NL-113, Fine-grained Post-training for Improving Retrieval-based Dialogue Systems (2021-NAACL)
◼️ Comment
- 이 논문은 모델링에 초점이 아닌, post-training에 초점을 맞춘 것이다.
- post-training의 개념은 pre-training 2번째 스테이지 같은 개념으로 테스크에 맞는 pre-training이라 보면 된다.
- 따라서, 기본 pre-trained BERT에 도메인에 맞는 pre-training을 한번 더 하는 것에 초점을 맞춘다.
- 단, BERT을 학습할 때와 달리, 여러 방법을 연구한 논문이다.
- Post-training으로 다음과 같은 것들이 추가된다.
- 1) Maksed 토큰 예측할 때, 다이나믹 마스킹을 사용함.
- RoBERTa에서 사용한 것
- URC (아래의 것들을 합쳐서 하나의 loss로 만드는 개념)
- 2) NSP대신 SOP을 썼음.
- ALBERT에서 사용한 것으로, 토픽을 구분하는 것보다 발화간의 관계를 배우는 게 중요하기 때문에!
- 이를 4) 방법으로 SOP task을 만들어서 한다는 것.
- 3) 멀티 대화턴에서, short context-response으로 쪼개서 학습함.
- 사실 이 방법은 읽어보니, 다른 논문에서 data agumentation으로 적용해본 것인데, post-training으로 사용한 것이다.
- 그러면 post-training과 DA 두 개중에 어떤 사용이 좋을지를 테이블 6에서 보여준 것 같음.
- 4) utterance relevance classification라는 objective function을 제시함
- 이는 그림2에서 보여주는 것처럼, response가 단순히 binary처럼 0 또는 1로 분류하지 않고, 다음과 같이 3가지로 구분한다.
- correct response / random utterance / random utterance in 대화
- 즉, 이전에는 correct or random을 구분하는 개념이었지만, 여기서는 3번째로 대화속의 랜덤 발화까지 추가한 것이다.
- 이로써, 단순히 토픽만 같은 발화라고 적합하다고 고르지 않게끔 하는 것이다.
- 그외에 내용은 다양한 실험들과 위의 효과들의 입증을 보여준 것들이라고 보면 될 것 같다.
0 Abstract
- 검색기반 대화 시스템은 pre-trained LMs가 (BERT 포함) 사용될 때, 좋은 성능을 보여준다.
- multi-trun response selection에서, BERT는 context와 여러 utternaces와 response 사이의 관계를 학습하는데 집중한다.
- 그러나, 학습에서 이 방법은 context안의 각 대화 사이의 관계를 고려할 때, 불충분하다.
- 이로 인해, response을 선택하는데 필요한 context flow을 완전히 이해하지 못하는 문제가 발생한다.
- 이러한 이슈를 설명하기 위해, 우리는 새로운 fine0grained post-training 방법을 제안하고, 이 방법은 multi-turn 대화의 특성을 반영한다.
- 구체적으로, 모델은 대화 세션에서 짧은 context-response pair을 학습함으로써 utternace level interactions을 배운다.
- 게다가, 새로운 학습 objective을 사용함으로써 (utterance relevance classification), 모델은 대화 발화사이의 semantic relevance와 coherence을 이해할 수 있다.
- 실험 결과들은 우리의 모델이 3개의 벤치마크 데이터세트에서 의미있는 margins을 가지면 new SoTA을 달성한다.
- 이것은 fine-grained post-training 방법을 제시하여, respons selection task에서 높은 효과를 보여준다.
1 Introduction
- 사람과의 상호작용에서 자연스럽고 일관성있는 대화 시스템을 구성하는 것은 현재 매우 유명한 연구 토픽이다.
- 대화 시스템의 실행에는 두 가지 접근법이 있다.
- generation 기반 / retireval 기반
- 검색 접근법은 response candidates 사이에서 올바른 response을 선택하는데 초점이 있다.
- 초기의 멀티턴 RS (response selection)에서, Lowe (2015)은 RNN을 활용해서 대화 컨텍스트와 response을 매칭시키는 것을 제안했다.
- 나중에, attention mechanism의 출현과 함께, 멀티턴 RS 모델들은 attention 메커니즘을 제안해왔다.
- 최근에는, pre-trained LMs (BERT와 같은)이 다양한 RS 모델들에 적용되어왔고, 그들은 매우 좋은 성능을 보여줘왔다.
- 최근에, pre-trained LMs은 다양한 NLPs 영역에서 널리 사용되어왔다. (question answering과 대화 시스템과 같은)
- 가장 좋은 pre-trained LMs 중 하나는 BERT로 이것은 일반적인 도메인의 많은 코퍼스에서 pre-trained되고 특정 테스크에 fine-tuned되어 적용된다.
- BERT는 일반적인 데이터로 pre-trained되기 때문에, 성능은 도메인 특정 데이터에 post-training을 적용함으로써 향상될 수 있다.
- 몇 가지 이전의 연구들에서, 테스크에 fine-tuning 하기전에, 도메인 데이터를 학습하는 post-training 방법을 제안했었다.
- 이전의 연구들에서, 모델들은 도메인 특정 테스크 데이터를 사용해서 BERT와 같은 pre-training objectives으로 (masked language model, next sentence prediction) post-train되었다.
- 대화에 적합한 새로운 post-training 방법을 개발하기위해, 우리는 간단하만, 강력한 fine-grained post-training 방법을 제안한다.
- 새로운 post-training 방법은 2가지 학습 전략을 가진다.
- 1) 첫 번째는 전체 대화를 여러 개의 short context-response pairs로 나누어 모델을 학습한다.
- 2) 두 번째는 utterance relevance classification이라 불리는 새로운 objective으로 모델을 학습하고, 이는 주어진 utterances와 target utternace 사이의 관계를 보다 세부적인 레이블로 분류하는 것이다.
- 대화는 여러 개의 utterance와 한 개의 response를 포함하는 context로 구성된다.
- post-training동안 전체의 context–response pair을 학습하는 대신 대화를 여러 개의 새로운 short context-response pairs로 나눠서 학습하는 것에는 2가지 장점이 있다.
- 먼저, 모델은 internal utterances 사이의 상호작용을 배울 수 있다, 이는 이전의 학습 방법들에서 간과되었던 것이다.
- 이전의 멀티턴 response selection 모델들은 여러 발화들과 응답을 가지는 컨텍스트 사이의 관련 정보를 식별하는데 초점을 맞춘다.
- 컨텍스트 안의 발화들 사이의 관계를 점진적으로 확장하고 학습하는 대신에
- 관련 정보를 이해하기 위해, BERT는 전체 컨텍스트를 입력으로 취하여, context와 response 사이의 관계를 표현한다.
- 전체의 context와 response 사이의 관계는 self-attention을 통하여 학습될 수 있다.
- 그러나, 대화의 발화들 사이의 관계는 쉽게 간과된다.
- 이러한 이슈를 해결하기 위해, 우리는 전체의 대화를 여러 개의 짧은 context-response pairs로 나눈다.
- 각 pair는 internal utternaces로 구성되기 때문에, 모델은 utterance level interactions을 학습할 수 있다.
- 두 번째 장점은 모델이 utternaces 사이의 관게를 좀 더 정확하게 캡쳐할 수 있는 것이다.
- 일반적으로, response와 연관된 utterances은 response와 가까이 위치해있다.
- 짧은 context-response pairs은 오직 utterances로 구성됨으로써, response와 가깝고 좀 더 정교한 학습이 가능하다.
- fine-grained post-training의 다른 전략은 utterance relevance classification (URC)라 부르는 새로운 학습 objective을 사용하는 것이다.
- BERT에서 사용되는 NSP의 케이스에서는, 모델이 target 발화들이 랜덤인지 그 다음인지를 구별한다.
- Lan (2020)에서 언급한것처럼, NSP로 학습된 모델은 쉽게 발화들의 semantic meaning 을 구별하는 topic prediction을 할 수 있다.
- 그러나, 선택된 발화들이 연속적인지 아닌지 구별하는 coherence predicition은 부족하다.
- Lan et al. (2020)에서 사용하는 sentence ordering prediction (SOP)은 두 시퀀스의 순서가 훈련되었기 때문에 발화들사이의 coherence가 잘 학습된다.
- 그러나, 두 시퀀스들의 semantically가 유사하기 때문에 topic prediction은 상대적으로 불충분하다.
- 멀티턴 대화에서 smenatically 유사한 발화들 사이를 구별하는 것과 선택된 발화들이 연속적인지를 결정하는 것은 중요하므로, 우리는 URC을 제안한다.
- URC는 타겟 발화들을 세 개의 카테고리들로 (random, semantically similar, next) 분류해서 topics와 coherence을 배우는 것이다.
- 우리의 연구의 컨트리뷰션은 다음과 같다.
- 1. fine-grained post-training 동안 짧은 context-response pair 학습을 통해서, 모델은 효과적으로 internal utterances의 상호작용을 배울 수 있다.
- 이는 이전의 방법들에서 쉽게 간과하고 있었다.
- 이것은 response selection의 성능을 크게 향상시킨다.
- 2. 새로운 학습 objective URC을 고안해서, 우리는 발화들의 semantic relevance와 coherence을 측정하도록 모델의 능력을 향상시켜서 모델이 적절한 response을 선택하도록 향상시킨다.
- 우리는 3가지 벤치마크들 (Ubuntu, Douban, E-commerce)에서 중요한 성능 향상으로 SoTA들 달성한다.
- 구체적으로, 우리의 모델은 절대적인 향상 R10@1에서 2.7%p, 0.6%p, and 9.4%p을 Ubuntu, Douban, E-commerce 코퍼스에서 이전의 SoTA 방법에 비해 각각 달성한다.
- 결과들은 제안한 방법이 효과적이고 일반적임을 가리킨다.
2 Related Work
- 대화 시스템을 구축하는 기존 방법은 검색 기반 접근 방식과 세대 기반 접근 방식의 두 가지 그룹으로 분류 할 수 있습니다.
- 최근 연구는 다자간 대화 컨텍스트가 제공 될 때 시스템이 가장 적절한 응답을 선택하는 다자간 검색 대화 시스템에 초점을 맞추고 있습니다.
- Lowe et al. (2015)는 Ubuntu IRC (Internet Relay Chat) Corpus V1과 RNN 기반 기준 모델이라는 새로운 벤치 마크 데이터 세트를 제안했습니다.
- Kadlec et al. (2015)는 LSTM과 CNN을 인코더로 사용하여 컨텍스트와 응답을 효과적으로 인코딩하려는 이중 인코더 기반 모델을 제안했습니다.
- 주의 메커니즘 (Bahdanau et al., 2015; Luong et al., 2015; Vaswani et al., 2017)의 출현과 함께 심층주의 매칭 네트워크 (Zhou et al., 2018)와 같은 모델은 응답 선택 대화 시스템에 대한주의 메커니즘이 제안되었습니다.
- Chen과 Wang (2019)은 자연어 추론 모델을 응답 선택 작업에 적용했습니다.
- Tao et al. (2019)는 다중 상호 작용 블록을 통해 컨텍스트와 응답 간의 깊은 상호 작용을 수행했습니다.
- Yuan et al. (2019)는 멀티 홉 선택기로 대화 컨텍스트 정보를 제어하여 성능을 개선했습니다.
- 사전 훈련 된 언어 모델은 응답 선택에서 인상적인 성능을 보여주었습니다 (Lu et al., 2020; Gu et al., 2020; Whang et al., 2021; Xu et al., 2021).
- 그중 하나 인 BERT는 여러 계층을 가진 양방향 변압기 기반 인코더입니다.
- 우리는 공개적으로 공개 된 BERTbase 모델을 사용합니다. 여기서 레이어 수,주의 헤드, 은닉 상태의 크기가 각각 12, 12, 768입니다.
- 사전 훈련 된 언어 모델에 대한 다양한 훈련 목표가 있습니다.
- BERT는 MLM과 NSP라는 두 가지 교육 목표를 사용합니다.
- 전자는 모델에서 예측 한 토큰의 15 %를 무작위로 마스킹합니다.
- 이 훈련 방법은 모델이 주어진 텍스트의 전반적인 상황 표현을 학습하는 것을 목표로합니다.
- 후자의 방법에서는 모델에 A와 B라는 두 가지 텍스트 시퀀스가 제공됩니다.
- 모델은 시퀀스 B가 시퀀스 다음 시퀀스인지 확인하도록 훈련되었습니다.
- A. 모델은 특수 토큰 SEP로 구분 된 입력 시퀀스 A와 B를받습니다.
- 모델은 시퀀스 A에 대해 0, 시퀀스 B에 대해 1의 세그먼트 임베딩을 사용합니다.
- 그런 다음 CLS 토큰을 사용하여 모델은 시퀀스 A와 B 간의 관계를 예측합니다.
- ALBERT (Lan et al., 2020)는 훈련 목표로 NSP 대신 문장 순서 예측 (SOP)을 사용합니다.
- SOP는 시퀀스 A와 B의 순서가 올바른지 또는 스왑되었는지를 구별합니다.
- 모델이 특정 영역을 이해하는 데 도움이되는 사후 훈련 방법은 반응 선택 작업에서 도입되었습니다 (Whang et al., 2020; Gu et al., 2020; Humeau et al., 2020; Whang et al., 2021 ; Xu et al., 2021).
- 도메인 적응 외에도 사후 훈련 방법은 NSP와의 대화 세션에서 두 시퀀스 간의 관계를 학습하기 때문에 데이터 증가의 장점이 있습니다.
- 그러나 이 방법은 BERT의 사전 훈련 방법을 따르기 때문에 대화 특성을 반영하지 않습니다.
- 이 문제를 해결하기 위해 우리는 다 회전 대화에 적합한 새로운 사후 훈련 방법을 제안합니다.
- 제안 된 방법은 이전 교육 후보다 더 나은 성능을 달성했습니다.
3 Model
3.1 Problem Formalization
- 데이터세트
에서 N triples 셋은 context
, response
, ground truth label
로 구성된다.
- 컨텍스트는 발화들의 시퀀스로
- j번째 발화 uj = {wj,1, wj,2, ..., wj,L}는 L개 토큰들을 가지고 있고, L은 시퀀스 길이다.
- 각 response
- 이것은
- 반대인 경우 (틀린 response)는
- D에서 matching model, g(·, ·)을 찾는 테스크이다.
3.2 Fine-tuning BERT for Response Selection
- 이 연구는 binary classification을 기반으로 response selection 테스크에 fine-tune BERT을 하여 context와 response 사이의 관계를 분석한다.
- 기존의 BERT모델의 input format (x)은 ([CLS], sequenceA, [SEP], sequenceB, [SEP])이고, 여기서 [CLS]와 [SEP]는 CLS와 SEP 토큰들을 의미한다.
- context-response 쌍의 매칭 정도를 측정하기 위해, 우리는 입력을 sequence A을 context로 sequence B를 response로 사용하여 구성한다.
- 추가적으로, 발화 토큰의 끝 (EOU)는 각 발화의 끝에 배치되어 컨텍스트에서 구별됩니다.
- 즉, 정확히는 ([CLS], uA,1, [EOU], uA,2 ...) 이런 느낌
- response selection을 위한 BERT의 입력 형식은 다음과 같습니다.

- x는 position, segment, token embedding의 합을 통하여 연속적으로 input representation vectors가 된다.
- BERT안의 transformer의 블락은 컨텍스트의 input representation과 response 사이를 self-attention을 통하여 cross attention을 계산한다.
- 그리고나서, BERT에서 입력 토큰의 첫 번째 입력의 마지막 hidden vector T_[CLS]은 context-response pair의 representation을 모으는데 사용된다.
- 마지막 score g(c, r)은 context와 response 사이의 매칭 정도이고 T_[CLS]가 single-layer 뉴럴 네트워크를 통하여 얻게된다.

- 여기서 W_fine은 fine-tuning에서 task-specific 학습가능한 파라미터이다.
- 아래의 fine-grained post-training과 다르게, 여기서는 logit을 하나를 뽑고 sigmoid을 태운다.
- 아래에서는 3개의 classification 문제로 접근하기 때문에 3개의 logit이 나오고 그걸 cross entropy loss을 계산하는 식
- 결국, 모델의 weights은 cross-entropy loss 함수를 사용하여 업데이트된다.




3.3 Fine-grained Post-training
- 멀티턴 대화 정보를 효과적으로 캐치함으로써 적절한 response 선택의 능력을 향상시키기 위해, 우리는 간단하지만 파워풀한 fine-grained post-training 방법을 제시한다. (그림1)
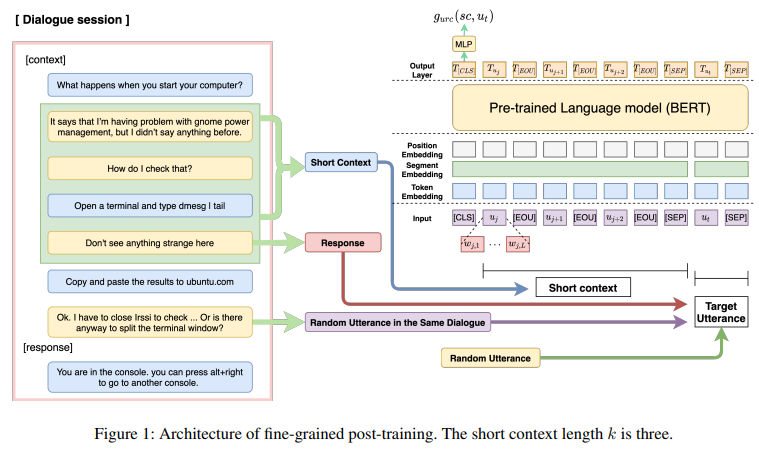
- fine-grained post-training 방법은 2가지 학습 전랴이 있다.
- 전체의 대화 세션은 여러 개의 short context-response pairs로 나뉘고, URC는 (utterance relevance classification) 학습 objectives의 하나로 사용된다.
- 이전의 전략을 통하여, 모델은 대화안의 관련된 internal 발화들의 상호작용을 배운다.
- URC을 통하여, 발화들의 semantic relevance와 coherence을 배운다.

3.3.1 Short Context-response Pair Training
- 우리는 대화 세션의 모든 발화들을 사용해서 여러 개의 short context-response 쌍들을 구성해서 모델을 post-train을 하여 utterance level interaction을 배운다.
- 우리는 각 발화들을 response로 간주하고 이전의 k 발화들을 short context로 한다.
- short context는 대화 세션의 발화들의 평균 수보다 적은 발화들을 가지고 있다.
- 각 short context-response pair은 internal utterance 상호작용을 배우도록 학습되고, 결국 모델이 대화 세션의 모든 발화들 사이의 관계를 이해하도록 모델링하게한다.
- 이것은 모델이 response와 가깝게 연관된 발화들의 interaction을 배우도록 학습하게한다.
- 왜냐하면 context는 short length로 적절하게 구성되기 때문이다.
3.3.2 Utterance Relevance Classification
- NSP objective는 발화들 사이의 coherence을 캡쳐하는데 부적절하다.
- 이것은 NSP가 random과 next utternace 사이를 구별함으로써 중점적으로 topic의 semantic relevance을 학습하기 때문이다.
- objective function으로 SOP을 사용함으로써, semantic relevance을 구별하는 능력은 감소한다.
- 왜냐하면 모델은 유사한 토픽에서의 두 발화들의 coherence을 배우기 때문이다.
- 대화속의 semantic relevance와 coherence 두 개를 배우기 위해, 우리는 새로운 학습 objective을 제안한다.
- 이는 그림 2의 utterance relevance classification (URC)로 불린다.

- URC는 주어진 short context의 target utterance을 3개의 레이블로 구별하는 것이다.
- 첫 번째 label은 random utterance이다.
- 두 번째는, response가 아닌 utterance로 같은 대화 세션에서 sampled된 것이다.
- 같은 대화 세션의 발화들은 정답 reponse와 유사한 topic을 가지지만, 그들은 coherence prediction으로 부적절하다.
- 마지막은 정답 response가 선택되는 것이다.
- 모델은 random utternaces와 correct responses 사이의 classification을 수행하는 topic prediction을 배운다.
- 그리고 모델은 같은 대화 세션들에서 random utternaces와 correct response을 분류해서 coherece prediction을 한다.
- short context와 target utterance 사이의 관계를 3개의 케이스로 분류함으로써, 모델은 대화 세션의 semantic relevance 정보와 coherence information 둘 다 배울 수 있다.

3.3.3 Training Setup
- fine-grained post-training (FP) 방법은 그림1에서 보여준다.
- 먼저, conversation session
가 주어지면, 우리는 연속적인 utterances을 선택하고 k개의 context length를 가지는 short context-response pair
을 형성한다.
- 모델은 short context
와 주어진 target utterance ut 사이의 관계를 분류한다.
- target utterance는 3개의 옵션중의 하나이다.
- random utterance u_r
- 같은 대화세션의 random utterance u_s
- response
- 1 ≤ s ≤ M+1 와 j+k != s
- We denote the input sequence x for the fine-grained post-training as follows:

- 모아진 representation T[CLS]가 사용된다.
- 마지막 score g_urc(sc, ut)는 T[CLS]을 single-layer perceptron을 통과하여 얻어지고, short context와 target utterance 사이의 relevance의 정도는 이 score을 통해 구해진다.
- URC loss을 계산해서, 우리는 cross-entropy loss을 사용하고, 이는 다음과 같이 형식화된다.

- 제안된 모델을 학습하기 위해, 우리는 MLM와 URC을 함께 사용한다.
- MLM와 같은 경우엔, 우리는 dynamic masking 기술을 사용한다. (RoBERTa에서 제안한)
- 미리 지정한 token을 마스킹해서 학습하는 대신, 매 타임에서 random하게 토큰을 masking함으로써 모델은 좀 더 contextual respresntations을 학습할 수 있다.
- 모델을 최적화 하기 위해, 우리는 MLM와 URC의 cross-entropy loss의 합을 사용하고 다음과 같다.




4 Experiments
4.1 Datasets (번역)
- 우리는 Ubuntu Corpus V1, Douban Corpus 및 E-commerce Corpus를 포함하여 널리 사용되는 벤치 마크에서 모델을 테스트했습니다.
- 세 가지 데이터 세트에 대한 통계는 표 1에 나와 있습니다.

- Ubuntu Corpus
- Ubuntu IRC Corpus V1 (Lowe et al., 2015)은 공개적으로 사용 가능한 도메인 별 대화 데이터 세트 인 채팅 로그 대화입니다.
- 이 대화 데이터는 Ubuntu 관련 주제를 다룹니다.
- 우리의 연구에서 Xu et al. (2017)이 사용됩니다.
- 데이터는 숫자, URL 및 시스템 경로와 같은 특수한 자리 표시 자로 사전 처리됩니다.
- Douban Corpus
- Douban Corpus (Wu et al., 2017)는 인기있는 소셜 네트워킹 서비스 인 Douban 그룹의 중국 오픈 도메인 데이터 세트입니다.
- 두 차례 이상의 대화 (즉, 두 사람 간의 대화)로 구성됩니다.
- E-commerce Corpus
- 전자 상거래 코퍼스 (Zhang et al., 2018)는 중국 최대의 전자 상거래 플랫폼 인 Taobao에서 수집 한 중국의 다자간 대화입니다.
- 여기에는 고객과 고객 서비스 직원 간의 실제 대화가 포함됩니다.
- 코퍼스는 상담, 추천 등 다양한 대화로 구성됩니다.

4.2 Post-training Data
- fine-grained post-training을 위해, 우리는 3개의 벤치마크 데이터세트를 재구성했다.
- 특히 각 벤치 마크의 교육 세트에있는 10 만 개의 트리플 중 500,000 개의 positive 트리플을 대화 세션으로 사용했습니다.
- 하나의 대화 세션에서 여러 개의 짧은 컨텍스트-응답 쌍을 만들 수 있기 때문에 결국 Ubuntu Corpus, Douban Corpus, E-commerce Corpus에 대해 각각 12M, 9M 및 6M subcontext-response쌍을 구성했습니다.
- 이러한 sub-context-response 쌍은 post-training에 사용되었습니다.
4.3 Evaluation Metric
- 이전 연구(Tao et al., 2019; Yuan et al., 2019; Gu et al., 2020)에 이어 평가 지표로 recall을 사용했습니다.
- Recall은 R10 @ k로 표시되며, 이는 10 개의 후보 응답 중 상위 k 개의 후보 중 정답이 존재 함을 의미합니다.
- 구체적으로 실험에서는 R10@1, R10@2, R10@5를 사용 하였다.
- R10@k 외에도 데이터 세트에 후보자의 긍정적 인 응답이 두 개 이상 포함될 수 있으므로 Douban Corpus에 대해 MAP (mean average precision), MRR (mean reciprocal rank) 및 P@1도 사용했습니다.
4.4 Baseline Methods
- Single-turn matching models: Lowe et al. (2015), Kadlec et al. (2015) proposed basic models with RNN, CNN, and LSTM.
- SMN: Wu et al. (2017) decomposes the context-response pair into several utterance response pairs. After matching every utterance and response, the matching vector is accumulated as the final matching score.
- DUA: Zhang et al. (2018) formulates the previous utterances into the context by using a deep utterance aggregation.
- DAM: Zhou et al. (2018) proposed a transformer encoder-based model and calculated the matching score between the context and response through self-attention and cross attention.
- IoI: Through multiple interaction block chains, Tao et al. (2019) allows for deep-level matching between the utterances and responses.
- ESIM: Chen and Wang (2019) applied the neural language inference (NLI)’s ESIM model to the response selection.
- MSN: Yuan et al. (2019)’s model selects more relevant context utterances with a multihop selector, and it determines the degree of matching between the selected context utterances and the response.
- BERT: A vanilla model fine-tuned to the response selection task on the pre-trained BERTbase without post-training.
- RoBERTa-SS-DA: Lu et al. (2020) proposed the speaker segmentation approach, which discriminates the different speakers and also applied dialogue augmentation.
- BERT-DPT: Whang et al. (2020) proposed a model that applies domain post-training (DPT). The model is post-trained with BERT’s pre-training methods, MLM and NSP, and then fine-tuned to the response selection task.
- BERT-VFT: Whang et al. (2020) applied the efficient variable fine-tuning (VFT) method that was proposed by Houlsby et al. (2019).
- SA-BERT: Gu et al. (2020) incorporated speaker-aware embedding to the model; therefore, it is aware of the speaker change information.
- UMS-BERT+: Whang et al. (2021) proposed a multi-task learning framework consisting of three tasks (i.e., utterance insertion, deletion, and search).
- BERT-SL: Xu et al. (2021) introduced four self-supervised tasks and trained the response selection model with these auxiliary tasks in a multi-task manner.
4.5 Experimental Results

5 Further Analysis
5.1 Performance across Different Lengths of Short Context

5.2 Performance according to Training Objective

5.3 Ablation Study

5.4 Comparison with the Data Augmentation
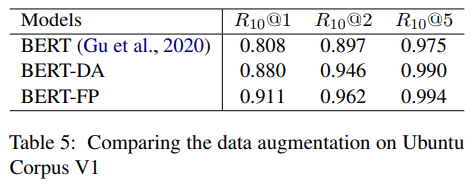
- post-training 방법은 데이터 증가 효과가 있습니다.
- 그러나 fine-tuning 단계에서 데이터를 직접 증가시키는 일반적인 데이터 증가 방법과는 다릅니다.
- 따라서 우리는 Ubuntu Corpus의 일반적인 데이터 증가 (BERT-DA)와 세분화 된 사후 훈련 (BERTFP) 방법을 비교했습니다.
- 데이터 증가 전략은 Chen and Wang (2019)에서 사용 된 방법과 유사합니다.
- 우리는 각 발화를 응답으로, 이전 발화를 컨텍스트로 간주했습니다.
- 실험 결과는 표 5에 나와 있습니다.
- BERT-FP는 R10 @ 1에서 데이터 증가 모델 (BERT-DA)을 3.1 % p 능가합니다.
- 상당한 개선은 데이터 증가에 비해 제안 된 방법의 효과를 보여줍니다.
- 사후 훈련 및 미세 조정 단계를 포함한 우리의 방법은 BERT-DA보다 약 2.5 배 빠릅니다.
- 특히 사후 훈련 된 모델은 BERT-DA보다 미세 조정하는 데 훨씬 적은 시간이 걸리므로 다양한 애플리케이션에 쉽게 적용 할 수 있습니다.

5.5 The Effectiveness of Fine-grained Post-Training for Response Selection Task

- NF: no fine-tuning

6 Conclusion
- 이 논문에서, 우리는 멀티턴 대화에 적합한 새로운 fine-grained post-training 방법을 제안하였다.
- 제안된 방법은 matching model이 대화속 발화의 semantic relevance와 coherence을 배울 수 있고, 모델이 적절한 response을 선택할 수 있는 능력을 향상시킨다.
- 3가지 벤치마크들에 대한 실험 결과들은 우리의 post-training 방법이 response selection에서 우월성을 보여준다.
- 이로부터, 우리의 모델은 새로운 SOTA을 달성한다.
- 미래에, 우리는 새로운 post-training 방법을 다양한 테스크에 적합하게 연구할 것이다.
- question answering 혹은 dialogue generation과 같은
Reference
댓글
댓글 쓰기