusion and Future Work
- 이 논문에서, 우리는 unsupervised paraphrasing 모델을 소개하여 좋은 qualityh, divers와 유용한 parphrase을 생성한다.
- 우리는 그들을 사용해서 다운스트림 테스크들의 학습 데이터를 증강하여 paraphrases의 유용함을 입증한다.
- 모델은 labelled 데이터를 필요로 하지 않기 때문에, 대부분의 감독 모델이 직면하는 도메인 이동 문제를 겪지 않고 모든 도메인에 속하는 독립적 인 문장에 대한 문장 재구성 작업으로 학습 할 수 있습니다.
- 문장 corruption 기술은 추가 탐색 및 향상으로의 여지가 많으며, 미래에는 우리는 좀 더 complex하고 정교한 방법으로 입력 문장의 corrupting을 탐구할 것이다.
- 그리고 이것은 생성된 paraphrases와 reconsturction에 관한 강임한에 대한 영향이 있다.
- 우리는 모델의 학습 epochs의 수가 correctness와 diversity 사이의 trade-off가 있음을 발견했고 우리는 여러 후속 실험들을 통해 더욱 조사하려고 한다.
Reference
댓글
댓글 쓰기