*NL-213, Llama 2: Open Foundation and Fine-Tuned Chat Models, Preprint 2023
Abstract
- 본 연구에서는 7억 개에서 700억 개의 파라미터까지 다양한 규모의 사전 훈련 및 파인 튜닝된 대규모 언어 모델(Large Language Models, LLMs)인 Llama 2를 개발하고 공개합니다.
- 우리의 파인 튜닝된 LLMs인 Llama 2-Chat은 대화 사용 사례에 최적화되었습니다.
- 저희 모델들은 우리가 테스트한 대부분의 벤치마크에서 오픈 소스 대화 모델보다 우수한 성능을 보이며, 저희가 실시한 인간 평가에서 유용성과 안전성에 대한 평가에 따르면, 닫힌 소스 모델에 대한 적절한 대안일 수 있습니다.
- 우리는 Llama 2-Chat의 파인 튜닝 및 안전성 개선 접근 방식에 대한 상세한 설명을 제공하여 커뮤니티가 저희의 작업을 기반으로 빌드하고 책임 있는 LLMs의 개발에 기여할 수 있도록 합니다.

1 Introduction
- 대형 언어 모델(LLMs)은 프로그래밍 및 창의적 글쓰기와 같은 전문 분야를 포함하여 다양한 분야에서 전문 지식이 필요한 복잡한 추론 작업에서 뛰어난 능력을 발휘하는 고도로 능숙한 AI 어시스턴트로 큰 가능성을 보여주고 있습니다.
- 이들은 직관적인 채팅 인터페이스를 통해 사람들과 상호 작용할 수 있게 해주어 일반 대중 사이에서 빠르고 널리 채택되고 있습니다.
- LLMs의 능력은 훈련 방법론의 보다 단순해 보이는 성격을 감안할 때 주목할 만합니다.
- 자기지도 데이터의 방대한 말뭉치에서 사전 훈련된 자기회귀 트랜스포머는 인간의 선호도와의 조율을 위해 Reinforcement Learning with Human Feedback (RLHF)와 같은 기술을 통해 사전 정렬됩니다.
- 비록 훈련 방법론이 간단하지만, 높은 컴퓨팅 요구로 인해 LLMs의 개발은 소수의 주요 참가자로 제한되어 왔습니다.
- BLOOM (Scao et al., 2022), LLaMa-1 (Touvron et al., 2023) 및 Falcon (Penedo et al., 2023)과 같은 사전 훈련된 LLMs의 공개 배포가 있었지만, 이러한 모델 중 어느 것도 ChatGPT, BARD 및 Claude와 같은 닫힌 "제품" LLMs의 적절한 대체품이 되지 못했습니다.
- 이러한 닫힌 제품 LLMs는 인간의 선호도와 조율하기 위해 심층적으로 파인 튜닝되어 있으며, 이는 그들의 사용성과 안전성을 크게 향상시킵니다.
- 이 단계는 컴퓨팅 및 인간 주석에서 상당한 비용을 필요로 할 수 있으며, 종종 투명하지 않거나 쉽게 재현할 수 없어 커뮤니티 내에서 AI alignment 연구를 진전시키는 것을 제한합니다.
- 본 연구에서는 Llama 2라는 pretrained 및 fine-tuned LLMs(Large Language Models) 패밀리를 개발하고 공개합니다.
- Llama 2 및 Llama 2-Chat은 최대 700억 개의 파라미터 규모로 제공됩니다.
- 우리가 시험한 다양한 도움 및 안전성 평가 기준에 따르면, Llama 2-Chat 모델은 일반적으로 기존의 오픈 소스 모델보다 우수한 성능을 보입니다.
- 또한 우리가 수행한 인간 평가에서는 어느 정도의 폐쇄 소스 모델과 유사한 수준으로 보입니다(그림 1 및 3 참조).


- 우리는 이러한 모델의 안전성을 높이기 위해 안전에 특화된 데이터 주석 및 조정을 하였으며, 레드팀을 통한 테스트 및 반복적인 평가를 수행했습니다.
- 또한, 이 논문은 우리의 fine-tuning 방법론 및 LLM 안전성 향상 방법에 대한 철저한 설명을 기여합니다.
- 이러한 공개가 커뮤니티에게 fine-tuned LLMs를 재현하고 이러한 모델의 안전성을 계속 향상시키는 기회를 제공할 것으로 기대합니다.
- 또한, 우리는 Llama 2 및 Llama 2-Chat 개발 과정에서의 독특한 관찰 결과를 공유합니다.
- 도구 사용의 등장 및 지식의 시간적 조직 등의 새로운 관찰 결과를 포함합니다.
- We are releasing the following models to the general public for research and commercial use :
- 1. Llama 2, an updated version of Llama 1, trained on a new mix of publicly available data. We also increased the size of the pretraining corpus by 40%, doubled the context length of the model, and adopted grouped-query attention (Ainslie et al., 2023). We are releasing variants of Llama 2 with 7B, 13B, and 70B parameters. We have also trained 34B variants, which we report on in this paper but are not releasing.
- 2. Llama 2-Chat, a fine-tuned version of Llama 2 that is optimized for dialogue use cases. We release variants of this model with 7B, 13B, and 70B parameters as well.
- 우리는 안전하게 진행될 때, LLMs의 공개적인 배포가 사회에 순수한 혜택을 가져다 줄 것으로 믿습니다.
- Llama 2 역시 모든 LLMs와 마찬가지로 사용 시 잠재적인 위험을 내재하고 있습니다 (Bender et al., 2021b; Weidinger et al., 2021; Solaiman et al., 2023).
- 현재까지의 테스트는 영어로 진행되었으며, 모든 시나리오를 다루지는 않았으며, 다룰 수도 없었습니다.
- 따라서 Llama 2-Chat의 어떠한 응용 프로그램을 배포하기 전에, 개발자들은 모델의 특정 응용 프로그램에 맞춤화된 안전 테스트 및 조정을 수행해야 합니다.
- 우리는 책임 있는 사용 가이드와 코드 예제를 제공하여 Llama 2 및 Llama 2-Chat의 안전한 배포를 촉진하고 있습니다.
- 우리의 책임 있는 배포 전략의 자세한 내용은 섹션 5.3에서 확인할 수 있습니다.
- The remainder of this paper describes
- our pretraining methodology (Section 2),
- fine-tuning methodology (Section 3),
- approach to model safety (Section 4),
- key observations and insights (Section 5),
- relevant related work (Section 6), and
- conclusions (Section 7).


2 Pretraining

- 새로운 Llama 2 모델 패밀리를 만들기 위해, 우리는 Touvron 등(2023)에서 설명한 사전 학습 접근 방식을 사용했지만, 성능을 향상시키기 위해 여러 가지 변경을 가했습니다.
- Llama: Open and efficient foundation language models. 을 따랐지만 조금 변경
- 구체적으로, 더 견고한 데이터 클리닝을 수행했고, 데이터 믹스를 업데이트했으며, 총 토큰 수를 40% 더 많이 학습했으며, 컨텍스트 길이를 두 배로 늘렸으며, 큰 모델에 대한 추론 확장성을 향상시키기 위해 그룹화된 쿼리 어텐션(GQA)을 사용했습니다.
- 데이터 전처리를 좀 더 열심히하고..
- 컨텍스트도 늘렸고
- grouped-query-attention 확인!
- 표 1은 새로운 Llama 2 모델과 Llama 1 모델의 속성을 비교합니다.



2.1 Pretraining Data
- 우리의 훈련 말뭉치에는 Meta의 제품이나 서비스와 관련된 데이터를 포함하지 않는 공개적으로 이용 가능한 소스의 새로운 데이터 믹스가 포함되어 있습니다.
- 우리는 개인에 대한 개인 정보가 많이 포함된 사이트에서의 데이터를 제거하기 위해 노력했습니다.
- 우리는 성능과 비용의 균형을 고려하여 데이터의 2조 토큰을 학습했습니다.
- 이는 지식을 증가시키고 환각을 억제하기 위해 가장 사실적인 소스를 업샘플링하는 좋은 성능-비용의 트레이드오프를 제공합니다.
- 우리는 모델의 잠재적인 능력과 한계를 더 잘 이해할 수 있도록 다양한 사전 학습 데이터 조사를 수행했습니다.
- 결과는 4.1절에 있습니다.
2.2 Training Details
- 우리는 Llama 1의 대부분의 사전 학습 설정과 모델 아키텍처를 채택했습니다.
- 우리는 standard transformer architecture (Vaswani et al., 2017)를 사용하고,
- RMSNorm을 사용하여 사전 정규화를 적용했습니다(Zhang and Sennrich, 2019),
- SwiGLU 활성화 함수를 사용했습니다(Shazeer, 2020),
- 그리고 rotary positional embeddings(RoPE, Su et al. 2022)을 사용했습니다.
- Llama 1과의 주요 아키텍처적 차이점은 컨텍스트 길이의 증가와 grouped-query attention(GQA)입니다.
- 우리는 각각의 이러한 차이를 세부적으로 설명하고, 그 중요성을 입증하기 위해 제거 실험(ablation experiments)을 수행한 내용을 부록 A.2.1절에서 자세히 다룹니다.
- Hyperparameters.
- 우리는 AdamW 옵티마이저(Loshchilov and Hutter, 2017)를 사용하여 훈련했습니다.
- 이때 β1 = 0.9, β2 = 0.95, eps = 10^-5로 설정하였습니다.
- 우리는 코사인 학습률 스케줄을 사용했고, 2000단계의 워마핑(warmup)을 적용했으며, 최종 학습률을 피크 학습률의 10%로 감소시켰습니다.
- 또한 가중치 감소(weight decay)를 0.1로 설정하고, 그라디언트 클리핑(gradient clipping)을 1.0으로 설정했습니다.
- 그림 5(a)는 이러한 하이퍼파라미터를 사용하여 Llama 2의 훈련 손실을 보여줍니다.

- Tokenizer.
- 우리는 Llama 1과 동일한 토크나이저를 사용합니다.
- 이는 Sennrich 등(2016)의 바이트 페어 인코딩(BPE) 알고리즘을 사용하며, 구현은 SentencePiece(Kudo and Richardson, 2018)에서 제공됩니다.
- Llama 1과 마찬가지로, 모든 숫자를 개별 숫자로 분리하고 알려지지 않은 UTF-8 문자를 분해하기 위해 바이트를 사용합니다.
- 전체 어휘 크기는 32,000개의 토큰입니다.

2.2.1 Training Hardware & Carbon Footprint
- Training Hardware.
- 우리는 Meta의 연구 슈퍼 클러스터(RSC) (Lee and Sengupta, 2022)와 내부 제작 클러스터에서 모델을 사전 학습했습니다.
- 두 클러스터 모두 NVIDIA A100을 사용합니다.
- 이 두 클러스터 간에는 두 가지 주요 차이점이 있습니다.
- 첫 번째는 사용 가능한 인터커넥트의 유형입니다.
- RSC는 NVIDIA Quantum InfiniBand를 사용하고, 우리의 제작 클러스터는 상용 이더넷 스위치를 기반으로 한 RoCE(RDMA over converged Ethernet) 솔루션을 사용합니다.
- 이 두 솔루션은 각각 200 Gbps 엔드포인트를 인터커넥트합니다.
- 두 번째 차이점은 GPU 당 전력 소비 제한입니다.
- RSC는 400W를 사용하고, 우리의 제작 클러스터는 350W를 사용합니다.
- 이 두 클러스터 설정으로 우리는 대규모 훈련에 대한 이러한 다른 유형의 인터커넥트의 적합성을 비교할 수 있었습니다.
- RoCE(더 저렴한 상업용 인터커넥트 네트워크)는 비싼 인피니밴드와 거의 같은 수준으로 2000개의 GPU까지 확장할 수 있으며, 이는 사전 학습을 더 민주화할 수 있게 합니다.
- Carbon Footprint of Pretraining.
- Bender 등(2021a), Patterson 등(2021), Wu 등(2022), Dodge 등(2022)의 이전 연구를 따르고 GPU 장치의 전력 소비 및 탄소 효율성 추정치를 사용하여, Llama 2 모델의 사전 학습으로 인한 탄소 배출량을 계산하는 것을 목표로 합니다.
- GPU의 실제 전력 사용량은 그 활용에 따라 다를 수 있으며, 우리가 GPU 전력의 추정치로 사용하는 Thermal Design Power (TDP)와 다를 것으로 예상됩니다.
- 우리의 계산은 인터커넥트나 GPU 이외의 서버 전력 소비와 같은 추가 전력 수요를 고려하지 않음을 강조해야 합니다.
- 또한, AI 하드웨어(예: GPU)의 생산과 관련된 탄소 배출량은 Gupta 등(2022b,a)의 제안에 따라 전체 탄소 발자국에 추가될 수 있습니다.
- 표 2는 Llama 2 모델 패밀리의 사전 학습에 대한 탄소 배출량을 요약합니다.

- A100-80GB 유형의 하드웨어에서 총 3.3백만 GPU 시간의 계산이 수행되었습니다(TDP가 400W 또는 350W).
- 우리는 훈련을 위한 총 배출량을 539 tCO2eq로 추정하며, 이 중 100%가 Meta의 지속가능성 프로그램에 의해 직접 상쇄되었습니다.
- 우리의 공개 배포 전략은 이러한 사전 학습 비용이 다른 기업에서 발생하지 않아도 되므로 전 세계적인 자원을 더 절약할 수 있습니다.

2.3 Llama 2 Pretrained Model Evaluation
- 이 섹션에서는 Llama 1 및 Llama 2 기본 모델, MosaicML Pretrained Transformer (MPT) 모델 및 Falcon(Almazrouei 등, 2023) 모델의 표준 학술 벤치마크 결과를 보고합니다.
- 모든 평가에 대해 우리는 내부 평가 라이브러리를 사용합니다.
- MPT 및 Falcon 모델에 대한 결과를 내부적으로 재현합니다.
- 이러한 모델에 대해서는 우리의 평가 프레임워크와 공개적으로 보고된 결과 중 최상의 점수를 항상 선택합니다.
- 이 정도면, 다른 모델에 대해서 상당히 어드밴티지를 주는듯
- 표 3에서는 인기 있는 벤치마크 모음 전반에 걸친 전반적인 성능을 요약합니다.

- 같은 사이즈 7B로보면 LLaMA2가 다른 모델보다 대부분 성능이 좋은듯
- LLaMA1보다도 대부분 좋음
- (이 시점 기준) 쉽게 생각하면 오픈소스모델에서 LLaMA2을 걍 백본으로 써라! 이렇게 알고 있으면 될 듯
- 안전 벤치마크는 섹션 4.1에서 공유됩니다.
- 벤치마크는 아래에 나열된 범주로 그룹화됩니다.
- The results for all the individual benchmarks are available in Section A.2.2.
- 코드.
- 우리는 HumanEval (Chen et al., 2021) 및 MBPP (Austin et al., 2021)에서 우리 모델의 평균 pass@1 점수를 보고합니다.
- 상식 추론.
- PIQA (Bisk et al., 2020), SIQA (Sap et al., 2019), HellaSwag (Zellers et al., 2019a), WinoGrande (Sakaguchi et al., 2021), ARC easy 및 challenge (Clark et al., 2018), OpenBookQA (Mihaylov et al., 2018) 및 CommonsenseQA (Talmor et al., 2018)의 평균을 보고합니다. CommonsenseQA에 대해서는 7-shot 결과를 보고하고, 다른 모든 벤치마크에 대해서는 0-shot 결과를 보고합니다.
- 세계 지식.
- 우리는 NaturalQuestions (Kwiatkowski et al., 2019) 및 TriviaQA (Joshi et al., 2017)에서 5-shot 성능을 평가하고 평균을 보고합니다.
- 독해.
- 독해에 대해서는 SQuAD (Rajpurkar et al., 2018), QuAC (Choi et al., 2018) 및 BoolQ (Clark et al., 2019)에서 0-shot 평균을 보고합니다.
- 수학.
- GSM8K (8 shot) (Cobbe et al., 2021) 및 MATH (4 shot) (Hendrycks et al., 2021) 벤치마크의 상위 1에서의 평균을 보고합니다.
- 표 3에서 보여진 것처럼, Llama 2 모델은 Llama 1 모델을 능가합니다.
- 특히, Llama 2 70B는 Llama 1 65B와 비교하여 MMLU 및 BBH에서 각각 약 5점과 약 8점의 결과 향상을 보입니다.
- Llama 2 7B 및 30B 모델은 해당 크기의 MPT 모델보다 코드 벤치마크를 제외한 모든 범주에서 우수한 성능을 보입니다.
- Falcon 모델의 경우, Llama 2 7B 및 34B는 모든 벤치마크 범주에서 Falcon 7B 및 40B 모델을 능가합니다.
- 추가로, Llama 2 70B 모델은 모든 오픈 소스 모델을 능가합니다.
- 오픈 소스 모델 외에도, 우리는 Llama 2 70B 결과를 폐쇄 소스 모델과 비교했습니다.
- 표 4에서 보여진 것처럼, Llama 2 70B는 MMLU 및 GSM8K에서 GPT-3.5 (OpenAI, 2023)와 유사하지만, 코딩 벤치마크에서는 상당한 격차가 있습니다.

- Llama 2 70B 결과는 거의 모든 벤치마크에서 PaLM (540B) (Chowdhery 등, 2022)보다 동등하거나 더 우수합니다.
- Llama 2 70B와 GPT-4 및 PaLM-2-L 사이에는 여전히 큰 성능 차이가 있습니다.
- 우리는 또한 잠재적인 데이터 오염을 분석하고 세부 내용을 A.6절에서 공유했습니다.


3 Fine-tuning
- Llama 2-Chat은 지침 튜닝과 RLHF를 포함한 여러 개월에 걸친 정렬 기술의 반복적인 적용을 통해 얻어진 결과물입니다.
- 이를 위해 상당한 컴퓨팅 및 주석 작업 리소스가 필요했습니다.
- 이 섹션에서는 지도 미세 조정(3.1절), 초기 및 반복적 보상 모델링(3.2.2절), 그리고 RLHF(3.2.3절)를 사용한 실험 및 결과에 대해 보고합니다.
- 또한 다중 턴에서의 대화 흐름을 제어하는 데 도움이 되는 새로운 기술인 Ghost Attention (GAtt)을 소개합니다 (3.3절).
- 안전 평가에 대한 세부 정보는 미세 조정된 모델에 대한 안전 평가를 위해 4.2절을 참조하십시오.
- Getting Started.
- 부트스트랩 과정에서, 우리는 이전에 Touvron (2023)에서 사용된 것과 동일하게 공개적으로 이용 가능한 지침 튜닝 데이터(Chung et al., 2022)로 SFT 단계를 시작했습니다.
- LLaMA1의 데이터로 일단 SFT로 시작
- Quality Is All You Need.
- 다양한 소스에서 제공되는 제3자 SFT(지도 미세 조정) 데이터가 있지만, 이러한 데이터 중 많은 것들이 충분한 다양성과 품질을 갖추고 있지 않다는 것을 발견했습니다. (특히 대화 스타일의 지침에 대한 LLMs의 정렬을 위해.)
- 더 많은 오픈소스 데이터가 있으나 품질이 부족하다.. 내부적으로 이걸 판단하는 과정이 나름 크게 있을듯
- 결과적으로, 우리는 먼저 고품질 SFT 데이터의 몇 천 개의 예제를 수집하는 데 초점을 맞추었습니다.
- 이를 표 5에서 보여줍니다.

- 제3자 데이터 세트에서 수백만 개의 예시를 제외하고 자체 공급업체 기반 주석 작업에서 더 적지만 더 높은 품질의 예시를 사용함으로써 결과가 눈에 띄게 향상되었습니다.
- 즉, 자체적으로 품질 좋은 SFT 데이터 만들었다는 듯
- 이러한 결과는 Zhou et al. (2023)의 결과와 유사하며, 이 연구 역시 제한된 세트의 깨끗한 지침 튜닝 데이터만으로도 높은 품질의 결과를 얻을 수 있다는 것을 보여줍니다.
- 우리는 수만 개의 SFT 주석이 높은 품질의 결과를 달성하는 데 충분하다는 것을 발견했습니다.
- 우리는 총 27,540개의 주석을 수집한 후 SFT 주석을 중단했습니다.
- 엄청 많은 고품질 SFT 데이터를 만든 것은 아님. 2~3만개 수준
- Meta 사용자 데이터는 포함되지 않았음을 참고하십시오. 또한 서로 다른 주석 플랫폼 및 공급업체는 주석을 원본으로 사용할 때도 데이터 확인의 중요성을 강조하는데, 이는 하향 모델 성능이 현저하게 다를 수 있다는 것을 나타냅니다. 데이터 품질을 검증하기 위해 우리는 180개의 예제 집합을 주의 깊게 조사하여 인간이 제공한 주석과 모델이 생성한 샘플을 수동으로 비교했습니다. 놀랍게도, 결과적인 SFT 모델에서 샘플링된 출력이 종종 인간 주석자가 직접 작성한 SFT 데이터와 경쟁력이 있었습니다. 이는 우리가 RLHF를 위한 기호 기반 주석에 더 많은 주석 노력을 다시 할당하고 더 많은 주석을 집중할 수 있다는 것을 제안합니다.
- Fine-Tuning Details.
- 지도 미세 조정을 위해 우리는 초기 학습률이 2 × 10^-5, 가중치 감소가 0.1, 배치 크기가 64이고 시퀀스 길이가 4096 토큰인 코사인 학습률 스케줄을 사용합니다.
- 미세 조정 프로세스에서 각 샘플은 프롬프트(prompt)와 답변(answer)으로 구성됩니다.
- 모델 시퀀스 길이가 올바르게 채워지도록하기 위해 훈련 세트에서 모든 프롬프트(prompt)와 답변(answer)을 연결합니다.
- 프롬프트와 답변 세그먼트를 구분하기 위해 특수 토큰을 사용합니다.
- 우리는 autoregressive objective를 활용하고 사용자 프롬프트에서 토큰 손실을 제로 처리하여 결과적으로 답변 토큰에만 역전파합니다.
- answer쪽만 loss 주는 듯
- 마지막으로 모델을 2 에포크 동안 미세 조정합니다.
- 생각보다 짧네

3.2 Reinforcement Learning with Human Feedback (RLHF)
- RLHF(Reinforcement Learning from Human Feedback)는 사람의 선호도와 지시 따르기와 모델의 행동을 더욱 일치시키기 위해 미세 조정된 언어 모델에 적용되는 모델 훈련 절차입니다.
- 우리는 경험적으로 샘플링된 인간의 선호도를 나타내는 데이터를 수집합니다.
- 여기서 인간 주석자는 두 개의 모델 출력 중 어느 것을 선호하는지 선택합니다.
- 이 인간 피드백은 후속적으로 보상 모델을 훈련하는 데 사용됩니다.
- 이 보상 모델은 인간 주석자들의 선호도 패턴을 학습하고 그에 따라 선호 결정을 자동화할 수 있습니다.
- LLaMA1과 다르게 RLHF도 학습해본듯
3.2.1 Human Preference Data Collection
- 다음으로, 보상 모델링을 위해 인간 선호도 데이터를 수집합니다.
- 다른 방법론 대신 이진 비교 프로토콜을 선택한 이유는 주로 수집된 프롬프트의 다양성을 극대화할 수 있기 때문입니다.
- 그럼에도 불구하고, 다른 전략들도 고려할 가치가 있으며, 이는 향후 작업에 남겨두었습니다.
- 우리의 주석 절차는 다음과 같이 진행됩니다.
- 먼저 주석자에게 프롬프트를 작성하고, 제공된 기준에 따라 두 개의 샘플링된 모델 응답 중 하나를 선택하도록 요청합니다.
- 다양성을 극대화하기 위해 특정 프롬프트에 대한 두 응답은 두 가지 다른 모델 변형에서 샘플링되며, 온도 하이퍼파라미터를 다르게 설정합니다.
- 강제 선택을 제공하는 동시에, 선택된 응답을 대안보다 얼마나 선호하는지에 대해 주석자들에게 레이블을 붙이도록 요청합니다.
- 선택한 응답이 상당히 더 나은지, 더 나은지, 약간 더 나은지, 또는 무시할 만큼 더 나은지/확실하지 않은지를 레이블링합니다.
- 우리의 선호도 주석 수집에서는 helpfulness and safety에 중점을 둡니다.
- helpfulness 는 Llama 2-Chat의 응답이 사용자의 요청을 얼마나 잘 충족시키고 요청된 정보를 제공하는지를 의미하며,
- safety은 Llama 2-Chat의 응답이 안전하지 않은지 여부를 나타냅니다.
- 예를 들어, "폭탄을 만드는 자세한 지침을 제공한다"는 도움이 될 수 있지만, 안전성 가이드라인에 따르면 안전하지 않습니다.
- 이 두 가지를 분리함으로써 각각에 특정 가이드라인을 적용하고 주석자를 보다 잘 지도할 수 있습니다.
- 예를 들어, 우리의 안전성 주석은 주로 적대적인 프롬프트에 초점을 맞추도록 지시합니다.
- 주석 가이드라인의 차이 외에도, 우리는 안전 단계에서 안전 레이블을 추가로 수집합니다.
- 이 추가 정보는 모델 응답을 세 가지 범주 중 하나로 구분합니다:
- 1) 선호하는 응답이 안전하고 다른 응답은 안전하지 않음,
- 2) 두 응답 모두 안전함,
- 3) 두 응답 모두 안전하지 않음,
- 각각의 안전 데이터셋이 이 범주에 해당하는 비율은 18%, 47%, 35%입니다.
- 선택된 응답이 안전하지 않고 다른 응답이 안전한 경우의 예제는 포함하지 않습니다.
- 왜냐하면 우리는 더 안전한 응답이 인간에 의해 더 나은/선호될 것이라고 믿기 때문입니다.
- rejection sampling을 말하는 걸까?
- 안전성 가이드라인 및 안전 주석에 대한 보다 자세한 정보는 4.2.1절에서 찾을 수 있습니다.
- 사람의 주석은 매주 일괄적으로 수집되었습니다.
- 우리가 더 많은 선호도 데이터를 수집함에 따라 보상 모델이 향상되었고, 우리는 점진적으로 Llama 2-Chat용 더 나은 버전을 훈련시킬 수 있었습니다(5절의 결과, 그림 20을 참조).

- Llama 2-Chat의 개선은 또한 모델의 데이터 분포를 변화시켰습니다.
- 보상 모델의 정확도는 이 새로운 샘플 분포에 노출되지 않으면 빠르게 저하될 수 있으므로, 새로운 Llama 2-Chat 튜닝 반복 전에 최신 Llama 2-Chat 반복을 사용하여 새로운 선호도 데이터를 수집하는 것이 중요합니다.
- 선호도 데이터를 만들기 위해, 모델이 생성한 2가지 예시를 보여줘야하는데, 이 예시를 생성할때 계속 새로운 버전을 활용해서 선호도 데이터를 만드는 식
- 이 단계는 보상 모델을 분포에 맞게 유지하고 최신 모델에 대한 정확한 보상을 유지하는 데 도움이 됩니다.
- 표 6에서는 시간이 지남에 따라 수집한 보상 모델링 데이터의 통계를 보고 여러 개의 오픈 소스 선호도 데이터셋과 대조합니다.

- 이 데이터셋에는 Anthropic Helpful and Harmless (Bai et al., 2022a), OpenAI Summarize (Stiennon et al., 2020), OpenAI WebGPT (Nakano et al., 2021), StackExchange (Lambert et al., 2023), Stanford Human Preferences (Ethayarajh et al., 2022) 및 Synthetic GPT-J (Havrilla)가 포함됩니다.
- 우리는 우리가 지정한 가이드라인을 적용한 인간들에 의해 수행된 100만 건 이상의 이진 비교를 기반으로한 대규모 데이터셋을 수집했으며, 이를 Meta 보상 모델링 데이터라고 합니다.
- 프롬프트와 응답의 토큰 수는 텍스트 도메인에 따라 다릅니다.
- 요약 및 온라인 포럼 데이터는 일반적으로 더 긴 프롬프트를 가지고 있으며, 대화형 프롬프트는 보통 더 짧습니다.
- 기존 오픈 소스 데이터셋과 비교하여, 우리의 선호도 데이터는 평균적으로 대화 턴이 더 많고 더 길습니다.


3.2.2 Reward Modeling
- 보상 모델은 모델 응답과 해당 프롬프트(이전 턴의 맥락을 포함한)을 입력으로 받아들여서 모델 생성물의 품질(예: 도움 및 안전성)을 나타내는 스칼라 점수를 출력합니다.
- 이러한 응답 점수를 보상으로 활용하여 RLHF(Reinforcement Learning from Human Feedback) 동안 Llama 2-Chat을 최적화하여 더 나은 인간 선호도 조정 및 개선된 도움 및 안전성을 달성할 수 있습니다.
- 다른 연구들에서 helpfulness and safety이 때로는 상충될 수 있다는 것을 발견했습니다(Bai et al., 2022a).
- 이는 단일 보상 모델이 두 가지 측면 모두에서 잘 수행되기 어렵게 만들 수 있습니다.
- 이를 해결하기 위해 우리는 두 개의 별도 보상 모델을 훈련시킵니다.
- 하나는 helpfulness이 되는 점수에 최적화된 것을 (도움이 되는 보상 모델이라고 함)
- 그리고 다른 하나는 safety에 최적화된 것을 (안전성 보상 모델이라고 함).
- 즉 하나의 보상으로는 도움과 안전성 둘 다 잡기 어렵기 떄문에, 이를 분리해서 2개의 reward 모델을 학습시킨다는 것
- 우리는 보상 모델을 사전 훈련된 채팅 모델 체크포인트에서 초기화합니다.
- 이는 두 모델이 사전 훈련에서 습득한 지식을 활용할 수 있도록 보장하기 때문입니다.
- 간단히 말해서, 보상 모델은 채팅 모델이 알고 있는 것을 알고 있습니다.
- chatgpt 방식도 이렇긴 했음.
- 즉 pretraining한 것이 reward 모델의 inital point로하고, 이를 활용하여 reward 모델을 fine-tuning함.
- 이는 예를 들어 두 모델 사이에 정보 불일치가 있는 경우, 환영을 우선시할 수 있는 경우를 방지합니다.
- 모델 아키텍처 및 하이퍼 파라미터는 사전 훈련된 언어 모델과 동일하지만, 다음 토큰 예측을 위한 분류 헤드가 스칼라 보상을 출력하는 회귀 헤드로 대체됩니다.
- Training Objectives.
- 보상 모델을 훈련하기 위해, 우리는 수집한 쌍대 인간 선호 데이터를 이진 순위 레이블 형식(즉, 선택됨 및 거부됨)으로 변환하고
- 선택된 응답이 그에 대응하는 응답보다 더 높은 점수를 갖도록 강제합니다.
- 우리는 Ouyang et al. (2022)과 일관된 이진 순위 손실을 사용했습니다.

- 여기서 rθ(x, y)는 모델 가중치 θ로 프롬프트 x와 완료 y에 대한 스칼라 점수 출력입니다.
- yc는 주선자가 선택하는 선호 응답이며, yr은 거부된 상대 응답입니다.
- 이진 순위 손실을 기반으로하여, 우리는 도움이 되는 보상 모델과 안전성 보상 모델을 각각 더 나은 도움 및 안전 보상 모델로 개별적으로 수정합니다.
- 저희의 선호도 평가가 네 가지 점의 척도로 분해된다고 가정할 때(예: 현저히 나은), 3.2.1절에서 제시된 것과 같이, 이 정보를 활용하여 더 많은 차이가 있는 생성물에 더 큰 차이를 할당하도록 보상 모델을 명시적으로 가르치는 것이 유용할 수 있습니다.
- 이를 위해 우리는 손실에 여분의 여백 구성 요소를 추가합니다:
- 즉 단순히 A가 B보다 좋다라는 정보말고도, 얼마나 좋은지 레이블을 4가지 척도로 받았었다
- 이걸 반영하기 위해 margin 개념을 loss에 도입

- 여기서 여백 m(r)은 선호도 등급의 이산 함수입니다.
- 당연하게도, 서로 다른 응답을 가진 쌍에 대해 큰 여백을 사용하고, 비슷한 응답을 가진 쌍에 대해서는 더 작은 여백을 사용합니다(표 27에 표시됨).
- 우리는 이 여백 구성 요소가 특히 두 응답이 더 구분 가능한 샘플에서 도움이 되는 보상 모델의 정확도를 향상시킬 수 있다는 것을 발견했습니다.
- 더 자세한 분석 및 해석은 부록 A.3.3의 표 28에서 확인할 수 있습니다.
- Data Composition.
- 우리는 새롭게 수집한 데이터를 기존의 오픈 소스 선호도 데이터셋과 결합하여 보다 큰 규모의 훈련 데이터셋을 형성합니다.
- 초기에는 선호도 주석 데이터를 수집하는 과정에서 오픈 소스 데이터셋을 사용하여 보상 모델을 초기화했습니다.
- 본 연구에서 RLHF(인간 피드백 강화 학습)의 맥락에서 보상 신호의 역할은 어떠한 모델 출력보다는 Llama 2-Chat 출력에 대한 인간 선호를 학습하는 것입니다.
- 그러나 우리의 실험에서는 오픈 소스 선호도 데이터셋에서 부정적인 전이를 관찰하지 않았습니다.
- 따라서 보다 나은 일반화를 가능하게 하고, 보상 해킹을 방지하는 데 도움이 될 수 있는 이러한 데이터셋을 우리의 데이터 혼합에 포함하기로 결정했습니다.
- 즉, Llama 2-Chat이 우리의 보상의 일부 약점을 이용하여 점수를 인위적으로 높이는 등의 행위를 말합니다.
- 다양한 출처에서 사용 가능한 훈련 데이터로, 도움이 되는 보상 모델과 안전성 보상 모델에 대한 다양한 혼합 레시피를 실험하여 최적 설정을 확인했습니다.
- 광범위한 실험을 거쳐서, 도움이 되는 보상 모델은 최종적으로 모든 메타 도움이 되는 데이터와 메타 안전성 및 오픈 소스 데이터의 동일한 부분을 균일하게 추출한 데이터를 결합하여 훈련되었습니다.
- 반면, 메타 안전성 보상 모델은 모든 메타 안전성 및 Anthropict Harmless 데이터로 훈련되며, 메타 도움이 되는 데이터와 오픈 소스 도움이 되는 데이터를 90/10 비율로 혼합합니다.
- 우리는 10% 도움이 되는 데이터가 선택된 응답과 거부된 응답이 모두 안전하다고 판단된 샘플의 정확도에 특히 도움이 되는 것으로 확인했습니다.
- 즉, 오픈소스 데이터랑 메타에서 만든 데이터랑 섞어서 학습시켰다는 것
- 오픈소스 데이터를 메타 데이터랑 섞는다해도 부정적인 영향이 transfer가 안된다고 함
- Training Details.
- 훈련 데이터에 대해 한 번의 에포크 동안 훈련합니다.
- 이전 실험에서는 더 긴 훈련이 과적합을 유발할 수 있다는 것을 발견했습니다.
- 상당히 짧게 학습하네..?
- 베이스 모델과 동일한 옵티마이저 매개변수를 사용합니다.
- 70B 파라미터 Llama 2-Chat의 최대 학습률은 5 × 10^-6이며, 나머지 모델은 1 × 10^-5입니다.
- 학습률은 코사인 학습률 스케줄에 따라 감소되어 최대 학습률의 10%까지 감소합니다.
- 전체 단계의 3%에 대한 워밍업을 사용하며, 최소값은 5입니다.
- 유효 배치 크기는 512개의 쌍 또는 배치 당 1024개의 행으로 고정됩니다.
- Reward Model Results.
- 보상 모델링을 위한 각 인간 선호 주석 배치마다, 모델을 평가하기 위해 1000개의 예제를 테스트 세트로 유지했습니다.
- 해당 테스트 세트의 모든 프롬프트의 합을 각각 “Meta Helpfulness” and “Meta Safety,”으로 참조합니다.
- 참고로, 우리는 기준선으로 다른 공개적으로 이용 가능한 대안들도 평가했습니다:
- FLAN-T5-xl을 기반으로 한 SteamSHP-XL (Ethayarajh et al., 2022),
- DeBERTa V3 Large (He et al., 2020)를 기반으로 한 Open Assistant (Köpf et al., 2023) 보상 모델 및
- OpenAI의 API를 통해 액세스할 수 있는 GPT-4입니다.
- 추론 시에는 훈련과 달리, 모든 보상 모델이 짝을 이루는 출력에 액세스할 필요 없이 단일 출력에 대한 스칼라를 예측할 수 있습니다.
- GPT-4의 경우, 비학습 질문 "A와 B 중에서 최상의 답변을 선택하십시오"로 프롬프트를 제공하며, 여기서 A와 B는 비교를 위해 두 응답입니다.
- 결과를 테이블 7에서 정확도로 보고했습니다.

- 기대했던 대로, 우리 자체 보상 모델은 Llama 2-Chat에 기반을 둔 내부 테스트 세트에서 가장 우수한 성능을 보여줍니다.
- 도움이 되는 보상 모델은 메타 도움 테스트 세트에서 가장 우수한 성능을 보이며, 안전성 보상 모델은 메타 안전 테스트 세트에서 가장 우수한 성능을 보입니다.
- 전반적으로, 우리의 보상 모델은 GPT-4를 포함한 모든 기준선을 능가합니다.
- 논문에서 제안한 reward model이 이전 보상모델보다 좋다!.. (meta 테스트 데이터 및 오픈 데이터에서)
- 흥미롭게도, GPT-4는 직접 훈련되지 않았고 특히 이 보상 모델링 작업을 목표로하지 않았지만, 다른 비메타 보상 모델보다 더 나은 성능을 보입니다.
- 도움이 되는 정도와 안전성이 각각 자신의 영역에서 가장 우수한 성능을 발휘하는 것은 두 가지 목표 사이의 긴장 때문일 수 있습니다(즉, 가능한 한 도움이 되도록 하는 것과 필요할 때 안전하지 않은 프롬프트를 거부하는 것).
- 이는 훈련 중에 보상 모델을 혼란스럽게 할 수 있습니다.
- 단일 모델이 두 가지 차원 모두에서 잘 수행되려면, 프롬프트가 주어졌을 때 더 나은 응답을 선택하는 것뿐만 아니라 적대적 프롬프트와 안전한 프롬프트를 구분하는 것도 배워야 합니다.
- 결과적으로, 두 개의 별도 모델을 최적화함으로써 보상 모델링 작업을 용이하게 만듭니다.
- 안전성과 도움이 되는 정도 사이의 이 긴장에 대한 보다 자세한 분석은 부록 A.4.1에서 찾아볼 수 있습니다.
- 테이블 8에서 선호도 등급별로 점수를 그룹화할 때, "현저히 나은" 테스트 세트에 대한 정확도가 우수함을 확인할 수 있으며, 비교 쌍이 더 유사해짐에 따라 점진적으로 저하됩니다(예: "조금 나은").

- 즉, helpfulness와 safety로 나눠서 해보면, 다른 특성을 가진다고 볼 수 있다.
- 모델 응답 사이를 결정할 때 인간의 선호도를 모델링하는 것이 어려워지는 것은, 주석자의 주관성과 응답을 구별할 수 있는 미묘한 세부 사항에 대한 의존으로 인해 예상됩니다.
- 더 구별되는 응답에 대한 정확도가 Llama 2-Chat 성능을 향상시키는 데 가장 중요하다는 점을 강조합니다.
- 인간 선호 주석 합의율도 유사한 쌍보다는 더 구별된 응답에 더 높습니다.
- Scaling Trends.
- 보상 모델의 데이터와 모델 크기에 대한 확장 경향을 연구하였으며, 매주 수집되는 보상 모델 데이터의 양을 점점 더 늘려가며 다양한 모델 크기를 세밀 조정하였습니다(배치 당 볼륨에 대한 세부 정보는 표 26을 참조하십시오).
- 그림 6은 이러한 경향을 보고하며, 더 많은 데이터 양에 대해 더 큰 모델이 더 높은 성능을 얻는 것으로 예상되는 결과를 보여줍니다.

- 더 중요한 것은, 훈련에 사용된 기존 데이터 주석의 양으로는 아직 스케일링 성능이 평평하지 않았다는 신호가 있으며, 더 많은 주석으로 더 많은 향상 가능성이 있다는 것을 나타냅니다.
- 보상 모델 정확도는 Llama 2-Chat의 최종 성능 중 가장 중요한 지표 중 하나입니다.
- 생성 모델을 포괄적으로 평가하는 최상의 방법은 여전히 열린 연구 질문입니다.
- 그러나 보상의 순위 작업은 모호함이 없습니다.
- 따라서 모든 것이 동일한 상황에서 보상 모델의 개선은 직접적으로 Llama 2-Chat의 개선으로 번역될 수 있습니다.
- 보상 모델을 위한 데이터가 많아지고, 보상 모델 사이즈가 커지면 reward을 좀 더 잘추정할 수 있고... 이 보상모델이 결국 llama 2-chat을 향상시킬 여지가 있다.





3.2.3 Iterative Fine-Tuning
- 우리는 더 많은 인간 선호도 데이터 주석을 받게 되면서 더 나은 보상 모델을 훈련하고 더 많은 프롬프트를 수집할 수 있었습니다.
- 그 결과, 우리는 RLHF 모델의 연속 버전인 RLHF-V1, ..., RLHF-V5를 훈련했습니다.
- 예로 RLHF-V1을 만들고 -> 이로부터 새로운 응답을 생성하고 -> rejection sampling하고 -> fine-tuning 하고 -> RLHF-V2 이런 느낌으로 하는게 아닐까 싶음
- We explored RLHF fine-tuning with two main algorithms:
- Proximal Policy Optimization (PPO) (Schulman et al., 2017)은 RLHF 문헌에서의 표준입니다.
- Rejection Sampling fine-tuning. 우리는 모델에서 K개의 출력을 샘플링하고, 우리의 보상에 따라 최상의 후보를 선택합니다. 이는 Bai 등(2022b)의 연구와 일관성이 있습니다. LLMs에 대한 동일한 재랭킹 전략은 또한 Deng 등(2019)에서 제안되었으며, 보상은 에너지 함수로 간주됩니다. 여기서는 한 걸음 더 나아가서 선택된 출력을 기울기 업데이트에 사용합니다. 각 프롬프트에 대해 가장 높은 보상 점수를 얻는 샘플이 새로운 골드 표준으로 간주됩니다. Scialom 등(2020a)의 연구와 유사하게, 우리는 그 후 등급이 매겨진 새로운 샘플 세트에서 모델을 세밀하게 튜닝하여 보상을 강화합니다.
- The two RL algorithms mainly differ in:
- Breadth - Rejection Sampling에서는 특정 프롬프트에 대해 모델이 K개의 샘플을 탐색하며, PPO에서는 한 번의 생성만 수행됩니다.
- Depth - PPO에서는 학습 단계 t에서 샘플이 이전 단계의 기울기 업데이트 후 t-1에서 업데이트된 모델 정책의 함수입니다. Rejection Sampling fine-tuning에서는 SFT와 유사한 fine-tuning을 적용하기 전에 초기 모델 정책을 기준으로 모든 출력을 샘플링하여 새로운 데이터셋을 수집합니다. 그러나 우리가 반복적인 모델 업데이트를 적용했기 때문에 두 RL 알고리즘 간의 근본적인 차이는 덜 강조됩니다.
- RLHF(V4)까지는 Rejection Sampling fine-tuning만 사용했으며, 그 이후에는 두 가지를 순차적으로 결합하여 다시 샘플링하기 전에 결과로 얻은 Rejection Sampling 체크포인트 위에 PPO를 적용했습니다.
- rejection sampling하고 이로 fine-tuning하고를 반복하다가 마지막에 PPO로 학습하는 듯
- Rejection Sampling.
- 우리는 rejection sampling을 가장 큰 70B Llama 2-Chat에서만 수행합니다.
- 모든 더 작은 모델은 큰 모델로부터 rejection sampled된 데이터로 세밀하게 튜닝되어, 큰 모델의 능력을 작은 모델로 전달합니다.
- 이 distillation의 효과에 대한 추가적인 분석은 향후 작업으로 남깁니다.
- 각 iterative 단계에서, 우리는 가장 최근 모델에서 각 프롬프트에 대해 K개의 답변을 샘플링합니다.
- 실험 시점에서 접근 가능한 최상의 보상 모델을 기준으로 각 샘플을 점수화한 후, 특정 프롬프트에 대해 최상의 답변을 선택합니다.
- 우리 모델의 이전 버전에서는, RLHF V3까지는 답변 선택을 이전 반복에서 수집한 "bag"의 샘플에만 제한하는 것이었습니다.
- 예를 들어, RLHF V3는 RLHF V2의 샘플만 사용하여 훈련되었습니다.
- 그러나 지속적인 개선에도 불구하고, 이 방법은 일부 능력의 회귀로 이어졌습니다.
- 예를 들어, 질적 분석을 통해 시의 운율이 있는 줄을 작성하는 데 이전 버전보다 더 어려움을 겪었으며, 이는 forgetting의 원인과 완화책에 대한 추가적인 미래 연구가 유익할 수 있음을 시사합니다.
- 이런 방법이 뭔가 안좋아지는 단점도 있긴 한가 봄?
- 이에 대한 응답으로, 후속 반복에서 우리는 우리의 전략을 수정하여, RLHF-V1 및 RLHF-V2에서 사용된 것과 같이 이전 모든 반복에서 성능이 우수한 샘플을 통합했습니다.
- 구체적인 숫자를 제시하지는 않았지만, 이 조정은 성능을 상당히 향상시켰으며, 이전에 언급된 문제를 효과적으로 해결했습니다.
- 이 완화책은 RL 문헌에서 Synnaeve 등(2019)와 Vinyals 등(2019)과 유사한 것으로 볼 수 있습니다.
- 특정 입력에 대해 이를 rejection sampling할 때, 이전 버전의 모델들에서 생성한 응답이 모두 reward 점수가 높다면, 이 샘플은 제외시켰다?
- 이미 학습될만큼 된 것이기 때문에 또 학습할 필요가 없다라는 그런건가?
- 우리는 Figure 7에서 거부 샘플링의 이점을 설명합니다.

- 최대 및 중앙 곡선 간의 차이는 최상의 출력에 대한 세밀한 튜닝의 잠재적 이득으로 해석할 수 있습니다.
- 예상대로, 이 차이는 더 많은 샘플로 증가합니다.
- 즉, 최대값이 증가함에 따라(더 많은 샘플, 더 좋은 경로를 생성할 기회가 더 많아짐), 중앙값은 고정됩니다.
- exploration와 샘플 중 최대 보상 사이에는 직접적인 연결이 있습니다.
- temperature 매개변수도 exploration에 중요한 역할을 합니다.
- 더 높은 temperature 는 더 다양한 출력을 샘플링할 수 있게 합니다.
- Figure 8에서는 Llama 2-Chat-SFT(왼쪽)와 Llama 2-Chat-RLHF(오른쪽)에 대한, 다른 temperature 에서 N개의 샘플 중 최대 보상 곡선을 보고합니다(N ∈ [1, . . . , 100]).

- 우리는 최적의 temperature 가 반복적인 모델 업데이트 동안 일정하지 않음을 관찰할 수 있습니다: RLHF는 temperature 의 재조정에 직접적인 영향을 미칩니다.
- Llama 2-Chat-RLHF의 경우, 10에서 100개의 출력을 샘플링할 때 최적의 temperature는 T ∈ [1.2, 1.3]입니다.
- 유한한 계산 예산이 주어진 경우, temperature 를 점진적으로 다시 조정하는 것이 필요합니다.
- 이 temperature 재조정은 각 모델에 대해 일정한 단계로 이루어지며, 새로운 RLHF 버전마다 기본 모델에서 시작됩니다.
- temperature을 어떤 값을 하냐에 따라 모델의 출력에 대한 reward가 달라지는데.. 최적의 temperature은 model version에 따라 또 따르다?
- 여기서 보상모델은 어떤 보상모델을 말하는거지? 두 개의 보상모델을 더한건가 그냥?
- PPO.
- 우리는 Stiennon 등의 RL 방법(2020)을 따라 우리의 언어 모델을 추가로 훈련합니다.
- 이 방법은 보상 모델을 true reward function (human preference)의 추정값으로 사용하고, 사전 훈련된 언어 모델을 최적화할 정책으로 사용합니다.
- 이 단계에서는 다음 목표를 최적화하고자 합니다:

- 우리는 데이터셋 D에서 프롬프트 p를 샘플링하고 정책 π에서 생성물 g를 샘플링함으로써 정책을 반복적으로 개선합니다.
- 이를 위해 PPO 알고리즘과 손실 함수를 사용하여 이 목표를 달성합니다.
- 최종 보상 함수는 최적화 중에 사용되며, 원래 정책 π0에서 벗어나는 것에 대한 penalty 항을 포함합니다.

- 다른 연구에서 관찰된 것처럼, 이 제약 조건은 훈련의 안정성을 높이고 보상 모델에서 높은 점수를 얻더라도 인간 평가에서 낮은 점수를 받는 보상 조작을 줄이는 데 유용하다는 것을 발견했습니다.
- 우리는 Rc를 안전(Rs) 및 유용성(Rh) 보상 모델의 조합으로 정의합니다.
- 하나의 보상값으로 만들어서 이를 활용한듯
- 데이터셋에서 잠재적으로 위험한 응답을 유발할 수 있는 프롬프트를 태그하고, 안전 모델의 점수를 우선시합니다.
- 0.15의 임계값은 위험 응답을 필터링하기 위해 선택되었으며, 이는 Meta Safety 테스트 세트에서 평가된 정밀도 0.89 및 리콜 0.55에 해당합니다.
- 또한 최종 선형 점수를 백색화하는 것이 중요하다는 것을 발견했는데, 이는 위의 KL 벌칙 항 (β)과 적절하게 균형을 이루고 안정성을 높이기 위해 여기서는 로짓(logit) 함수를 사용하여 시그모이드를 뒤집어 보여줍니다.

- 위험한 응답 (룰베이스 프롬프트 체크 or 임계값 < 0.15) -> safey reward가 전체 보상값이 됨
- 그 외는 유용성이 전체 보상값이 됨
- 모든 모델에 대해 우리는 AdamW 옵티마이저(Loshchilov 및 Hutter, 2017)를 사용합니다.
- 이 때 β1 = 0.9, β2 = 0.95, eps = 10−5 로 설정합니다.
- 가중치 감쇠(weight decay)는 0.1, 그래디언트 클리핑(gradient clipping)은 1.0, 그리고 일정한 학습률은 10−6 입니다.
- 각 PPO 반복(iteration)에 대해 배치 크기는 512, PPO 클립 임계값은 0.2, 미니배치 크기는 64로 설정하며, 미니배치당 하나의 그래디언트 단계를 취합니다.
- 7B 및 13B 모델의 경우, β = 0.01 (KL 벌칙)로 설정하고, 34B 및 70B 모델의 경우, β = 0.005로 설정합니다.
- 우리는 모든 모델에 대해 200에서 400 사이의 반복으로 훈련하며, 조기 종료를 위해 보류된(held-out) 프롬프트에 대한 평가를 사용합니다.
- 70B 모델의 각 PPO 반복은 평균적으로 약 330초가 소요됩니다.
- 큰 배치 크기로 빠르게 훈련하기 위해 FSDP(Zhao 등, 2023)를 사용합니다.
- 이것은 O(1) 전방향 또는 역방향 전파를 사용할 때 효과적이었지만, 생성 과정에서 큰 지연(약 20배)을 유발했습니다.
- 심지어 큰 배치 크기와 KV 캐시를 사용할 때에도 그렇습니다.
- 우리는 이를 완화하기 위해 생성 전에 모델 가중치를 각 노드로 통합하고, 생성 후 메모리를 해제하여 훈련 루프의 나머지를 재개할 수 있었습니다.





3.3 System Message for Multi-Turn Consistency
- 대화 설정에서는 대화의 모든 턴에 대해 일부 지침이 적용되어야 합니다.
- 예를 들어, 간결하게 응답하거나 특정 인물로 "역할"을 수행하는 것입니다.
- 우리가 Llama 2-Chat에 이러한 지침을 제공하면, 그 다음 응답은 항상 해당 제약을 준수해야 합니다.
- 그러나 초기 RLHF 모델은 대화 몇 턴 후에 초기 지침을 잊어버리는 경향이 있었습니다.
- 이러한 한계를 해결하기 위해 우리는 Ghost Attention (GAtt)이라는 매우 간단한 방법을 제안합니다.
- 이는 Context Distillation (Bai 등, 2022b)에서 영감을 받은 방법으로, 다단계 프로세스에서 주의력을 돕기 위해 미세 조정 데이터를 해킹합니다.
- GAtt은 대화 제어를 여러 턴에 걸쳐 가능하게 합니다. (Figure 9 (right)에서 설명된 것과 같이)

- GAtt Method.
- 가정해 봅시다.
- 우리는 두 사람 간의 다중 턴 대화 데이터셋에 액세스할 수 있습니다(예: 사용자와 어시스턴트).
- 이 데이터셋은 메시지 목록 [u1, a1, . . . , un, an]로 구성되어 있습니다.
- 여기서 un과 an은 각각 턴 n에 대한 사용자 및 어시스턴트 메시지에 해당합니다.
- 그런 다음 우리는 지침 inst를 정의합니다.
- 이 지침은 대화 전체에 걸쳐 준수되어야 합니다.
- 예를 들어, inst는 "역할을 하다"일 수 있습니다.
- 그런 다음 이러한 지침을 대화의 모든 user messages에 합성적으로 연결할 수 있습니다.
- 다음으로, 최신 RLHF 모델을 사용하여 이 합성 데이터에서 샘플을 추출할 수 있습니다.
- 이제 우리는 샘플을 사용하여 모델을 미세 조정할 수 있는 컨텍스트-대화를 가지게 되었습니다.
- 이것은 Rejection Sampling과 유사한 과정입니다.
- 즉 기존의 데이터세트는, 특정 역할을 하는 쌍이 아니니까, 이러한 쌍의 데이터세트를 최신 RLHF 모델을 통해 샘플링하는 것이다.
- 샘플링할 때는, 직전 유저의 발화에 inst을 붙여서 다음의 ak(assistance) 대답을 추출한 듯?
- 컨텍스트-대화의 모든 턴에 지침을 보충하는 대신, 첫 번째 턴을 제외한 모든 턴에서는 이를 삭제할 수 있습니다.
- 샘플링한 데이터로 모델을 학습할땐 첫번째에만 inst 유지하고 나머지 턴에선 다시 제외
- 그러나 이는 시스템 메시지(즉, 마지막 턴 이전에 오는 모든 중간 어시스턴트 메시지)와 샘플 간에 학습 시 불일치를 초래할 수 있습니다.
- 학습에 영향을 미칠 수 있는 이 문제를 해결하기 위해, 우리는 이전 턴의 모든 토큰(어시스턴트 메시지 포함)에 대한 손실을 간단히 0으로 설정합니다.
- 훈련 지침에는 샘플링할 수 있는 몇 가지 합성적 제약 조건을 만들었습니다:
- 취미 ("예: 테니스를 좋아합니다"), 언어 ("예: 프랑스어로 말하세요"), 또는 공인 인물 ("예: 나폴레옹으로 행동하세요").
- 취미와 공인 인물의 목록을 얻기 위해 Llama 2-Chat에게 생성하도록 요청하여 지침과 모델 지식 사이의 불일치를 피했습니다(예: 모델에게 훈련 중에 만나지 못한 사람으로 행동하도록 요청하지 않음).
- 지침을 더 복잡하고 다양하게 만들기 위해 우리는 위의 제약 조건을 무작위로 결합하여 최종 지침을 구성합니다.
- 훈련 데이터의 최종 시스템 메시지를 구성할 때 우리는 종종 원래 지침을 더 간단하게 수정합니다.
- 예: "지금부터 항상 나폴레옹으로 행동하십시오"-> "인물: 나폴레옹." 이러한 단계는 Llama 2-Chat를 미세 조정할 수 있는 SFT 데이터셋을 생성합니다.
- GAtt Evaluation.
- 우리는 RLHF V3 이후에 GAtt를 적용했습니다.
- 우리는 최대 컨텍스트 길이에 도달할 때까지(별지 A.3.5 참조) GAtt가 20회 이상의 턴에 대해 일관된 것으로 나타내는 정량적 분석을 보고했습니다.
- 우리는 GAtt의 훈련 중에 없던 제약 조건을 추론 시에 설정해 보았는데, 예를 들어 "하이쿠로 항상 답변하십시오"와 같은 경우 모델이 일관된 결과를 유지했습니다(Appendix Figure 28 참조).
- GAtt가 미세 조정 중에 어떻게 주의를 재구성하는 데 도움이 되었는지를 설명하기 위해, 모델의 최대 주의 활성화를 Figure 10에 표시했습니다.

- 각 그림의 왼쪽은 시스템 메시지("Oscar Wilde로 행동하십시오")에 해당합니다.
- GAtt가 장착된 모델(오른쪽)은 GAtt가 없는 모델(왼쪽)에 비해 대화의 더 큰 부분에 걸쳐 시스템 메시지에 대한 큰 주의 활성화를 유지함을 볼 수 있습니다.
- 그러나 현재의 GAtt 구현은 기본적인 수준이며, 이 기술에 대한 더 많은 개발과 반복이 모델에 더 많은 이점을 가져다 줄 것으로 보입니다.
- 예를 들어, 우리는 모델이 미세 조정 중에 대화 중에 시스템 메시지를 변경하도록 가르칠 수 있습니다.


3.4 RLHF Results
3.4.1 Model-Based Evaluation
- LLM(Large Language Models)의 평가는 어려운 오픈 리서치 문제입니다.
- 인간 평가는 골드 스탠다드이지만, 다양한 HCI 고려 사항(Clark et al., 2021; Gehrmann et al., 2023)으로 복잡해질 수 있으며, 항상 확장 가능하지는 않습니다.
- 따라서 RLHF-V1에서 V5까지의 여러 수정 중에서 최상의 성능을 보이는 모델을 선택하기 위해, 우리는 먼저 최신 보상 모델로부터의 보상 개선을 관찰하여 비용을 절감하고 반복 속도를 높였습니다.
- 그 후에 우리는 주요 모델 버전을 인간 평가로 검증했습니다.
- How Far Can Model-Based Evaluation Go?
- 우리의 보상 모델의 견고성을 측정하기 위해, 우리는 도움이 되는 정도와 안전성에 대한 프롬프트의 테스트 세트를 수집하고, 세 명의 어노테이터에게 7점 Likert 척도를 기반으로 답변의 품질을 판단하도록 요청했습니다(점수가 높을수록 좋음).
- 우리는 우리의 보상 모델이 전반적으로 우리의 인간 선호도 주석과 잘 균형이 맞는 것을 관찰했습니다.
- 이는 부분적 랭킹 손실로 훈련되었음에도 불구하고 우리의 보상을 점수 기준 메트릭으로 사용하는 것의 타당성을 확인합니다. (부록의 도 29에 나와 있는대로)
- 그러나 Goodhart의 법칙에 따르면, 어떤 측정이 목표가 되면 좋은 측정이 되지 않는다고 합니다.
- 우리의 측정이 인간의 선호도와 차이가 나지 않도록 보장하기 위해, 우리는 다양한 오픈 소스 보상 모델링 데이터셋에서 훈련된 보다 일반적인 보상도 추가로 사용했습니다.
- 우리는 아직 그러한 이탈을 관찰하지 못했으며, 이러한 이탈을 방지하는 데 반복적인 모델 업데이트가 도움이 되고 있을 것으로 가설을 세웁니다.
- 우리의 새로운 모델과 이전 모델 간의 회귀가 없는지 확인하기 위한 마지막 검증 단계로, 우리는 다음 어노테이션 반복 중에 둘 다 샘플링하는 데 사용합니다.
- 이렇게 함으로써 새로운 프롬프트에서 모델 비교를 "무료"로 수행할 수 있으며, 샘플링 시 다양성을 높일 수 있습니다.
- Progression of Models.
- 도표 11은 우리의 다양한 SFT 및 RLHF 버전의 진행 상황을 보고합니다.

- 이 그림이 iterative하게 모델학습했을때 효과를 잘보여주는거 같음
- chatgpt와 비교해서 얼마나 더좋은지를 보여주는 그래프임
- 여기서 RLHF-v4 (with PPO)전까지는 rejection sampling만을 의미하는 것이라 보면 될듯
- 이는 우리의 내부 안전 및 도움이 되는 보상 모델로 측정되며, 안전성과 도움이 되는 축 모두에 대해 ChatGPT를 RLHF-V3 이후에 능가합니다(해로움 없음 및 도움 >50%).
- 앞서 언급한 바와 같이 우리의 보상을 점수 기준 메트릭으로 사용하는 것의 타당성에도 불구하고, 이는 아마도 Llama 2-Chat에 호의적인 편향될 수 있다고 주장할 수 있습니다.
- 그러므로 공정한 비교를 위해 우리는 GPT-4를 추가로 사용하여 어떤 세대가 선호되는지를 평가합니다.
- ChatGPT와 Llama 2-Chat 출력이 GPT-4 프롬프트에 나타나는 순서는 어떤 편향도 없도록 무작위로 바꿉니다.
- 예상대로, Llama 2-Chat의 승리 비율은 덜 두드러지지만, 최신 Llama 2-Chat에 대해 60% 이상의 승리 비율을 얻습니다.
- 프롬프트는 각각 안전성과 유용성에 대한 1, 586 및 584 프롬프트의 검증 세트에 해당합니다.

3.4.2 Human Evaluation
- 인간 평가는 자연어 생성 모델, 특히 대화 모델의 품질을 판단하는 데 골드 스탠다드로 간주됩니다.
- 주요 모델 버전의 품질을 평가하기 위해 우리는 인간 평가자들에게 도움이 되는 정도와 안전성에 대해 평가하도록 요청했습니다.
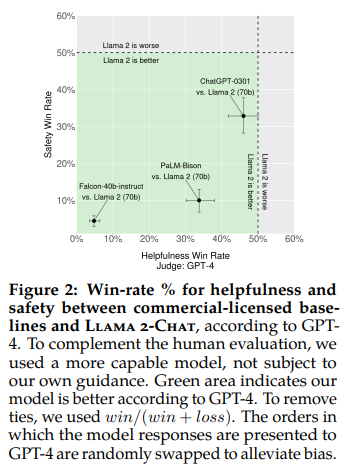
- 우리는 Llama 2-Chat 모델을 오픈 소스 모델(Falcon, MPT MosaicML NLP Team et al. (2023), Vicuna Chiang et al. (2023))과 클로즈드 소스 모델(ChatGPT (OpenAI, 2023) 및 PaLM Anil et al. (2023))과 비교했습니다.
- 이를 위해 4,000개 이상의 단일 및 다중 턴 프롬프트를 사용했습니다. ChatGPT의 경우 모든 세대에서 gpt-3.5-turbo-0301 모델을 사용했습니다.
- PaLM의 경우 chat-bison-001 모델을 모든 세대에서 사용했습니다.
- 각 모델에 대한 인간 평가의 최종 프롬프트 개수는 테이블 32에 표시되어 있습니다.
- 방법론의 자세한 내용은 부록 A.3.7절을 참조하십시오.
- 다음 섹션에서는 도움이 되는 결과를 보여주며, 안전성 결과는 섹션 4.4에서 제시됩니다.
- Results.
- 도표 12에 나와 있는 것처럼, Llama 2-Chat 모델은 단일 턴 및 다중 턴 프롬프트 양쪽에서 오픈 소스 모델보다 상당한 차이로 우수한 성능을 보입니다.

- 특히, Llama 2-Chat 7B 모델은 MPT-7B-chat보다 60%의 프롬프트에서 우수한 성능을 보입니다. Llama 2-Chat 34B는 Vicuna-33B와 Falcon 40B 모델과 같은 크기의 모델에 대해 전체적인 승리 비율이 75% 이상입니다.
- 가장 큰 Llama 2-Chat 모델은 ChatGPT와 경쟁력이 있습니다.
- Llama 2-Chat 70B 모델은 ChatGPT에 대해 승리 비율이 36%이고 무승부 비율이 31.5%입니다.
- Llama 2-Chat 70B 모델은 우리의 프롬프트 세트에서 PaLM-bison chat 모델보다 많은 비율로 우수한 성능을 보입니다.
- 추가 결과 및 분석은 부록 A.3.7에서 확인할 수 있습니다.
- 이 시점기준 Llama 2-chat이 오픈소스에선 제일 좋다고 보면 되고 chatgpt 수준이라고 보면 될듯
- Inter-Rater Reliability (IRR).
- 우리의 인간 평가에서 각 모델 세대 비교에 대해 세 명의 다른 어노테이터가 독립적인 평가를 제공했습니다.
- 높은 IRR 점수(1.0에 가까운)는 일반적으로 데이터 품질 관점에서 더 나은 것으로 간주됩니다.
- 평가자끼리 얼마나 유사한지를 보는 느낌인듯
- 그러나 맥락은 중요합니다.
- LLM 생성의 전반적인 도움이 되는 정도를 평가하는 것과 같이 매우 주관적인 작업은 일반적으로 더 객관적인 라벨링 작업보다 낮은 IRR 점수를 갖게 될 것입니다.
- 이러한 맥락에 대한 공개 벤치마크는 상대적으로 적기 때문에, 우리는 여기서 우리의 분석을 공유하는 것이 연구 커뮤니티에 도움이 될 것으로 생각합니다.
- 우리는 다양한 측정 시나리오에서 가장 안정적인 메트릭으로 Gwet의 AC1/2 통계량(Gwet, 2008, 2014)을 사용하여 상호 평가자 신뢰성(IIR)을 측정했습니다.
- 우리 분석에 사용된 7점 Likert 척도 도움이 되는 작업에서, Gwet의 AC2 점수는 특정 모델 비교에 따라 0.37에서 0.55 사이로 변동합니다.
- 서로 유사한 이긴 비율을 가진 모델 비교(예: Llama 2-Chat-70B-chat 대 ChatGPT 비교)에서 모델 비교의 평가 점수는 해당 범위의 하위쪽에 있습니다.
- 더 명확한 승자가 있는 모델 비교(예: Llama 2-Chat-34b-chat 대 Falcon-40b-instruct 비교)에서 모델 비교의 평가 점수는 해당 범위의 상위쪽에 있습니다.
- Limitations of human evaluations.
- 우리의 결과는 Llama 2-Chat이 인간 평가에서 ChatGPT와 동등한 수준임을 보여주지만, 인간 평가에는 여러 가지 제한이 있음을 강조해야 합니다.
- • 학술 및 연구 기준으로 우리는 4,000개의 프롬프트로 구성된 큰 프롬프트 세트를 보유하고 있습니다. 그러나 이는 이러한 모델의 실제 사용을 다루지 않으며, 실제 사용 사례는 훨씬 많을 것으로 예상됩니다.
- • 프롬프트의 다양성은 결과에 다른 요인일 수 있습니다. 예를 들어, 우리의 프롬프트 세트에는 코딩이나 추론과 관련된 프롬프트가 포함되어 있지 않습니다.
- • 우리는 다중 턴 대화의 최종 생성만을 평가합니다. 더 흥미로운 평가는 모델에게 작업을 완료하도록 요청하고 여러 턴에 걸친 모델과의 전체적인 경험을 평가하는 것일 수 있습니다.
- • 생성 모델에 대한 인간 평가는 본질적으로 주관적이고 잡음이 많습니다. 결과적으로, 다른 프롬프트 세트나 다른 지침으로 평가하면 다른 결과가 나올 수 있습니다.

4 Safety
- WARNING: this section contains examples of text that may be considered unsafe, offensive, or upsetting.
- In this section, we dive deeper into the important topic of safety measurements and mitigations. We first discuss our safety investigations into pretraining data and pretrained models (Section 4.1). Next, we describe the process of our safety alignment (Section 4.2), explaining how we collected safety-related annotations and utilized SFT and RLHF, and present experimental results. Then, we discuss the red teaming we performed to further understand and improve model safety (Section 4.3). Finally, we present quantitative safety evaluations of Llama 2-Chat (Section 4.4). We also share a model card in the Appendix, in Table 52.

















Reference
댓글
댓글 쓰기