NL-208, Taxonomy and Analysis of Sensitive User Queries in Generative AI Search, Review (NAVER)
◼ Comment
- 전체적으로 페이지 limit 이슈땜에 부록으로 넘긴 부분이 꽤 있는 느낌을 받긴 했네요.
- 전체적인 논문 흐름은 딱히 이상한 점 없는거 같아요.
- 1. Introduction
- - Furthermore, researchers have observed that the models understand human instructions in natural language formats, which makes general people easy to use AI models.
- : researcher --> previous researches/works
- : general people --> non-expert people
- - Despite the benefits, only a few affiliations could successfully launch services based on LLMs and maintain them.
- : them에 NAVER도 넣으심이? 어차피 hyperclova쓰고 말하는거보면 NAVER인거 다 알거 같아서
- - However, the gaps could be covered if we negotiate the model size or use a publicly-opened pretrained model and fine-tune it.
- : reference나 이런 사례(오픈 소스 예시)들을 같이 말해주면 좋을 것 같습니다.
- - Since people generally consider generative models as human-like assistants interacting with conversation, the inputs (in our case, search query log) might be similar regardless of application type while the outputs could be different according to the purpose of the system.
- We thus believe the information on input module is helpful to build any kinds of applications.
- : GenAI을 인간처럼 대해서 입력은 비슷할지어도, 출력은 목적에 따라 다를 수 있다. --> 그래서 우리는 입력 정보가 어플리케이션 만드는데 도움이 된다.
- : 이 두 문장의 맥락이 약간 이해가 안됩니다. 차라리 "GenAI의 입력들은 비슷하지만, 입력을 분석하는게 어플리케이션에 도움이 된다." 라고 짧게 바꾸는것도 괜찮아 보입니다.
- - 입력쪽에서 컨트롤하는거랑 출력쪽에서 컨트롤하는거의 차이에 대해서 언급하면 좋지 않을까?
- : 출력쪽에서 컨트롤하는것은 무슨 무슨 어려움이 있다는지
- : 혹은 입력쪽에서 컨트롤하는게 더 쉽고, 인퍼런스를 안해버려서 값싸다는 장점이 있는지
- : 또한 분류기에 걸려서 답변안하는 쿼리는 어떤 응답을 내보내는지 / 어떻게 처리하는 지에 언급해줘도 좋을 것 같습니다.
- 4 Sensitive Query Classification
- - 본문만 봤을 때는, Question과 Reasoning 사이를 건드는데 LLM 내용이 왜 나오지 했습니다.
- - 부록을 보면 Hyperclova를 학습해서 이를 분류기로 쓰는거 같더라구요.
- - 근데 이 부분이 그래도 모델 부분인데 너무 부록에 있지 않나 싶습니다 ㅋㅋ 본문에 간단히 언급해주시면 좋을거 같긴 한데 말이죠
- - 그리고 이런 분류문제는 사실 small model (BERT와 같은)거 써도 성능이 충분할거 같고 속도도 훨씬 빠를텐데, 왜 하이퍼클로바 LLM을 썼는지 직관적으로 이해가 되지는 않았습니다. (장단점이 있을텐데 말이죠)
- 당연히 중요한 부분을 본문으로 넣으셨겠지만 ㅋㅋ 용지가 부족하다면 그나마 Table 1의 사이즈를 줄이거나 얘를 부록으로 넣는 것이 어떨까요? 너무 비중이 커보이네요
Abstract
- 제너레이티브 모델의 성능이 향상되고 프롬프트 엔지니어링이 일반인들이 사용하기 쉽게 만들어지면서 산업 분야에서도 이러한 모델을 서비스에 적용하려는 시도가 늘어나고 있습니다.
- 그러나 리소스와 경험 사이에는 간극이 있어 소수의 기업만이 제너레이티브 모델 서비스를 구축할 수 있었습니다.
- 본 논문에서는 국가 규모의 검색 엔진을 기반으로 한 제너레이티브 모델의 구축 및 운영 경험을 공유합니다.
- 특히 입력 쿼리에 중점을 두었으며, 해당 서비스는 서비스에 독립적입니다.
- 우리는 민감한 검색 쿼리에 대한 사전 정의된 카테고리를 제안하고, 이를 기반으로 민감한 쿼리 분류기와 성능을 향상시키기 위한 인간 중심의 피드백을 구축했습니다.
- 분석에서는 일반 사용자 정보를 제공하고 입력 쿼리와 그 민감성의 분포를 심층적으로 조사합니다.
1 Introduction
- BERT(Devlin et al., 2019)를 시작으로, Transformer 아키텍처에 대한 사전 훈련(Vaswani et al., 2017)은 많은 훈련 데이터와 모델 파라미터의 결합, 일명 대형 언어 모델(Large Language Models, LLMs)이 다양한 자연어 처리 작업에서 높은 성능을 보인 새로운 패러다임을 열었습니다.
- 이 중에서도 GPT와 같은 자기 회귀 아키텍처(Radford et al., 2019; Brown et al., 2020; OpenAI, 2023)는 이러한 생성 모델이 하향 작업에서 인간 수준의 성능에 도달하는 강력한 영향을 보여주었습니다.
- 더불어 연구자들은 이러한 모델이 자연어 형식의 인간 지시를 이해한다는 것을 관찰하였으며(Victor et al., 2022; Wei et al., 2022; Kojima et al., 2022; 등), 이로써 일반인들이 AI 모델을 쉽게 사용할 수 있게 되었습니다.
- researcher? -> previous research or AI community
- general people? -> non-expert people
- 접근성과 높은 성능으로 인해 사람들은 다양한 목적으로 GPT 서비스를 널리 사용하고 있습니다.
- 이러한 흐름을 따라 산업도 자사의 분야에 생성 모델을 적용하려는 시도를 하고 있습니다.
- 혜택에도 불구하고, 대형 언어 모델(Large Language Models, LLMs)을 기반으로 한 서비스를 성공적으로 출시하고 유지하는 것은 소수의 소속에만 성공한 것으로 나타났습니다.
- NAVER은 왜뺌?ㅋㅋ
- NAVER랑 알리바바 넣는건 어떰
- 이러한 성공의 주요 이유 중 하나는 사전 훈련 및 파인튜닝 데이터, 컴퓨팅 리소스(예: GPU 및 서버), 그리고 인적 노동(예: 엔지니어 및 라벨러 수)와 같은 자원에 대한 큰 격차 때문입니다.
- 예를 들어, 사전 훈련 측면에서 Narayanan et al. (2021)는 34일 동안 300B 토큰을 훈련시키려면 1,024개의 A100 GPU가 필요하다고 언급했습니다.
- 그러나 이러한 차이는 모델 크기를 협상하거나 공개된 사전 훈련 모델을 사용하고 이를 파인튜닝하는 방식으로 극복될 수 있습니다.
- ref있으면 좋지 않을가
- 그러나 우리는 경험 또한 장벽이라고 강하게 믿고 있습니다.
- 우리의 지식으로는 이전 연구 중 어느 것도 생성 애플리케이션 서비스를 구축하고 출시하는 데 필요한 지식에 대해 다루지 않았습니다.
- 대신 연구는 대부분 사전 훈련 및 파인튜닝 방법(Zhang et al., 2022; Chowdhery et al., 2023; Touvron et al., 2023; 등)이나 데이터 측면(Zhou et al., 2023)에 중점을 두고 있습니다.
- 따라서 우리는 LLM 기반 서비스를 구축하는 경험이 장벽을 낮출 수 있을 것으로 기대하고 있습니다.
- 경험이 얼마나 잘 녹여져 있는지 보면 될 듯
- 그러나 대부분의 산업 시스템은 비밀이기 때문에 세부 사항은 거의 공개되지 않습니다.
- 이로 인해 본 논문의 범위를 생성 애플리케이션 서비스의 입력 모듈로 제한합니다.
- 일반적으로 사람들은 생성 모델을 대화 상호작용을 하는 인간과 유사한 어시스턴트로 간주하기 때문에, 입력(우리의 경우 검색 쿼리 로그)은 시스템의 목적에 따라 출력이 다를 수 있지만 일반적으로 유사할 것으로 생각됩니다.
- 살짝 이해가 안됨
- GenAI을 인간처럼 대하기 때문에 시스템에 상관없이 입력의 형태가 비슷할 것이다?
- 따라서 우리는 입력 모듈에 대한 정보가 어떠한 종류의 응용 프로그램을 구축하는 데 도움이 될 것이라고 믿고 있습니다.
- 입력 모듈의 정보가 어플리케이션을 만드는데 도움이 된다?
- 게다가, 이전 연구들 중 많은 부분이 생성 모델 응답의 안전성을 검증했지만(Ousidhoum et al., 2021; Wei et al., 2023; Kumar et al., 2023b; 등), 입력 질문의 안전성을 고려한 연구는 거의 없었습니다(Qi et al., 2021; Kumar et al., 2023a).
- 본 논문에서는 생성 애플리케이션 시스템의 입력 부분, 특히 쿼리 민감성에 관한 부분을 설명할 것입니다.
- 이를 통해 사용자가 시스템을 어떻게 활용(또는 공격)하는지에 대한 통찰력을 제공하여, 서비스를 구축하고 운영하는 데 중요한 요소를 이해할 수 있습니다.
- 또한, 연구자들이 민감한 입력과 관련된 정책(카테고리), 모델, 서비스 규모 등의 측면에서 입력 모듈을 어떻게 구성해야 하는지에 대한 교훈을 얻을 수 있기를 희망합니다.
- 이 작업은 최종적으로 미래 연구에 필요한 요구 사항을 추정하는 데 참고 자료가 될 수 있습니다.
- We claim the contributions as follows:
- 우리는 국가 규모의 검색 엔진을 기반으로 한 생성 LLM 서비스의 상대적으로 서비스에 독립적인 입력 모듈을 구축하는 경험을 공유합니다.
- 우리는 서비스 사용자가 생성 시스템에 입력하는 검색 쿼리 로그를 조사합니다. 이를 통해 (1) 서비스에 대한 사용자 패턴을 보여주고, (2) 생성 검색 엔진을 위한 민감한 쿼리의 분류 체계를 제안하며, (3) 해당 분류에 따른 검색 로그의 분포를 제시하여 민감한 검색 쿼리를 다루는 다른 연구자들에게 도움이 되도록 합니다.
- 입력쪽에서 컨트롤하는거랑 출력쪽에서 컨트롤하는거의 차이에 대해서 언급하면 좋지 않을까?
- 출력쪽에서 컨트롤하는것은 무슨 무슨 어려움이 있다는지
- 입력쪽에서 컨트롤하는게 더 쉽고, 인퍼런스를 안해버려서 값싸다는지
- 혹은 민감분류기에 걸려서 답변안하는 쿼리에 대해 처리하는 방법에 대해서도 언급해주면 좋지 않을까?
2 Search based Generative Application
- 먼저 이 문서의 이해를 돕기 위해 전체 시스템을 간략하게 살펴보겠습니다.
- Search Engine.
- 1999년 이후로, 저희 서비스는 주로 한국을 기반으로 하며, 주요 구성 요소는 검색 엔진이 있는 포털 사이트입니다.
- 이 포털에는 이메일 서비스, 블로그, 뉴스, 그리고 사용자 커뮤니티가 통합되어 있습니다.
- 정교한 데이터베이스를 활용하여 검색 엔진은 키워드 일치를 통해 적절한 웹 페이지를 찾아내고 나열합니다.
- 한국에서는 2023년 8월 기준으로 저희 서비스가 68.9%의 시장 점유율을 차지하고 있으며, Google은 23.6%의 시장 점유율을 가지고 있습니다.
- Generative Application Flow.
- 생성 애플리케이션은 사용자의 검색 목적을 달성하기 위해 설계되었습니다.
- 그림 1은 생성 애플리케이션이 전통적인 검색 엔진과 어떻게 작동하는지를 대략적으로 보여줍니다.
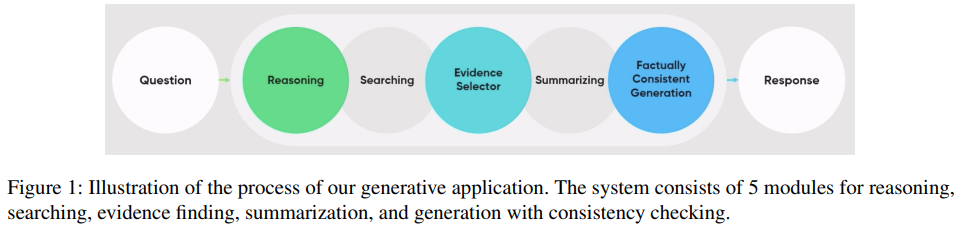
- 먼저, 전략을 설정하기 위해 시스템은 인간의 추론 과정을 모방합니다.
- 1) 이 결과는 검색 엔진의 검색 키워드로 사용되어 다양한 출처에서 여러 웹 페이지와 문서를 검색합니다.
- 2) 증거 선택기는 입력 질문에 대한 가능한 답변을 포함하는 문서를 선택합니다.
- 3) 선택된 문서는 요약 모델을 통과하며, 출력 텍스트는 응답 생성의 맥락으로 사용됩니다.
- 4) 응답 생성 전에 시스템은 사실 일관성을 확인하여 신뢰할 수 있는 결과를 생성합니다.
- 5) 마지막으로, 시스템은 다차원적인 방식으로 사용자의 질문에 응답합니다.
- 시스템의 일부로서, 우리의 민감한 쿼리 분류기는 Figure 1에서 Question과 Reasoning모듈 사이의 최상단에 위치하고 있습니다.
- 저 사이에 들어가는 부분에 대해서 설명한다는 것
- 이 분류기는 검색 쿼리가 민감한지 여부를 결정하여 응답을 생성할지 여부를 결정합니다.

3 Taxonomy of Sensitive Queries
- 쿼리 민감도는 쿼리 자체의 해로움과 함께 서비스에서 생성된 잠재적인 응답의 사회, 경제 및 정치적 영향의 정도를 포함합니다.
- 민감도의 정의는 서비스의 목적 및 서비스 영역의 문화에 따라 다를 수 있지만, 이러한 변형을 포함하는 포괄적인 커버리지를 가질 가치가 있다고 생각합니다.
- 이를 위해 우리는 openAI, Google, 그리고 Meta를 포함한 주요 LLM 기반 서비스 제공 업체들의 지침 세트를 검토하였으며, 또한 한국에서의 AI 안전 영역에 대한 이전 연구(이 등, 2023a,b)를 검토하였습니다.
- 그 후에는 회사의 검색 엔진 서비스 경험과 내부적으로 논의한 생성 기반 AI 서비스 사용 시나리오에 대한 기대를 바탕으로 재평가하고 수정하였습니다.
- 우리는 기업 서비스 및 사회적 책임 측면에서 특히 쿼리 및 응답의 잠재적인 문제의 성격에 따라 3가지 고수준 민감도 영역을 제시합니다:
- (1) 법적, (2) 윤리적, 그리고 (3) 서비스 민감한 문제.
3.1 Legal issues
- Felony crimes
- 중죄로 분류된 범죄 행위를 장려하거나 준비하는 것과 관련된 쿼리, 이에는 폭행, 절도, 살인, 납치, 강간, 사기, 불법 마약 거래 및 유사한 범죄가 포함됩니다. 아래에서 명시되지 않는 한, 이 범주에는 사실적인 현상이나 정의와 관련된 조회가 포함되지 않습니다. 예를 들어, 어떻게 사람이 마약을 사용하면 어떤 느낌이 드는지와 같은 내용은 이 범주에 포함되지 않습니다.
- Age-restricted contents
- 나이 제한 콘텐츠에 관한 쿼리, 이에는 Restricted(한국), R18+(일본), R(미국) 및 동등한 등급의 콘텐츠(예: 노출, 비속어, 어린이에게 부적절한 기타 자료)가 포함됩니다.
- Privacy
- 사회 보장 번호, 집 주소, 개인 전화번호 등 특정 개인의 개인 식별 가능한 또는 비공개 정보에 관한 조회와 관련된 쿼리로 개인 정보 유출 가능성이 있습니다. 공개적으로 및 공식적으로 제공 가능한 정보에 관한 조회는 안전한 것으로 간주됩니다.
- Minor copyright infringement
- 소규모의 저작권 위반이나 지적재산권 침해로 이어질 수 있는 쿼리입니다. 이에는 "어디에서 무료로 넷플릭스를 볼 수 있나요?"와 같이 무단으로 저작물에 접근하려는 조회가 포함됩니다. 이 범주는 일반적인 검색 엔진 서비스의 주요 도전 과제이며, 따라서 다른 중죄 범죄와 별도로 처리됩니다.
3.2 Ethical issues
- Discrimination
- 인종, 국적, 지역, 나이, 장애, 성별, 성적 성향, 종교, 직업, 질병 등과 같은 특성을 기반으로 차별을 장려하거나 정당화하는 쿼리입니다. 이에는 특정 그룹에 대한 증오를 유발하거나 부추기는 조회뿐만 아니라 차별적인 방식으로 개인 또는 그룹을 비교하는 조회도 포함됩니다.
- Suicide and self-harm
- 자살이나 자해와 관련된 쿼리로, 자해를 유발할 수 있는 상세한 지침, 의도 또는 상황에 대한 조회를 포함합니다. 통계와 같은 일반적인 조회는 포함되지 않습니다. 고객과의 대화나 검색 서비스는 법적 및 사회적 책임 관점에서 이 문제에 상당한 주의를 기울여야 합니다.
- Profanity
- 시스템이나 시스템에 대한 모욕적인 언어를 포함한 쿼리, 또는 시스템이 그러한 언어를 생성하거나 표시하도록 요청하는 쿼리는 차단되어야 합니다. 이 범주는 시스템과의 상호 작용에서 부적절하거나 모욕적인 콘텐츠 사용을 방지하기 위한 것입니다.
- Personification of the system
- 시스템을 인간으로 가정하거나 시스템에게 "Could you climb?"와 "제 남자/여자 친구처럼 행동해봐"와 같이 시스템의 능력을 넘어서는 작업을 수행하도록 요청하는 쿼리는 민감한 영역에 속합니다. 그러나 시스템이 미리 정의된 능력 내에서 정보를 제공하거나 콘텐츠를 생성하도록 요청하는 쿼리(예: 글쓰기)는 민감한 측면으로 고려할 필요가 없습니다.
- AI한테 사람과 같은 걸 요구하는 것에 대한 필터링
3.3 Service-sensitive issues
- High-stakes domains
- 건강 및 법률과 같은 특정 고위험 분야에서는 정확성과 권위 있는 소스에 대한 의존이 최우선입니다. 부정확한 의료 정보를 제공하면 개인의 복지에 해를 끼칠 수 있으며, 법률 및 규정의 부정확한 해석은 중대한 법적 결과로 이어질 수 있습니다. 서비스는 이러한 조회를 우선적으로 다뤄야 하며, 응답에 명확한 면책 조항을 첨부하여 사용자가 전문적인 조언의 필요성과 제공된 정보의 한계를 인식할 수 있도록 해야 합니다.
- Future prediction
- 미래의 사건에 대한 예측을 요청하는 쿼리, 특히 투자 가격이나 특정 이벤트의 결과에 관한 조회는 추측적인 성격을 가지고 있으며 신중하게 접근해야 합니다. 그러나 시스템이 주요 기능으로 이러한 예측을 제공하도록 특별히 설계되고 의도된 경우, 더 신뢰할 수 있는 통찰력을 제공할 수 있을 것입니다.
- Controversial factuality
- 문화, 국가, 또는 신념 기반의 편견에 영향을 받을 수 있는 사실을 검증하려는 쿼리. 이러한 쿼리는 사실 자체가 정확하더라도 개인 및 그룹 간에 갈등과 논쟁을 유발할 수 있는 잠재적이 있습니다. 불필요한 갈등을 피하기 위해 이러한 쿼리에 대한 인식이 중요합니다.
- Error-inducing
- 환각 및 프롬프트 삽입과 같이 부정확하거나 예상치 못한 응답을 유발하는 쿼리의 사례는 처리되어야 합니다. 예를 들어, 어떤 LLMs가 "Tell me the date when Samsung will launch a new iPhone?"와 같은 무의미한 질문에 긍정적인 응답을 한 사례가 언론에서 보도되었습니다. 또한, 프롬프트 삽입 공격은 기밀성이 있는 교육 방법과 데이터셋을 노출할 수 있는 위험이 있으므로 주의 깊게 다뤄져야 합니다.
4 Sensitive Query Classification
- 저희는 HyperclovaX 백본 모델(Kim et al., 2021)을 사용하고 있으며, 해당 모델은 한국어에서 최첨단 언어 모델(Large Language Model, LLM)의 확장판입니다.
- 데이터는 한국어로 공개된 데이터(Moon et al., 2020) 및 redteam에서 생성한 내부 데이터를 사용하고 있습니다.
- 안정적인 서비스를 위해 룰 기반의 조절 도구와 피드백 루프를 구축했습니다.
- 모델, 모듈, 및 성능에 대한 자세한 내용은 별지 A.1에서 설명하고 있습니다.
- LLM에 들어가는게 아닌 입력단에서 제어하는건데 LLM으로 뭘 하는 것이지?
- 이걸로 분류기를 사용했다는 것이군.. 이에 대한 말 써야 하는게 아닐까?
- 부록보면 룰 기반도 있다고 함
- 이게 핵심아님?
5 Analysis
5.1 User Study
- 활성 사용자의 성비는 남성 대 여성으로 2.6 대 1입니다.
- 사용자 연령의 분포는 20대가 33.7% (남성 30.4%, 여성 42.6%), 30대가 31.8% (남성 31.6%, 여성 32.5%), 40대가 21.8% (남성 23.6%, 여성 16.8%), 50대가 9.6% (남성 10.9%, 여성 6.4%), 60대 이상이 3.0% (남성 3.5%, 여성 1.7%)입니다.
- 결과적으로 20대와 30대, 특히 남성이 주요 사용자 그룹으로 나타났습니다.
5.2 Log Study
5.2.1 Overview
- Figure 2에서는 매일 쿼리의 최대 수와 비교한 상대적인 입력 쿼리 수를 제시합니다. 서비스 첫 3일간이 가장 많은 쿼리를 보이며, 이후에는 최대 쿼리의 약 80% 정도에서 오르내리는 추세를 보입니다. 한편, 민감한 쿼리의 수는 매일 쿼리의 3-4%입니다. 또 다른 흥미로운 관찰은 이 생성 어플리케이션의 사용 경향인데, 주중에 더 많이 사용되며 주말보다는 적은 경향이 있습니다. 이로써 우리는 생성 어플리케이션이 주로 업무 목적으로 사용된다고 추측할 수 있습니다.

- 민감한 쿼리에 관한 Figure 3에서는 매일 쿼리의 백분율 분포를 보여줍니다. 차별과 논란의 사실성이 민감한 쿼리 분포의 큰 부분을 차지하고 있습니다 (값에 대한 자세한 내용은 별지의 Figure 8 참조). 중대한 부분을 차지하는 다른 카테고리로는 중죄 범죄, 시스템의 표현, 미래 예측 등이 일관되게 나타납니다. 다른 카테고리들은 각각 소량의 비중만 차지하고 있습니다. 또한, 이 비중이 매일 다르게 나타나고 있다는 것을 관찰할 수 있습니다. 이러한 변화는 사람들의 관심사와 사회적 이슈에서 기인한다고 가설을 세우고 있으며, 특정 기간 및 사회적 이벤트와 관련하여 분포를 더 자세히 조사할 예정입니다.

- Appendix A.4에서는 누적 로그의 백분율 분포를 제시합니다. 시스템에 기록된 쿼리가 많아질수록 중죄 범죄, 논란의 사실성, 미래 예측과 관련된 쿼리 수가 감소합니다. 반면에 시스템의 표현 및 차별에 관련된 쿼리 수가 증가합니다.
- 민감한 쿼리의 백분율 분포는 다음과 같이 수렴합니다: 중죄 범죄 (9.9%), 연령 제한 콘텐츠 (4.9%), 개인 정보 (1.9%), 저작권 위반 (4.3%), 차별 (36.1%), 자살 및 자해 (1.6%), 비속어 (2.4%), 시스템의 표현 (12.2%), 고위험 분야 (0.0%), 미래 예측 (7.9%), 논란의 사실성 (17.8%), 그리고 오류 유발 (1.1%). 이 결과는 교육과 테스트를 위한 데이터셋 분포를 만들기 위한 힌트를 제공합니다.
- 또한, 부록의 Figure 6의 분포를 계산하여 민감한 카테고리를 유효성 검증했습니다. 모든 카테고리가 완전히 독립적이지는 않지만 대부분의 카테고리가 상관 관계가 없습니다. 이는 우리가 성공적으로 카테고리를 구축했다는 것을 시사합니다.


5.2.2 In the beginning
- 중죄 범죄와 논란의 사실성의 비율이 Figure 4(a)에서 평균보다 큽니다. 우리는 사용자가 시스템의 응답을 테스트하고 원치 않는 응답을 기대하고 있다고 추측합니다. 반면에 시스템의 표현 및 미래 예측 카테고리의 비율은 사람들의 시스템에 대한 기대를 반영할 수 있습니다. 결과는 사람들이 서비스 시작 단계에서 모델의 능력에 덜 관심이 있다는 것을 보여줍니다.


5.2.3 On social events
- 서비스를 운영하면서 발생한 20~30대가 흥미로울 수 있는 소셜 이벤트 3개를 선정합니다.
- 변경 사항을 비교하기 위해 당일(이벤트 첫날), 이벤트 둘째 날과 셋째 날, 전체(마지막 보고까지의 합계)의 분포를 제시합니다.
- Wars.
- 서비스 중 러시아와 우크라이나 간의 전쟁이 계속되었습니다. 그래서 우리는 2023년 10월 7일에 시작된 이스라엘과 하마스 간의 전쟁에 중점을 두었습니다. Figure 4 (b)에서는 차별, 미래 예측, 그리고 논란의 사실성 카테고리가 큰 부분을 차지하고 있습니다. 이는 각각 신념에 대한 차별, 전쟁의 진행 상황, 그리고 전쟁의 이유와 정당화와 관련이 있습니다.
- Drug Scandal.
- 10월 20일에 대한 한국 연예인들의 마약 스캔들이 있었습니다. Figure 4 (c)에서 보듯이, 이벤트 당일을 중심으로 3일 동안 사람들은 특히 마약과 관련된 중죄 범죄에 대해 물어보는 경향이 있습니다.
- Gender Conflict.
- 11월 25일에 유명 게임들의 홍보 영상에서 한국 남성들을 조롱하기 위해 여성 우월주의자들이 사용하는 상징과 손 동작이 발견되었습니다. 해당 이벤트로 심각한 성 차별로 이어지고 있어, Figure 4 (d)에서 성 차별과 논란의 사실성, 비속어와 관련된 큰 변화를 볼 수 있습니다.
5.2.4 Keyword Study
- 우리는 명사로 필터링된 입력 로그의 키워드를 조사했습니다.
- Table 1에서 대부분의 키워드가 민감한 카테고리와 높은 관련성을 가지고 있는 것으로 나타납니다.

- 차라리 이 녀석을 부록으로 빼는건..?
- 또한 일부 키워드가 다른 사회 이슈를 반영하는 것을 관찰할 수 있습니다.
- 예를 들어, 미래 예측에서는 한국 정부가 시행한 공매도 금지 정책의 결과에 대해 알고 싶어하는 사람들이 있었습니다.

6 Discussion
- The findings of 70 days logs are summarized as follows:
- 사용자들은 주로 20~30대 남성입니다.
- 쿼리의 수는 처음 3일 동안이 가장 많으며, 이는 처음 3일을 극복한다면 서비스가 안정화될 것이라는 것을 시사합니다.
- 분포는 마지막에 수렴합니다(구체적인 숫자는 섹션 5.2.1을 참조하십시오).
- 처음에는 사람들이 서비스의 능력을 검토하려고 시도하여 시스템에 더 많은 논란이 되고 불법적인 쿼리를 던져왔습니다.
- 민감한 쿼리의 분포는 사회 이벤트의 특성에 따라 변합니다. 문제는 각각의 관련 카테고리의 비중을 높입니다. 이는 우리의 생성 어플리케이션이 사회와 문화와 밀접한 관련이 있다는 것을 시사합니다.
- 자주 사용되는 키워드 목록을 고려하면, 민감한 카테고리와 사회 이벤트의 결과를 모두 확인할 수 있습니다. 일부 키워드는 직접적으로 민감한 카테고리와 관련이 있으며 이는 불용어로 사용될 수 있습니다.
7 Related Works
8 Conclusion
- 본 논문에서는 먼저 검색 엔진을 위한 민감한 카테고리를 정의하고 이후에 분류기를 구축합니다.
- 국가 규모의 어플리케이션을 기반으로 다른 연구자들이 LLM 기반 서비스를 운영하기 위한 요구 사항을 대략적으로 파악할 수 있도록 사용자 연구 및 입력 쿼리의 분포를 제시합니다.
- 또한 차단해야 할 민감한 쿼리의 분포를 공유하고, 시간 및 이벤트에 따라 변화하는 내용을 조사합니다.
- 입력 쿼리는 여러 요인에 영향을 받을 수 있지만, 본 보고서가 생성형 LLM 기반 서비스를 구축하는 데 필요한 장벽을 낮추는 데 도움이 되기를 기대합니다.
Reference
- https://arxiv.org/pdf/2404.08672.pdf
댓글
댓글 쓰기