NL-188, G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment, Preprint 2023
◼ Comment
- 이 논문도 LLM을 평가자로 쓰는 것이다.
- 기억할 결론은
- GPT3.5보다 GPT4가 더 좋다
- GPT4는 이전 SoTA 방식들보다 좋고 사람과 유사한 결과를 보여준다.
- CoT을 활용하면 평가 성능이 더 올라가며, 여기서는 autoCoT 기법을 보여준다.
- 또한 discrete하게 출력한 점수를 바로 사용하지 않고, 토큰 확률을 활용하여 실수형 score을 도출한다.
- 실수형 score로 인해, 중복되는 점수 분포를 제거한다.
- 실수형 점수가 평가 성능이 더 높다는 것도 보여준다.
- 또한 LLM을 평가자로 하면, 이 점수로 다시 본인을 향상시킬 수도 있다.
- 즉 self-improve? 에 활용될 수도 있는데 여기서 실험한건 아니고 이는 추후 연구로 남겨둔거 같다.
0 Abstract
- 자연어 생성(NLG) 시스템이 생성하는 텍스트의 품질을 자동으로 측정하는 것은 어려운 과제입니다.
- 기존의 참조 기반 지표인 BLEU나 ROUGE와 같은 메트릭은 창의성과 다양성이 필요한 작업에 대한 인간 판단과 상관 관계가 상대적으로 낮다는 사실이 밝혀졌습니다.
- 최근 연구들은 새로운 작업에 인간 참조가 없는 경우에도 적용할 수 있는 대규모 언어 모델(Large Language Models, LLM)을 참조 없는 메트릭으로서 NLG 평가에 활용하는 것을 제안하고 있습니다.
- 그러나 이러한 LLM 기반 평가자들은 여전히 중간 규모의 신경망 평가자들보다 인간 판단과의 일치도가 낮습니다.
- 이 연구에서는 체인 오브 생각(Chain-of-Thoughts, CoT)와 form-filling paradigm을 결합한 방식으로 대규모 언어 모델을 활용하여 NLG 출력물의 품질을 평가하는 G-EVAL 프레임워크를 제안합니다.
- 텍스트 요약 및 대화 생성이라는 두 가지 생성 작업에 대한 실험을 진행하였습니다.
- GPT-4를 백본 모델로 사용한 G-EVAL은 요약 작업에서 인간과의 스피어만 상관 관계가 0.514로 나타나며, 이는 이전 방법들을 큰 폭으로 능가하는 결과입니다.
- 또한 LLM-based evaluators의 동작에 대한 분석을 제시하며, LLM-based evaluators가 LLM이 생성한 텍스트를 편향적으로 평가할 수 있는 잠재적인 우려점을 강조합니다.
1 Introduction
- 대형 언어 모델이 인간이 작성한 텍스트와 거의 구별할 수 없을 만큼 고품질이고 다양한 텍스트를 생성할 수 있게 되면서 자연어 생성 시스템의 품질을 평가하는 것은 어려운 문제가 되었습니다.
- 전통적인 자동 평가 지표인 BLEU, ROUGE, METEOR와 같은 지표는 NLG 평가에 널리 사용되지만, 특히 개방형 생성 작업에 대해서는 인간 판단과 상대적으로 낮은 상관관계를 가지는 것으로 나타났습니다.
- 또한 이러한 지표들은 새로운 작업에 대해 연관된 참조 출력을 수집하는 데 비용이 많이 듭니다.
- 최근 연구들은 LLMs(대형 언어 모델) 자체를 참조 없는 NLG 평가자로 직접 활용하는 것을 제안하고 있습니다.
- 이 아이디어는 LLMs를 사용하여 후보 출력을 생성 확률에 따라 점수를 매기는 것인데, 어떠한 참조 대상도 필요하지 않으며, LLMs가 고품질이고 유창한 텍스트에 더 높은 확률을 할당하는 방식으로 학습되었다는 가정에 기반합니다.
- 그러나 LLMs를 NLG 평가자로 사용하는 것의 타당성과 신뢰성은 체계적으로 조사되지 않았습니다.
- 게다가, meta-evaluations 에서 이러한 LLM-based evaluators은 medium-size neural evaluators보다 인간 판단과 상응하는 정확도가 낮은 것으로 나타났습니다.
- 따라서 LLMs를 NLG 평가에 더 효과적이고 신뢰할 수 있는 프레임워크로 활용하기 위한 필요성이 있습니다.
- 본 논문에서는 LLMs를 chain-of-thoughts (CoT)와 함께 사용하여 form-filling paradigm에서 생성된 텍스트의 품질을 평가하는 G-EVAL 프레임워크를 제안합니다.
- Task Introduction와 Evaluation Criteria만 프롬프트로 제공하여 LLMs에게 상세한 평가 단계의 CoT를 생성하도록 요청합니다.
- 그런 다음 생성된 CoT와 프롬프트를 함께 사용하여 NLG 출력을 평가합니다.
- 평가자의 출력은 양식으로 포맷됩니다.
- 더불어, 출력 평가 토큰의 확률은 최종 지표를 더 정교하게 다듬는 데 사용될 수 있습니다.
- 저희는 text summarization and dialogue generation이라는 두 가지 NLG 작업의 세 가지 메타 평가 벤치마크에서 광범위한 실험을 실시했습니다.
- 결과는 G-EVAL이 인간 평가와의 상관관계 측면에서 기존 NLG evaluators 을 큰 폭으로 능가할 수 있는 것을 보여줍니다.
- 마지막으로, LLM 기반 평가자의 동작에 대한 분석을 수행하고, LLM 기반 평가자가 LLM이 생성한 텍스트에 편향되는 잠재적인 문제점을 강조합니다.
- To summarize, our main contributions in this paper are:
- 1. LLM-based metrics는 일반적으로 reference-based and reference-free baseline metrics에 비해 인간의 품질 판단과의 상관관계에서 뛰어난 성과를 보입니다. 특히, 대화 응답 생성과 같은 개방형 및 창의적인 NLG 작업에 대해서 더욱 그렇습니다.
- 2. LLM-based metrics는 instructions과 프롬프트에 민감하며, chain-of-thought를 통해 더 많은 문맥과 안내를 제공함으로써 LLM 기반 평가자의 성능을 향상시킬 수 있습니다.
- 3. LLM-based metrics는 각각의 토큰 확률에 따라 discrete scores를 re-weighting하여 더 세분화된 연속적인 점수를 제공할 수 있습니다.
- 4. LLM-based metrics에는 사람이 작성한 텍스트보다 LLM에서 생성된 텍스트를 선호하는 잠재적인 문제가 있으며, 이는 LLM-based metrics이 자체 개선을 위한 보상 신호로 사용되는 경우 LLM의 self-reinforcement로 이어질 수 있습니다.
2 Method
- G-EVAL은 세 가지 주요 구성 요소를 가진 프롬프트 기반 평가자입니다:
- 1) 평가 작업의 정의와 원하는 평가 기준을 포함하는 프롬프트,
- 2) 상세한 평가 단계를 설명하는 LLM에 의해 생성된 중간 instructions인 CoT(Chain-of-Thoughts)
- 3) LLM을 호출하고 반환 토큰의 확률에 기반하여 점수를 계산하는 점수 함수입니다.
- Prompt for NLG Evaluation
- 프롬프트는 평가 작업과 원하는 평가 기준을 정의하는 자연어 지시문입니다.
- 예를 들어, 텍스트 요약의 경우 프롬프트는 다음과 같을 수 있습니다:
- 여러분은 하나의 뉴스 기사에 대한 요약문을 제공받게 될 것입니다. 여러분의 작업은 해당 요약문을 한 가지 지표로 평가하는 것입니다. 이 지침을 주의 깊게 읽고 이해하신 후 작업에 착수해 주시기 바랍니다. 검토하는 동안 이 문서를 열어두고 필요할 때 참조하시기 바랍니다.
- 프롬프트는 또한 일관성, 간결성, 문법(coherence, conciseness, or grammar)과 같은 다양한 자연어 생성 작업에 맞는 맞춤형 평가 기준도 포함해야 합니다.
- 예를 들어, 텍스트 요약의 일관성을 평가하기 위해 다음 내용을 프롬프트에 추가합니다:
- 평가 기준: 일관성 (1-5) - 모든 문장의 종합적인 품질. 우리는 이 차원을 구조 및 일관성에 대한 DUC 품질 질문에 맞춰 "요약이 잘 구조화되고 조직화되어야 합니다." 요약은 단지 관련된 정보의 더미가 되어서는 안 되며, 한 주제에 대한 일관된 정보 본문으로 문장별로 구성되어야 합니다.”
- 간단히 말하면 아래처럼 프롬프트를 줘서 평가한다.
- 요약문을 제공받게 될 것이고 아래 지침을 읽고 이해한후에 작업에 평가 작업에 착수해라
- 평가기준: ~~
- 여기서 평가기준에는 일관성, 간결성, 문법등을 어떻게 고려하는지 적어두는 형식
- Auto Chain-of-Thoughts for NLG Evaluation
- CoT는 텍스트 생성 과정 중 LLM이 생성한 중간 표현의 시퀀스입니다.
- 평가 작업의 경우 일부 기준은 간단한 정의를 넘어 더 자세한 평가 지침이 필요하며, 각 작업마다 이러한 평가 단계를 수동으로 설계하는 것은 시간이 많이 소요됩니다.
- 우리는 LLM이 이러한 평가 단계를 자체적으로 생성할 수 있다는 것을 발견했습니다.
- CoT는 생성된 텍스트를 평가하는 데 LLM에게 더 많은 맥락과 안내를 제공할 수 있을 뿐만 아니라 평가 과정과 결과를 설명하는 데도 도움이 될 수 있습니다.
- 예를 들어, 텍스트 요약의 일관성을 평가하는 경우, 프롬프트에 "Evaluation Steps:"라는 줄을 추가하고 LLM이 다음과 같은 CoT를 자동으로 생성하도록 합니다:
- 1. 뉴스 기사를 주의 깊게 읽고 주요 주제와 핵심 포인트를 확인합니다.
- 2. 요약문을 읽고 뉴스 기사와 비교합니다. 요약문이 뉴스 기사의 주요 주제와 핵심 포인트를 포함하며 명확하고 논리적인 순서로 제시되었는지 확인합니다.
- 3. 평가 기준에 따라 1부터 5까지의 척도에서 일관성에 대한 점수를 매깁니다.
- 여기서 1은 가장 낮은 점수이고 5는 가장 높은 점수입니다.
- 보통 CoT을 하라고하면 LLM의 생성이 효과적이게 된다.
- CoT는 단순히 답변만 내뱉는게 아니라, 그 이유에 대해 LLM이 같이 생성하게끔 유도하는 것이다. (사고의 흐름이라고 보면 됨)
- 따라서 보통 few-shot을 통해 CoT 예시를 보여준다.
- 근데 이 사고의 흐름을 어떻게 하라고 보여주는게 아니라, Evaluation Steps: 을 적어서 LLM이 알아서 알아서 CoT을 자동으로 생성하게끔 한다.

- Scoring Function
- scoring function는 설계된 프롬프트, auto CoT, input context, 그리고 평가되어야 하는 target 텍스트와 함께 LLM을 호출합니다.
- 대상 텍스트를 생성하는 conditional probability을 평가 지표로 사용하는 GPTScore와 달리, G-EVAL은 form-filling paradigm으로 직접 평가 작업을 수행합니다.
- GPTScore의 대한 내용은 밑에
- 예를 들어, 텍스트 요약의 일관성을 평가하는 경우 prompt, the CoT, the news article, and the summary을 연결한 다음 LLM을 호출하여 각 평가 측면에 대해 정의된 기준에 따라 1부터 5까지의 점수를 출력합니다.
- 그러나 우리는 이 direct scoring function 가 두 가지 문제를 가지고 있는 것을 알아냈습니다:
- 일부 평가 작업에서는 하나의 숫자가 보통 점수 분포를 지배하는 경우가 있는데, 예를 들어 1부터 5까지의 척도에서 3이 그렇습니다.
- 이로 인해 점수의 낮은 변동성과 인간 판단과의 낮은 상관 관계가 발생할 수 있습니다.
- 언어 모델은 주어진 프롬프트가 소수 값을 명시적으로 요청하더라도 일반적으로 정수 점수만 출력합니다.
- 이로 인해 생성된 텍스트 간의 미묘한 차이를 포착하지 못하는 많은 동점이 발생합니다.
- LLM으로 평가하면 특정 점수가 반복적으로 나오는 경향이 발생한다.
- 이는 다른 논문에서도 언급한 문제이다.
- 실제로 LLM 평가해봤을 때, 1~10점으로 바로 점수를 매기라하면, 7~9점사이가 엄청 많이 나온다.
- 내가 원하는것은 1~10사이의 점수가 잘 퍼져서 나와야하는데.. 이게 프롬프트를 바꿔봐도 잘 컨트롤이 안되는 문제가 있다.
- 이러한 문제를 해결하기 위해 우리는 LLM(Large Language Model)의 output tokens 확률을 사용하여 점수를 정규화하고 가중합을 계산하여 최종 결과를 얻는 것을 제안합니다.
- 출련 토큰의 확률을 이용한다는게 무슨 말이지?
- 형식적으로, 프롬프트에서 미리 정의된 점수 집합 S = {s1, s2, ..., sn}가 주어졌을 때, 각 점수의 확률 p(si)는 LLM에 의해 계산되며 최종 점수는 다음과 같습니다:

- 1점~5점 으로 점수를 매기라하면, 1점이 나올 확률*1점, 2점이 나올 확률*2점, .. 의 합으로 score을 계산한다는 것인가?
- 즉 기댓값을 구하는거 같은데 그럴러면 LLM의 출력 logit(prob)을 알아야한다.
- 이 방법은 생성된 텍스트의 품질과 다양성을 더 잘 반영하는 보다 세밀하고 연속적인 점수를 얻습니다.


3 Experiments
- Zhong의 연구를 따라, 우리는 요약 및 대화 응답 생성이라는 두 가지 자연어 생성(NLG) 작업의 세 가지 벤치마크, SummEval, Topical-Chat 및 QAGS에서 우리의 평가자를 메타-평가합니다.
3.1 Implementation Details
- 우리는 GPT-3.5 (text-davinci-003) 및 GPT-4를 포함한 OpenAI의 GPT 패밀리를 언어 생성 모델로 사용합니다.
- GPT-3.5의 경우, 모델의 결정론성을 높이기 위해 디코딩 temperature 를 0으로 설정합니다.
- GPT-4의 경우, 토큰 확률 출력을 지원하지 않기 때문에 'n = 20, temperature = 1, top p = 1'로 설정하여 20번 샘플링하여 토큰 확률을 추정합니다.
- 모델 logit을 모르니까, temperature 1로하고, 20번 결과 뽑아서 이로 확률값 유추하는 식
- GPT3.5는 근데 확률을 알 수 있나?
- 우리는 G-EVAL-4를 GPT-4를 백본 모델로 사용하는 G-EVAL을 나타내는 데 사용하며, G-EVAL-3.5를 GPT-3.5를 백본 모델로 사용하는 G-EVAL을 나타내는 데 사용합니다.
- 각 작업에 대한 예시 프롬프트는 부록에서 제공됩니다.








3.2 Benchmarks
- 우리는 G-EVAL과 인간 판단 사이의 상관 관계를 측정하기 위해 세 가지 메타-평가 벤치마크를 채택합니다.
- SummEval은 요약에 대한 다양한 평가 방법을 비교하는 벤치마크입니다.
- 이는 각 요약의 네 가지 측면인 fluency, coherence, consistency and relevance에 대한 인간 평가를 제공합니다. 이는 CNN/DailyMail 데이터셋을 기반으로 구축되었습니다.
- Topical-Chat은 지식을 활용하는 대화 응답 생성 시스템에 대해 다양한 평가자를 메타-평가하기 위한 테스트베드입니다.
- 우리는 Zhong를 따라 네 가지 측면에 대한 인간 평가를 사용하여naturalness, coherence, engagingness and groundedness을 평가합니다.
- QAGS은 요약 작업에서 hallucinations을 평가하기 위한 벤치마크입니다.
- 이는 두 가지 다른 요약 데이터셋에서 요약의 일관성 차원을 측정하기 위한 목적을 가지고 있습니다.
3.3 Baselines
- 우리는 G-EVAL을 최첨단 성능을 달성한 다양한 평가자와 비교하여 평가합니다.
- BERTScore는 BERT의 문맥화 임베딩을 기반으로 두 개의 텍스트 간 유사성을 측정합니다.
- MoverScore는 BERTScore를 개선하여 부드러운 정렬과 새로운 집계 방법을 추가하여 더 견고한 유사성 측정을 얻습니다.
- BARTScore는 사전 훈련된 인코더-디코더 모델인 BART의 average likelihood로 평가하는 unified evaluator입니다.
- source와 target의 형식에 따라 다양한 점수를 예측할 수 있습니다.
- FactCC와 QAGS는 생성된 요약의 factual consistency을 측정하는 두 가지 평가자입니다.
- FactCC는 소스 문서와 요약이 일치하는지를 예측하는 BERT 기반 분류기입니다.
- QAGS는 요약에서 질문을 생성하고 해당 답변이 소스 문서에서 찾을 수 있는지 확인하는 question-answering 기반 평가자입니다.
- USR는 다양한 관점에서 대화 응답 생성을 평가하는 평가자입니다.
- 여러 버전이 있으며 각 대상 응답에 다른 점수를 할당합니다.
- UniEval은 텍스트 생성의 다양한 측면을 QA 작업으로서 평가할 수 있는 통합된 평가자입니다.
- 이는 사전 훈련된 T5 모델을 사용하여 평가 작업, 소스 및 대상 텍스트를 질문과 답변으로 인코딩한 다음 QA 점수를 평가 점수로 계산합니다.
- 질문 형식을 변경함으로써 다양한 평가 작업을 처리할 수도 있습니다
- GPTScore는 GPT-3와 같은 생성 사전 훈련 모델을 사용하여 텍스트를 평가하는 새로운 프레임워크입니다.
- 이는 생성 사전 훈련 모델이 주어진 지시와 문맥을 따르는 높은 품질의 생성된 텍스트에 더 높은 확률을 할당할 것으로 가정합니다.
- G-EVAL과 달리, GPTScore는 평가 작업을 형식 채우기 문제가 아닌 조건부 생성 문제로 정의합니다.
- Gptscore: Evaluate as you desire
- GPTscore 논문을 읽어봐야겠지만, 요약테스크를 예로 들어보면
- {원문}이 주어지고 {요약문}을 생성하는데 토큰의 확률들을 이용해서 score을 매기는 방식인것 같다.
3.4 Results for Summarization
- 우리는 Zhong의 접근 방식과 동일하게, 요약 수준의 Spearman 및 Kendall-Tau 상관 관계를 사용하여 다양한 요약 평가 메트릭을 평가합니다.

- SummEval 벤치마크에 대한 다양한 지표의 요약 수준 Spearman(ρ) 및 Kendall-Tau(τ) 상관 관계. probabilities이 없는 G-EVAL(이탤릭체)은 점수에서 많은 동점을 초래하므로 τ에 대한 다른 측정항목과의 공정한 비교로 간주되어서는 안 됩니다.
- 이로 인해 Kendall-Tau 상관관계가 높아지지만 실제 평가 능력을 공정하게 반영하지는 않습니다. 자세한 내용은 섹션 4에 나와 있습니다.
- 즉 기존의 direct하게 점수매기는 것보다 prob의 개념을 넣어서 측정한게 spearman이 증가한다.
- kendall-tau의 경우는, 동점을 초래하는 방식이 좀 더 유리하게 점수가 매겨지는 듯? 그래서 prob이 없는게 오히려 점수가 더 높을 때도 있는거 같음
- 표 1의 첫 번째 부분은 모델 출력과 참조 텍스트 간의 의미적 유사성을 비교하는 메트릭의 결과를 보여줍니다.
- 이러한 메트릭은 대부분의 측면에서 성능이 좋지 않습니다.
- 두 번째 부분은 인간 평가에 기반하여 요약 품질을 학습하는 신경망을 사용하는 메트릭의 결과를 보여줍니다.
- 이러한 메트릭은 유사성 기반 메트릭보다 훨씬 더 높은 상관 관계를 가지며, 이는 요약 평가에 더 신뢰할 수 있는 메트릭임을 시사합니다.
- 표 1의 마지막 부분은 GPT 기반 평가자에 해당하는데, GPTScore도 GPT를 사용하여 요약 텍스트를 평가하지만, 주어진 대상의 조건부 확률에 의존합니다.
- G-EVAL은 SummEval 벤치마크에서 이전 최첨단 평가자들을 크게 앞서 나갑니다.
- G-EVAL-4는 Spearman 및 Kendall-Tau 상관 관계 모두에서 G-EVAL-3.5와 비교하여 인간과의 일치도가 훨씬 높았으며, 이는 GPT-4의 더 큰 모델 크기가 요약 평가에 유익하다는 것을 나타냅니다.
- G-EVAL은 또한 몇 가지 측면에서 GPTScore를 능가하며, 간단한 형식 채우기 패러다임의 효과를 입증합니다.

3.5 Results for Dialogue Generation
- 우리는 다양한 평가자들이 대화 응답의 퀄리티에 대한 인간의 평가와 얼마나 일치하는지를 측정하기 위해 Mehri의 Topical-chat benchmark를 사용합니다.
- 우리는 각 대화 턴마다 Pearson and Spearman 상관 관계를 계산합니다.
- 표 2는 유사성 기반 지표가 응답의 매력적임(engaging)과 기반(grounded)을 확보함에 있어 인간과 잘 일치함을 보여줍니다.
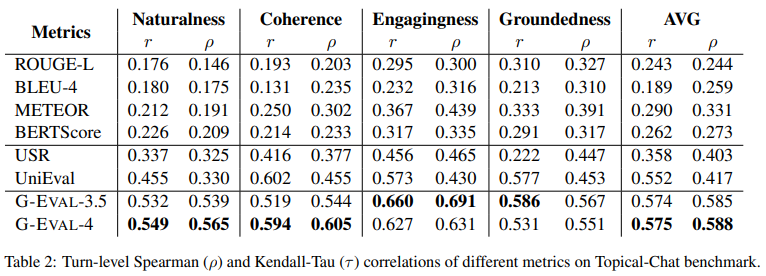
- 그러나 다른 측면에 대해서는 그렇지 않습니다.
- 학습 기반 평가자의 경우, G-EVAL 이전에 UniEval은 모든 측면에서 인간 판단과 가장 일관된 점수를 예측합니다.
- 마지막 부분에 나타난 것처럼, G-EVAL은 Topical-Chat 벤치마크에서 이전 최고 성능 평가자를 크게 능가합니다.
- 특히 G-EVAL-3.5는 G-EVAL-4와 유사한 결과를 달성할 수 있습니다.
- 이는 이 벤치마크가 G-EVAL 모델에게는 상대적으로 쉬운 것을 나타냅니다.

3.6 Results on Hallucinations
- Advanced NLG models은 종종 문맥 입력과 일치하지 않는 텍스트를 생성하고 최근 연구에서는 강력한 언어 모델들도 hallucination 문제에 시달리고 있다는 것을 발견했습니다.
- 이로 인해 최근 연구는 요약의 일관성 측면을 측정하기 위한 평가자를 설계하는 데 동기부여를 받았습니다.
- 우리는 QAGS meta-evaluation benchmark를 테스트했는데, 이는 CNN/DailyMail 및 XSum 두 가지 다른 요약데이터셋을 포함합니다.
- 표 3은 BARTScore가 더 추출적인 하위집합(QAGS-CNN)에서 잘 수행되지만 더 추상적인 하위집합(QAGS-Xsum)에서는 상관관계가 낮다는 것을 보여줍니다.

- UniEval은 데이터의 두 하위집합 모두에 대해 좋은 상관관계를 가지고 있습니다. 평균적으로, G-EVAL-4는 QAGS에서 모든 최첨단 평가자들을 능가하며, 특히 QAGS-Xsum에서 큰 차이를 보입니다.
- 반면, G-EVAL-3.5는 이 벤치마크에서 잘 수행되지 않았는데, 이는 일관성 측면이 언어 모델의 능력에 민감하다는 것을 나타냅니다.
- 이 결과는 표 1과 일치합니다.

4 Analysis
- Will G-EVAL prefer LLM-based outputs?
- LLM을 평가자로 사용하는 것에 대한 우려 중 하나는, LLM 자체가 생성한 출력을 고집하여 고품질의 인간 작성 텍스트보다 선호할 수 있다는 점입니다.
- 이 문제를 조사하기 위해, 우리는 요약 작업에서 실험을 실시하며, LLM이 생성한 요약과 인간이 작성한 고품질 요약의 평가 점수를 비교합니다.
- 우리는 Zhang 등의 연구(2023)에서 수집한 데이터셋을 사용하였는데, 이 연구에서는 우선 휴대폰 작가들에게 뉴스 기사에 대한 고품질 요약을 작성하도록 요청하고, 그 후에 주석 작업자들에게 인간이 작성한 요약과 LLM이 생성한 요약(GPT-3.5, text-davinci-003 사용)을 비교하도록 했습니다.
- LLM이 평가하는 것은 생성 테스크..
- 근데 LLM 생성한 텍스트의 품질을 믿을만한가?를 확인하기 위해 요약 테스크를 LLM(GPT3.5)에게 시킴
- 그것을 GPT4로 평가한듯
- 이 데이터셋은 세 가지 범주로 나눌 수 있습니다:
- 1) 인간 판단 기준에 따라 GPT-3.5 요약보다 높은 점수를 받은 인간 작성 요약,
- 2) 인간 판단 기준에 따라 GPT-3.5 요약보다 낮은 점수를 받은 인간 작성 요약,
- 3) 인간 판단 기준에 따라 인간 작성 요약과 GPT-3.5 요약이 동등하게 좋게 평가된 경우입니다.
- 우리는 각 범주의 요약을 평가하기 위해 GEVAL-4를 사용하고, 평균 점수를 비교합니다.
- 결과는 그림 2에 나와 있습니다.

- 표의 행에 Summary is Better이거는 사람이 봤을 떄를 의미하고
- 이에 상관없이 G-EVAL-4는 GPT3.5가 좋다고 평가하는 경향이 있다.
- 우리는 G-EVAL-4가 사람평가자가 humanwritten summaries을 선호하는 경우 humanwritten summaries에 더 높은 점수를 부여하고, 사람평가자가 GPT-3.5 요약을 선호하는 경우 낮은 점수를 부여하는 것을 볼 수 있습니다.
- 사람평가자는 사람vsGPT3.5의 요약결과를 선호하는 것에 따라 점수를 부여함
- 그러나 G-EVAL-4는 항상 사람평가자가 humanwritten summaries을 선호하는 경우에도 GPT-3.5 요약에 더 높은 점수를 부여합니다.
- G-EVAL-4은 사람평가자가 사람요약을 선호해도 GPT3.5에 선호하는 경향이 있음.
- We propose two potential reasons for this phenomenon:
- 1. 고품질 시스템에서 나온 자연어 생성(NLG) 결과물은 평가가 어렵습니다. 원본 논문의 저자들은 인간이 작성한 요약과 LLM이 생성한 요약을 판단하는 데 대한 판단자 간 일치도가 매우 낮다는 것을 발견했는데, Krippendorff의 알파 값이 0.07이었습니다.
- 2. G-EVAL은 LLM이 생성과 평가 중에 동일한 평가 기준 개념을 공유할 수 있기 때문에 LLM이 생성한 요약에 편향될 가능성이 있습니다.
- 우리의 연구는 이 문제에 대한 예비 연구로 간주되어야 하며, LLM 기반 평가자의 행동을 완전히 이해하고 LLM이 생성한 텍스트에 대한 내재적인 편향을 줄이기 위해 더 많은 연구가 필요합니다.
- 우리는 이 우려를 강조하면서, 평가 점수가 더 조정하기 위한 보상 신호로 사용될 경우 LLM 기반 평가자가 LLM 자체를 자기 강화시킬 수 있다는 맥락에서 이를 제시합니다.
- 이로 인해 LLM이 진정한 NLG 작업의 평가 기준이 아닌 자체 평가 기준에 과적합될 수 있습니다.
- The Effect of Chain-of-Thoughts
- 우리는 SummEval 벤치마크에서 체인 오브 스루츠(CoT)를 사용한 G-EVAL과 CoT를 사용하지 않은 G-EVAL의 성능을 비교합니다.
- 표 1은 CoT를 사용한 G-EVAL-4가 모든 차원에서 특히 유창성 측면에서 CoT를 사용하지 않은 G-EVAL-4보다 더 높은 상관 관계를 가지는 것을 보여줍니다.
- 이는 CoT가 생성된 텍스트를 평가하기 위해 LLM에게 더 많은 맥락과 지침을 제공할 수 있으며, 평가 과정과 결과를 설명하는 데도 도움이 될 수 있다는 것을 시사합니다.
- 이 CoT가 autoCoT라는게 신기한듯
- The Effect of Probability Normalization
- 우리는 SummEval 벤치마크에서 probability normalization를 사용한 G-EVAL과 probability normalization를 사용하지 않은 G-EVAL의 성능을 비교합니다.
- 표 1은 KendallTau 상관 관계에서 확률을 사용한 G-EVAL-4가 SummEval에서 확률을 사용하지 않은 G-EVAL-4보다 우위에 있는 것을 보여줍니다.
- 우리는 이것이 Kendall-Tau 상관 관계 계산과 관련이 있다고 믿습니다.
- 이 계산은 일치하는 쌍과 불일치하는 쌍의 수에 기반합니다.
- 확률 없이 직점 점수를 매길 경우, 많은 동점이 발생할 수 있는데, 이는 일치하거나 불일치한 것으로 간주되지 않습니다.
- 이로 인해 더 높은 Kendall-Tau 상관 관계가 나타날 수 있지만, 이는 생성된 텍스트를 평가하는 모델의 실제 능력을 반영하지 않을 수 있습니다.
- 반면, 확률 정규화는 생성된 텍스트 사이의 미묘한 차이를 더 잘 포착하는 더 세밀한 연속 점수를 얻을 수 있습니다.
- 이는 확률을 사용한 G-EVAL-4의 더 높은 Spearman 상관 관계에 나타납니다.
- 이는 점수의 순위 순서에 기반합니다.
- 확률을 반영한 score가 결국 더 좋다는 의미
- The Effect of Model Size
- 우리는 SummEval 및 QAGS 벤치마크에서 다른 모델 크기로 G-EVAL의 성능을 비교했습니다.
- 표 1과 표 3은 G-EVAL-4가 대부분의 차원과 데이터셋에서 G-EVAL-3.5보다 더 높은 상관 관계를 가지는 것을 나타냅니다.
- Topical-Chat 벤치마크에서만 매력성과 기초성 면에서 그렇지 않았습니다.
- 이는 더 큰 모델 크기가 G-EVAL의 성능을 향상시킬 수 있음을 보여줍니다.
- 특히 일관성과 관련성과 같이 더 도전적이고 복잡한 평가 작업에 대해서는 더욱 더 나은 성능을 제공할 수 있습니다.

5 Related Work
- Ngram-based Metrics
- N-그램 기반 메트릭은 생성된 텍스트와 참조 텍스트 간의 어휘적 중복을 측정하여 NLG 모델을 평가하는 점수를 나타냅니다.
- BLEU (Papineni et al., 2002)는 기계 번역 평가를 위해 가장 널리 사용되는 메트릭으로, 수정된 n-그램 정밀도와 간결성 패널티의 기하 평균을 계산합니다.
- ROUGE (Lin, 2004)는 요약 평가를 위한 재현 지향적 메트릭으로, 생성된 요약과 참조 요약 세트 간의 n-그램 중복을 측정합니다.
- 최근 NLG 논문의 60% 이상이 ROUGE나 BLEU만을 사용하여 시스템을 평가한다는 것이 보여졌습니다 (Kasai et al., 2021).
- 그러나 이러한 메트릭은 내용 품질을 측정하지 못하며 (Reiter and Belz, 2009) 문법 오류를 포착하지 못하기 때문에 (Stent et al., 2005), NLG 시스템의 신뢰성을 정확하게 반영하지 못합니다.
- Embedding-based Metrics
- 임베딩 기반 메트릭은 단어 또는 문장 임베딩을 기반으로 생성된 텍스트와 참조 텍스트 간의 의미적 유사성을 측정하여 NLG 모델을 평가하는 점수를 나타냅니다.
- WMD (Kusner et al., 2015)는 단어 임베딩을 기반으로 두 개의 텍스트 간 거리를 측정하는 메트릭입니다.
- BERTScore (Zhang et al., 2019)는 BERT (Devlin et al., 2019)의 문맥화된 임베딩을 기반으로 두 개의 텍스트 간 유사성을 측정합니다.
- MoverScore (Zhao et al., 2019)는 BERTScore를 개선하여 더 견고한 유사성 측정을 얻기 위해 부드러운 정렬과 새로운 집계 방법을 추가합니다.
- (Clark et al., 2019)은 문장 임베딩을 기반으로 생성된 텍스트와 참조 텍스트 간의 유사성을 계산하여 다중 문장 텍스트를 평가하는 메트릭을 제안합니다.
- Task-specific Evaluators
- Task-specific metrics은 특정 작업 요구사항을 기반으로 생성된 텍스트의 품질을 측정하는 점수를 나타냅니다.
- 예를 들어, 요약 작업은 생성된 요약의 일관성을 평가해야 합니다 (Kryściński et al., 2020; Wang et al., 2020; Cao et al., 2020; Durmus et al., 2020), 그리고 대화 응답 생성 작업은 생성된 응답의 일관성을 평가해야 합니다 (Dziri et al., 2019; Ye et al., 2021).
- 그러나 이러한 메트릭은 다른 NLG 작업에는 일반화되지 않으며, 생성된 텍스트의 전체적인 품질을 측정할 수 없습니다.
- Unified Evaluators
- 최근에는 일부 평가자들이 입력 및 출력 내용을 변화시킴으로써 다양한 차원에서 텍스트 품질을 평가하는 데 사용되거나 (Yuan et al., 2021), 모델 변형을 사용하여 (Mehri and Eskenazi, 2020) 개발되었습니다.
- UniEval (Zhong et al., 2022)은 텍스트 생성의 다양한 측면을 QA 작업으로 평가할 수 있는 통합 평가자입니다.
- 질문 형식을 변경함으로써 다양한 평가 작업을 처리할 수 있습니다.
- LLM-based Evaluators
- 푸 등은 (2023) GPT-3와 같은 생성 사전 훈련 모델을 사용하여 텍스트를 평가하는 새로운 프레임워크인 GPTScore를 제안했습니다.
- 이 프레임워크는 생성 사전 훈련 모델이 주어진 지시와 맥락에 따라 높은 품질의 생성된 텍스트에 더 높은 확률을 할당할 것으로 가정합니다.
- Gptscore: Evaluate as you desire
- 왕 등은 (2023) ChatGPT를 NLG 평가자로 사용하는 초기 조사를 수행했습니다.
- Is chatgpt a good nlg evaluator? a preliminary study.
- Kocmi와 Federmann은 (2023) GPT 모델을 기계 번역 작업을 평가하는 데 사용하는 것을 제안했습니다.
- Large language models are state-of-the-art evaluators of translation quality
6 Conclusion
- 본 논문에서는 우리는 생성된 텍스트의 품질을 평가하기 위해 chain-of-thoughts (CoT)와 함께 LLM을 사용하는 G-EVAL 프레임워크를 제안합니다.
- 우리는 텍스트 요약 및 대화 생성 두 가지 NLG 작업에 대해 광범위한 실험을 진행하고, G-EVAL이 최신 평가자보다 뛰어나며 높은 인간 일치도를 달성할 수 있음을 보여줍니다.
- 또한 LLM 기반 평가자의 행동에 대한 예비 분석을 제안하며, LLM 기반 평가자가 LLM이 생성한 텍스트를 향한 편향 가능성이 있는 잠재적인 문제점을 강조합니다.
- 우리는 우리의 연구가 LLM을 NLG 평가에 활용하는 데 대한 더 많은 연구를 영감을 주기를 바라며, 또한 LLM을 평가자로 사용하는 데 잠재적인 위험과 도전에 대한 인식을 높일 수 있기를 희망합니다.
Reference
댓글
댓글 쓰기