NL-209, DSCL: Dual-Semantic Contrastive Learning for Empathetic Response Generation, SIGIR 2024 Review
◼ Comment
- 논문은 공감대화를 생성하는 테스크를 해결하는 것이다.
- 근데, 뭔가 해결하고자 하는 문제점이 명확하지가 않다. 약간 동기가 부족한 느낌
- 제안한 프레임워크는 좀 다소 복잡한 느낌이다. 다음의 3가지로 구성되어 있다.
- 1) 이중 의미 대비 학습 모듈 (a dual-semantic contrastive learning module)
- 문장을 두 개의 인코딩을 통해 두개의 임베딩 벡터로 만든다.
- 이 두 임베딩벡터를 contarstive learning을 한다.
- 직관적으로 이게 왜 필요한지는 모르겠다.
- 저자가 말하길 높은 차원의 semantic feature을 추출하는 것이라 하고, 다른 의미를 추출하는 느낌이라고 말한다.
- 근데 contrastive learning을 위한 샘플을 고르는거보면, 결국 두 인코더에서 추출된 벡터는 같은 의미의 space로 모여야하게끔 한다.
- 즉 이것으로 성능이 좋아지는 것은 parameter의 증가때문이 주요 요인이 아닌지?
- 용어에 대한 설명이 좀 부족하다고 느낀다.
- H^n_ctx가 배치 N에 대한 H_ctx의 집합?
- H^var-n_ctx가 배치 N에 대한 H^var_ctx 집합?
- 2) 감정 상태 학습 모듈 (an emotional state learning module)
- COMET(오픈모델)을 통해 문장의 임베딩 벡터를 추출한다.
- COMET은 knowledge extraction encoder로, 여기서 뽑힌 벡터는 knowledge을 담고 있는 개 념이다.
- COMET으로 관계에 대한 벡터를 추출하고, 이에 추가적인 행렬을 태우고 이를 평균내서 h_rel(관계)에 대한 벡터를 활용한다.
- 또한 h_emo(감정)에 대한 벡터도 COMET을 통해 추출한다.
- h_emo와 h_rel은 각각 1)에서 추출한 벡터와 컨캣하여 H_emo, H_cog,rel을 만들고
- 이를 다시 컨캣하여 knowledge-enhanced encoder의 입력으로 넣어서 H_enh을 만든다.
- 3) 공감적 응답 생성 모듈 (an empathetic response generation module)
- 2)에서 만들어진 H_emo을 통해 감정인식하는 loss을 계산한다.
- H_enh을 트랜스포머 디코더에 넣어서 발화 생성을 하는 loss을 계산한다.
- 최종 loss는 1)의 contrastive learning loss, 3)의 2개 loss을 더해서 최종 loss가 된다.
- 약점
- dual-semantic contrastive learning module가 직관적으로 왜 필요한지 설명이 부족하다.
- contrastive learning에서 postivie sample은 두 임베딩 모듈을 통해 결정됩니다.
- 즉 학습된 dual-semantic embedding vectors은 같은 sapce로 모이게 된다.
- 따라서 고차원의 다른 의미를 추출하는 벡터가 아닌, 유사한 의미를 가지는 벡터로 생각된다.
- 즉 이상적으로는 두 인코더는 다른 space에 존재하는 고차원적인 semantic vectors을 추출해야합니다.
- 두 인코더로 인한 성능 향상은, 파라미터의 수 증가로 인한 이점으로 간주된다.
- 용어에 대한 설명이 좀 부족하다고 느낀다.
- 예) H^n_ctx가 배치 N에 대한 H_ctx의 집합?
- 예) H^var-n_ctx가 배치 N에 대한 H^var_ctx 집합?
- 저자들은 Vanilla Transformer을 사용하는 것처럼 보이는데, 왜 PLM을 왜 활용하지 않는가?
- 많은 연구들은 PLM(BERT 혹은 GPT2)와 같은 모델을 활용하여 더욱 좋은 시작점의 백본을 활용한다.
- 하지만, 이 연구는 이러한 pretraining을 안한 모델을 사용하는데 특별한 이유가 없어보인다.
- 강점
- 제안한 프레임워크는 감정을 지속적으로 고려하여 응답을 생성하는 시스템이다.
- COMET을 활용하여 외부 지식을 결합하여, 응답의 퀄리티를 향상시킨다.
- 제안한 프레임워크는 이전의 방법들보다 automatic/human evaluation에서 모두 높은 성능을 달성한다.
- 저자들은 제안한 프레임워크가 광범위한 실험을 통해 효과적임을 입증합니다.
- 기타
- 자세한 내용은 위에 언급했습니다.
- 제안한 프레임워크가 empathetic response generation 테스크에서 효과적이나 참신함이 부족합니다.
- 최근에는 LLM이 놀라운 성능을 보여주기 때문에 이와 관련된 내용도 포함되면 좋을 것 같다.
- gemini-pro 혹은 GPT4와 같은 LLM과 비교해보는 것은 어떤가요?
- 또한 평가 메트릭에서, GPT4-eval을 사용해서 성능을 평가해보는 것은 어떤가?
0 Abstract
- 고객의 감정적 상태를 인식하는 것에만 초점을 맞춘 기존의 연구 접근 방식은 대화의 지속 가능성을 놓치고 있습니다.
- 이러한 문제를 해결하기 위해 우리는 공감 대화 생성을 위한 이중 의미 대조 학습(DSCL) 모델을 제안합니다.
- 구체적으로, 우리는 먼저 두 가지 다른 세밀한 맥락적 표현을 생성하고 이를 각각 대조적 학습의 양성 예로 취급하여 높은 순서의 의미 정보를 추출하여 대화의 후속 턴을 안내합니다.
- 그런 다음 대화 컨텍스트에서 사용자의 역사적 감정 및 인지 상태를 추출하여 컨텍스트 표현을 강화하기 위해 상식 지식을 활용합니다.
- 마지막으로, 공감 반응은 의미 및 감정 상태의 조합을 디코딩하여 생성됩니다.
- 특히, 우리의 작업은 대화의 지속 가능성을 증진시키기 위해 대조적 학습을 적용한 최초의 응용 프로그램을 나타냅니다.
- EMPATHETICDIALOGUES 벤치마크 데이터셋에서 수행된 포괄적인 실험 결과는 DSCL이 자동 평가 및 인간 평가 모두에서 최신 기준 모델을 능가한다는 것을 보여줍니다.
1 INTRODUCTION
- 공감 대화 생성은 대화 시스템이 사용자의 상황을 이해하고 인식하고, 사용자를 중심으로 적절한 응답을 형성하는 능력을 나타냅니다. 이는 오랜 기간 동안 연구되어 왔습니다.
- 공감 대화 생성은 상담 및 감정 지원과 같은 영역에서 특히 사용자의 경험과 만족도에 대한 요구가 더 많은 영역에서 잠재력을 지닌다고 제안되었습니다.
- 대부분의 접근 방식은 생성기에 명시적인 감정 레이블을 할당함으로써 감정적인 반응을 조절하려고 합니다.
- 그러나 열린 도메인에서 명시적인 감정 레이블 없이 공감 대화에 참여하는 챗봇의 능력은 여전히 큰 도전이 남아 있습니다.
- 따라서 대화 시스템이 자율적으로 공감적인 응답을 생성할 수 있는 방법은 여전히 흥미로운 연구 분야입니다.
- 대화 시스템 내에서 공감 대화 생성의 중요한 구성 요소는 사용자의 대화 상태를 인식, 이해하고 응답하는 능력뿐만 아니라 지속적인 대화를 촉진하는 것입니다.
- 최근 연구에서는 공감을 유발하기 위해 상식 지식 및 감정 어휘 지식과 같은 외부 지식을 통합하여 공감 표현을 강화하려는 노력이 있었습니다.
- 그러나 다음과 같은 두 가지 주요 도전이 존재합니다:
- (1) 이러한 접근 방식은 즉각적인 발화 내의 감정 어휘에 의존하여 감정을 명시적으로 파악하고 표현하려고 합니다. 그러나 이는 대화 문맥 내에서 사용자의 historical 감정 상태를 고려하지 않으며, 결과적으로 사용자의 감정적인 요구를 편향된 평가로 이어질 수 있습니다.
- (2) 기존 접근 방식의 대화 상태를 인식, 이해 및 응답하는 능력은 제한적이며, 이러한 접근 방식은 대화 시스템에서 빈번하게 발생하는 지속 가능성 문제를 간과합니다. 이는 사용자의 실제 필요에 부합하지 않을 수 있는 공감적인 응답을 초래할 수 있습니다. 그림 1에서 "그것을 들어서 기쁘네요!"라는 응답은 대화 시스템이 사용자의 감정을 제대로 이해하지 못했음을 나타내며, 이는 지속적인 대화를 이끌어내기에 적절하지 않습니다.
- 이전에 언급된 도전에 대한 대응으로, 우리는 공감적 응답 생성을 위한 새로운 프레임워크를 제안합니다.
- 이를 이중 의미 대비 학습(DSCL)이라고 합니다.
- DSCL에는 세 가지 주요 구성 요소가 있습니다.
- 이중 의미 대비 학습 모듈 (a dual-semantic contrastive learning module)
- 감정 상태 학습 모듈 (an emotional state learning module)
- 공감적 응답 생성 모듈 (an empathetic response generation module)
- 구체적으로 두 개의 병렬 의미 인코더가 먼저 사용되어 텍스트의 서로 다른 측면에 중점을 둔 다른 세분화된 맥락 표현을 생성합니다.
- 그런 다음 이중 의미 대비 학습 모듈이 소개되어 공감적 지식으로써의 고차 의미 정보를 추출하는 의미 데이터 확장을 수행합니다.
- 이어서 감정 표현이 생성되어 응답 생성 중의 감정적 편향 문제를 완화하는 감정 상태 학습 모듈을 통해 이루어집니다.
- 마지막으로 의미적 및 감정적 표현이 공감적 응답 생성 모듈 내에서 통합되어 공감적 응답을 생성합니다.
- 즉 텍스트 -> 두 개의 임베딩 벡터
- 두 개의 임베딩 벡터를 dual-semantic contrastive learning을 하여 고차원 semantic 정보 (감정적 정보)를 추출하는 data augmentation 수행
- semantic, emotional 표현을 통합하여 공감적 응답 생성
- 우리는 EMPATHETICDIALOGUES 벤치마크 데이터셋에 대해 포괄적인 실험을 진행하였으며, 실험 결과는 DSCL이 최신 기술 기준선에 비해 우수한 성능을 보여주며, 자동 및 수동 평가 모두로 확인됩니다.
- 또한, 우리의 연구 결과는 DSCL이 사용자를 현재 대화 주제를 기반으로 다음 대화 턴으로 효과적으로 이끌어 낼 수 있다는 것을 보여줍니다.
- In summary, the contributions of this paper are as follows:
- 우리는 DSCL 프레임워크를 제안합니다. 이는 사용자의 맥락 내에서의 역사적 감정 상태를 고려한 공감적 응답 생성에 대한 새로운 접근 방식입니다.
- 우리가 알기로, 우리는 대화 지속성을 향상시키기 위해 contrastive learning을 통합하는 것을 제안한 pioneering proponents입니다. 이를 통해 공감 대화 시스템에서 보편적 응답의 도전을 해결하고 있습니다.
- 우리는 획득한 공감적 지식을 사용하여 사용자의 역사적 감정 상태를 모델링하여 감정 예측의 편향을 완화합니다.
- DSCL의 효과와 다양한 임베딩 차원에 걸쳐 그 견고성을 검증하기 위해 포괄적인 실험과 분석이 수행되었습니다.
2 RELATED WORK
- In this section, we review related work from the perspectives of both empathetic response generation models and contrastive learning text generation models.
2.1 Empathetic Response Generation Models
- Emotional 응답 생성은 empathetic 응답 생성의 선행과정이며, 그들은 목표 출력의 내용을 제어하기 위해 지정된 감정 라벨 또는 감정 키워드에 의존합니다.
- 이러한 모델링은 상세한 주석이 달린 대규모 말뭉치가 더 많이 사용 가능해짐에 따라 열매를 맺고 있습니다.
- 예를 들어, Zhou 등 [36]은 디코딩된 단어가 감정 단어인지 일반 단어인지를 선택하는 외부 메모리 모듈을 개발하여 다섯 가지 특정 감정 라벨에 대한 응답을 생성합니다.
- 이를 기반으로, EACM [33]은 감정 선택기를 추가하여 모델이 적절한 고유한 감정적 응답을 선택할 수 있도록 합니다.
- 또한, 감정 대화에서 일반적인 응답의 경향을 해결하기 위해 Shen과 Feng [27]은 커리큘럼 학습 및 이중 학습을 도입하여 응답의 다양성을 개선합니다.
- 그러나 기존의 감정 응답 생성 모델은 감정 카테고리의 정확성에 초점을 맞추고 감정의 연속성과 추론 가능성을 무시합니다.
- 공감적 응답 생성 작업은 청자가 화자의 감정을 추론할 수 있는 능력을 고려하고 모델이 어떤 감정에 응답해야 하는지 선택하는 단계를 제거합니다.
- 최근의 연구 노력들은 다양한 방법을 사용하여 대화 시스템을 보다 공감적으로 만들려고 시도했습니다.
- 예를 들어, Majumder 등 [19]은 polarity-based emotion clustering과 감정 모방을 고려하여 챗봇이 모방이 가능해야 한다고 제안합니다.
- Lin 등 [16]은 전문가 피드백을 다른 감정 유형에 대해 수집함으로써 응답 품질을 향상시킵니다.
- 또한, Li 등 [12]과 Sabour 등 [24]은 외부 상식 지식을 도입하여 모델의 공감을 향상시키기 위해 사용자에 대한 추가 정보를 얻으려고 노력합니다.
- 위의 작업들은 대화 모델의 공감 능력에 주의를 기울였지만, 대화에서 사용자의 감정이 연속적으로 변화하는 과정임을 간과하여 생성된 응답에 감정적 편향이 발생한다는 사실을 무시하고 있습니다.
- 따라서 우리는 DSCL 모델을 제안하여 사용자의 맥락 내에서의 역사적 감정 상태를 모델링하여 사용자의 현재 감정적 요구를 추론함으로써 이러한 감정적 편향을 완화하려고 합니다.
- 즉, 이 논문은 모델이 상대방의 감정을 고려하여 응답을 해야하는데, 감정을 명시적으로 맞추고 이에 대해 응답하는게 아니라 감정 state을 제시하려고 하는 듯?
2.2 Contrastive Learning Text Generation Models
- Contrastive learning은 양성 샘플 간의 거리를 좁히고 음성 샘플 간의 거리를 확장하여 샘플 표현을 생성하는 방법으로, 텍스트 생성 분야에서 널리 사용되고 있습니다.
- 예를 들어, Pan 등 [21]은 대비 손실을 활용하여 서로 다른 언어를 공유된 의미 공간에 명시적으로 매핑하여 기계 번역의 성능을 향상시킵니다.
- Su 등 [29]과 An 등 [1]은 각각 텍스트 생성을 위한 대비적인 프레임워크를 제시하며, 전자는 텍스트 다양성을 향상시키는 데 집중하고, 후자는 시퀀스 수준의 대비 예제를 구성하는 데 초점을 맞춥니다.
- 또한, MCCL [13]은 대상 응답을 부정적인 응답과 대비하여 대화형 챗봇 모델이 상충되는 응답 패턴을 구별하고 피할 수 있도록 합니다.
- 위 모델은 대비 학습에 의해 생성된 텍스트와 대상 텍스트 사이의 고차 특징에서 얻은 이점을 통해 모델의 생성 능력을 향상시킵니다.
- 그러나 인간 대화의 본질은 대화가 이루어지는 기존 맥락의 의미 이해에 있으며, 이는 대화가 이루어지는 기반이 됩니다.
- 따라서 본 논문에서는 입력 맥락의 고차 특징을 캡처하여 모델의 의미 이해 능력을 향상시키기 위해 이중 의미 대비 학습을 시도하고, 이를 통해 새로운 대화 턴으로 이어지는 공감적 응답을 생성하는 모델을 구축하고자 합니다.
3 APPROACH
- 이 섹션에서는 먼저 다중 턴 대화 시스템에서 공감적 응답 생성 작업을 정의합니다.
- 그런 다음, DSCL 모델을 자세히 설명합니다.
- DSCL 모델은 세 가지 주요 dual-semantic contrastive learning module (see 3.2), emotional state learning module (see 3.3), empathetic response generation module (see 3.4).로 구성됩니다.
- 두 명의 화자 간의 대화 𝐷는 𝑀+1 개의 발언 𝐷 = {𝑈1, · · · ,𝑈𝑀+1}의 순서로 표현될 수 있습니다.
- 그런 다음 𝐷를 (𝐶,𝑊)로 나누어, 여기서 𝐶 = {𝑈1, · · · ,𝑈𝑀}은 대화 맥락을 나타내고, 𝑊는 대상 응답 𝑈𝑀+1을 나타냅니다.
- 각 맥락 발언 𝑈𝑚 (𝑚 = 1, 2, · · · , 𝑀)은 임의 길이의 토큰 시퀀스인 𝑁𝑚을 포함합니다.
- 그리고 감정 카테고리 𝑒는 공감 지식 학습을 통해 얻어집니다.
- 따라서 공감적 응답 생성 작업은 주어진 대화 맥락 𝐶를 기반으로 응답 𝑊를 생성하는 확률 𝑃(𝑊 | 𝐶, 𝑒)을 계산하는 것입니다.
- 즉 컨텍스트와 emotion을 조건으로해서 응답 W을 생성하는 문제
3.1 Overview
- 그림 2는 제안된 모델인 DSCL의 개요를 보여줍니다.

- 이 모델은 표준 Transformer [31]를 기반으로 구축되었습니다.
- PLM은 안쓰나?
- 먼저, 두 개의 병렬 의미 인코더에 의해 context representations H𝑐𝑡𝑥와 H^𝑣𝑎𝑟_𝑐𝑡𝑥가 생성됩니다.
- 이후, 이를 통합하여 의미 표현 H^𝑠𝑒𝑚_𝑐𝑡𝑥을 얻습니다.
- 그런 다음, H𝑐𝑡𝑥와 H^𝑣𝑎𝑟_𝑐𝑡𝑥가 dual-semantic contrastive learning 모듈에 입력되어 대비 손실 L𝑐𝑡𝑟을 얻습니다.
- 이후, 감정 상태 학습 모듈에서 생성된 감정 상태 신호 h𝑒𝑚𝑜 및 인지 상태 신호 h𝑟𝑒𝑙을 사용하여 의미 표현 H𝑠𝑒𝑚 𝑐𝑡𝑥를 개선합니다.
- 마지막으로, H𝑠𝑒𝑚 𝑐𝑡𝑥을 기반으로 모든 후보 단어에 대한 점수를 계산하여 공감적 응답을 생성합니다.

3.2 Dual-Semantic Contrastive Learning Module
- 대화 시스템의 의미 이해 능력을 향상시키기 위해, 우리는 먼저 dual-semantic contrastive learning framework를 제안합니다.
- 이 프레임워크는 the parallel semantic encoders and dual semantic contrastive learning 두 부분으로 구성되어 있습니다.
- 이들은 각각 대화 내용의 단어 수준에서의 fine-grained features of context과 대화 이력에서의 higher-order semantic features을 추출하는 데 사용됩니다.
- 이전 연구들을 따라 [11, 19, 24], 대화 이력 𝐶의 각 문장을 단어의 긴 시퀀스로 연결하고, 특별한 토큰 [𝐶𝐿𝑆]를 𝐶의 시작 마커로 사용합니다. 여기서, 기호 ⊕는 연결 작업을 나타냅니다.
- Devlin et al. [4]과 유사하게, 우리는 [𝐶𝐿𝑆]의 최종 숨겨진 표현을 전체 시퀀스의 표현으로 사용합니다.
- Parallel Semantic Encoders.
- 다음은 다중 턴 대화 설정에서 대화가 발화자 또는 청취자로부터 온 것을 구별하는 것이 유용하기 때문에 입력 문맥 𝐶에 대한 상태 임베딩 E𝑠(𝐶)를 삽입합니다.
- 대화 히스토리 E(𝐶)의 벡터 표현은 위의 유형의 임베딩을 합한 것입니다:
- 단어 임베딩(E𝑤(𝐶)) 레이어와 위치 임베딩(E𝑝(𝐶)) 레이어를 먼저 사용하여 시퀀스 𝐶의 단어 임베딩 및 위치 임베딩을 얻습니다.
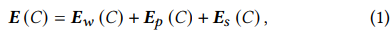
- 화자가 누군지에 대한 embedding을 추가. PLM을 쓴다면 어떻게 결합?
- 여기서 E(𝐶) ∈ R^{𝑘×𝑑𝑒𝑚𝑏}, 𝑘 ≤ 𝑀𝑁_𝑀 + 1은 시퀀스 𝐶의 단어 수이고, 𝑑𝑒𝑚𝑏는 임베딩 차원입니다.
- 그런 다음 E(𝐶)를 두 개의 문맥 수준 의미 인코더에 공급하여 서로 다른 미세 구간 문맥 표현을 생성합니다.

- 여기서 H𝑐𝑡𝑥와 H𝑣𝑎𝑟 𝑐𝑡𝑥는 모두 차원이 R^𝑘×𝑑ℎ이며, 𝑑ℎ는 이 두 인코더의 은닉 크기입니다.
- 중요한 점은 Enc𝑐𝑡𝑥와 Enc𝑣𝑎𝑟 𝑐𝑡𝑥가 모두 Transformer에서 파생되었으며, 쌍의 유일한 차이점은 다중 헤드 어텐션 메커니즘 내의 헤드 수입니다.
- 두 인코더(Enc_ctx, Enc^var_ctx)가 multi-head attention 수만 다르고 나머진 동일하게 세팅한듯
- 이 설계의 목적은 각 어텐션 메커니즘이 각 단어의 다른 특징 부분을 최적화할 수 있도록하여 단일 어텐션 메커니즘에서 발생할 수 있는 잠재적인 편향을 균형있게 하는 것입니다.
- 마지막으로, 다른 fine-grained contextual representations을 병합합니다:

- 두 벡터를 가중치 합을 하는데, 가중치는 softmax 느낌대로 구함
- 여기서 𝑊와 𝑊ˆ는 가중치 행렬이며, 𝜎(·)는 ReLU 활성화 함수입니다.
- Dual-Semantic Contrastive Learning.
- 모델의 의미적 이해를 강화하기 위해, 우리는 다른 수준의 미세 구간에서 상이한 고차 의미적 표현을 구별하는 contrastive objective을 고안했습니다.
- 우리의 "dual-semantic" 접근 방식은 모델이 약간의 창의성과 함께 역사적 의미를 깊이 이해할 수 있도록 합니다.
- 혹은, 단일 대조 학습은 모델이 긍정적 의미 샘플에 고수하게 만들지만 일반화 능력을 약화시킬 수도 있습니다.
- 두 가지 긍정적 샘플이 있는 dual contrastive learning은 모델의 의미 학습 공간을 어느 정도 확장하여 모델이 역사적 의미를 이해하고 적용하는 능력을 높입니다.
- 섹션 5의 실험 결과 또한 DSCL에 의해 생성된 응답이 역사적 대화와 일치뿐만 아니라 대화의 다음 턴으로 이어지는 것을 입증합니다.
- 배치 크기를 𝑁으로 주어, 우리는 문맥 인코더에서 생성된 의미적 표현을 H𝑛 𝑐𝑡𝑥와 H𝑣𝑎𝑟−𝑛 𝑐𝑡𝑥 (𝑛 ∈ 𝑁)로 나타냅니다.
- 용어에 대한 설명이 부족해서 헷갈린다
- H^n_ctx가 배치 N에 대한 H_ctx의 집합?
- H^var-n_ctx가 배치 N에 대한 H^var_ctx 집합?
- Enc𝑐𝑡𝑥의 관점에서, 우리는 H𝑣𝑎𝑟−𝑛 𝑐𝑡𝑥를 긍정적인 샘플로 간주하고 H𝑖 𝑐𝑡𝑥 (𝑖 ≠ 𝑛)를 부정적인 샘플로 간주합니다.
- 그 후, Enc𝑐𝑡𝑥 관점에서의 대조적 객체를 다음과 같이 정의할 수 있습니다:
- H^n_ctx와 H^var-n_ctx난 positive 관계 쌍?
- H^n_ctx, H^i_ctx (i!=n)은 negative 관계 쌍?

- 여기서 𝜃(·)은 유사성을 측정하는 점수 함수를 나타내며, L𝑝𝑜𝑠와 L𝑛𝑒𝑔는 각각 긍정적 샘플과 부정적 샘플의 유사성에 해당합니다.
- Enc𝑣𝑎𝑟 𝑐𝑡𝑥 관점에서의 대조적 객체는 유사하게 정의되며, 전체 대조 손실은 다음과 같습니다:

- 그냥 이건 어떤 인코더 관점으로 보냐에 따라 2가지 loss가 생기는것임
- 결국, 문장에 2가지 인코더를 통해서 이를 contrastive learning을 하는 것인데..
- 다른 인코더에서 나온 임베딩을 positive로 하게 되면, 유사한 의미를 추출하는 인코더가 되는 것 아닌가?
- dual-semantic contrastive learning이 왜 필요한 것이지?





3.3 Emotional State Learning Module
- Knowledge Extraction Encoders.
- ATOMIC [25]에서 영감을 받아, 우리는 대화 맥락 𝐶에서 각 발화 𝑈𝑚으로부터 다섯 가지의 상식적인 관계([xReact], [xWant], [xNeed], [xIntent], [xEffect])를 추출했습니다.
- 여기서 "[xReact]"는 사용자의 감정 상태를 나타내며, 나머지 네 가지 관계는 사용자의 cognitive 상태를 나타냅니다.
- 따라서 우리는 상식적인 지식의 숨겨진 벡터를 얻기 위해 두 개의 독립적인 인코더를 사용합니다.

- 𝑟𝑒𝑙 ∈ {𝑥𝑊𝑎𝑛𝑡, 𝑥𝑁𝑒𝑒𝑑, 𝑥𝐼𝑛𝑡𝑒𝑛𝑡, 𝑥𝐸𝑓𝑓𝑒𝑐𝑡 }에 대해, h𝑒𝑚𝑜, h𝑥𝑟𝑒𝑙 ∈ R 𝑑ℎ 이며, 𝐶𝑅𝑒𝑎𝑐𝑡, 𝐶𝑟𝑒𝑙은 COMET [2]에 의해 생성됩니다.
- 감정 상태는 이산적인 감정적인 단어 (예: 슬픔, 흥분, 행복, 화남, 놀람)이고, 인지 상태는 문장입니다.
- 따라서 우리는 [𝐶𝐿𝑆] 암묵적 상태의 감정 인코더 출력과 관계 인코더 출력의 평균을 각각 취합니다.
- 발화의 대표적인 임베딩을 출력하는데, [CLS] 대신에 ATOMIC에서 영감을 받아서 위와 같은 방법을 썼다는 것이다.
- 즉 COMET이란 오픈모델을 통해서 발화의 CReact, Crel을 가져온다.
- CReact은 Encemo, Crel은 Encrel을 통한 임베딩이다. (2개의 인코더 파라미터는 아마 학습되는듯)
- 여기서 rel은 ATOMIC에서 정의된 4가지 (Want, Need, Intent, Effect)의 요소이다.
- 예를들어, Encrel(E(CWant))을 통해 Want에 해당하는 hWant을 추출한다.
- 이런식으로 추출된 hemo와 4가지 hrel의 평균이 문장을 나타내는 임베딩이 되는 듯?
- Knowledge-Enhanced Encoders.
- 마주머더 등 [19]과 유사하게, 우리는 대화 맥락에서 발화 수준의 상식적인 관계 표현을 문맥적 표현에 연결한 다음 이를 지식 강화 인코더에 보내 각 관계에 대한 상식 개선된 맥락 표현을 얻습니다.

- 여기서 H𝑒𝑚𝑜, H𝑐𝑜𝑔,𝑟𝑒𝑙 ∈ R 𝑘×𝑑ℎ 입니다.
- Dual-semantic encoder로 추출한 것과 concat하고 matrix 태워서 개선된 contextual representations을 얻는다.
- 감정적 지식과 인지적 지식은 모두 사용자의 상태를 개선하는 중요한 구성 요소이며, 우리는 모델이 그들의 혼합을 기반으로 적절한 공감적인 응답을 생성할 수 있기를 기대합니다.
- 따라서 감정적으로 강화된 문맥적 표현과 인지적으로 강화된 문맥적 표현을 연결합니다:

- where H𝑒𝑛ℎ ∈ R 𝑘×5dh.



3.4 Empathetic Response Generation Module
- Emotional Strategy Selection.
- 대화가 진행됨에 따라 화자의 감정은 실제로 변합니다.
- 따라서 대화 맥락 𝐶에서 사용자의 과거 감정 상태를 학습하기 위해, 감정 강화된 컨텍스트 표현 H𝑒𝑚𝑜의 각 유형의 감정 레이블의 평균 값을 사용하여 분류합니다.

- 차원이 1인 텐서 H𝑒𝑚𝑜의 두 번째 차원의 모든 요소의 평균을 취하는 것을 의미합니다.
- 감정 카테고리 분포 𝑃𝑒를 생성하기 위해 e를 선형 레이어에 입력하고 Softmax 연산을 수행합니다.

- 여기서 𝑃𝑒 ∈ R 𝑠, 𝑊𝑒 ∈ R 𝑑ℎ ×𝑠는 가중치 벡터이며 𝑠는 데이터셋에서 사용 가능한 총 감정 레이블의 수입니다.
- 우리는 감정 카테고리 분포 𝑃𝑒와 실제 레이블 𝑒' 사이의 교차 엔트로피 손실을 최소화하여 가중치 매개변수를 업데이트합니다.

- Response Generation.
- 지식 강화된 컨텍스트 H'𝑐𝑡𝑥를 기반으로 대상 공감적 응답 𝑈𝑚+1 = 𝑊 = (𝑤1, · · · ,𝑤𝑇 )을 생성하기 위해, 이전 연구 [12, 19]를 참고하여 Transformer의 디코더를 채택합니다.

- 여기서 Y1:𝑡−1은 시간 𝑡 이전에 생성된 토큰의 임베딩을 나타내며, H'𝑐𝑡𝑥 ∈ R 𝑘×𝑑ℎ는 대화 컨텍스트의 최종 표현입니다.
- 이는 H𝑟𝑒 𝑓 ∈ R 𝑘×5𝑑ℎ가 Multi-Layer Perceptron (MLP)을 통과한 후 생성됩니다.
- ⊙는 요소별 곱셈을 나타내며, 𝜎(·)는 ReLU 활성화 함수를 의미합니다.
- We then use the negative log-likelihood as the generation loss function:

- Eventually, we combine all the losses for model training:

- where 𝛼1, 𝛼2 and 𝛼3 are hyper-parameters that we use to optimise our model.
- And during our experiments, we set the 𝛼1 = 0.2, 𝛼2 = 0.5 and 𝛼3 = 2.5.






4 EXPERIMENTAL SETUP
- In this section, we provide a comprehensive overview of our experimental setup.
4.1 Research Questions
- 우리의 연구는 DSCL이 공감적 응답 생성에 미치는 효과를 이해하는 데 중요한 다음의 주요 연구 질문을 다룹니다:
- (1) RQ1: 우리가 제안하는 DSCL 모델이 공감적 응답 생성에 대해 기준선보다 더 나은 성능을 발휘할 수 있습니까?
- (2) RQ2: 대화 내내 사용자의 감정 상태를 모델링하고 이중 의미 대조 학습을 도입하는 것이 정말 효과적인가요?
- (3) RQ3: 모든 모델의 성능에 대한 임베딩 차원의 다른 영향은 무엇인가요?
- (4) RQ4: 모델의 컨텍스트 길이가 응답 생성에 미치는 영향은 무엇인가요?
4.2 Dataset
- 저희의 실험적 조사는 EMPATHETICDIALOGUES 데이터셋 [23]을 사용하여 진행되었습니다.
- 이 데이터셋은 공감적 응답 생성을 평가하기 위한 표준 벤치마크로 부상한 것으로 알려져 있습니다.
- 구체적으로 EMPATHETICDIALOGUES에는 거의 25,000개의 오픈 도메인 이진 대화와 32개의 균일하게 분포된 감정 레이블이 포함되어 있습니다.
- 청취자는 화자가 말하는 내용을 통해 화자의 감정적 필요를 추론하고 공감적으로 응답합니다.
- Rashkin 등 [23]을 따라, 우리는 8:1:1의 훈련/검증/테스트 분할을 사용하고 각 샘플의 마지막 발화가 공감적인 응답임을 가정합니다.
4.3 Baselines for Comparison
- 우리의 비교 분석을 위해, 공감적 응답 생성 분야의 다양한 접근 방식을 대표하는 일곱 가지의 기준 모델을 사용합니다:
- (1) Transformer[31]: 인코더-디코더 프레임워크를 위해 훈련된 원래 Transformer 모델입니다.
- (2) Multi-TRS[23]: 감정 대화 작업에 최적화된 Transformer 모델의 버전입니다.
- (3) MoEL[15]: 각 유형의 감정에 대해 별도의 디코더로 학습된 모델로, 이들을 결합하여 응답을 생성합니다.
- (4) MIME[19]: 사용자의 감정을 모방하고 부정적 및 긍정적 극성 범주로 분류하는 Transformer 기반 모델입니다.
- (5) EmpDG[11]: 다양한 해상도의 상호작용하는 공감적 대화 모델로, 응답을 생성하기 위해 공감 생성기를 제안하고 최적화를 위해 두 개의 판별자를 추가합니다. 그러나 판별자는 대화의 미래 라운드에서 정보를 활용하므로 이 모듈은 공정성을 위해 실험에서 제거됩니다.
- (6) CEM[24]: 상식 지식을 도입하여 사용자 시나리오의 인지 이해를 향상시키고 생성된 응답에서 공감적 표현을 더욱 강화하는 대화 모델입니다.
- (7) KEMP[12]: 감정 컨텍스트 그래프를 통해 감정 관련 개념을 인코딩 및 디코딩 프로세스에 결합하여 대화 시스템의 감정 의존성 능력을 강화하는 모델입니다.
4.4 Evaluation Metrics
- Our evaluation framework incorporates a dual-pronged approach, encompassing both automatic evaluations and human evaluations.
- Automatic Evaluations.
- [17, 19, 20, 24]를 따라, 우리는 DSCL과 기준 모델의 성능을 자동으로 평가하기 위해 네 가지 지표를 채택합니다.
- 즉, 퍼플렉서티(Perplexity), Distinct-1, Distinct-2 및 정확도입니다.
- 퍼플렉서티는 명백하게 대화의 구문 구조와 각 발화의 구문 구조를 설명하는 모델의 능력을 측정합니다.
- Distinct-1과 Distinct-2는 각각 생성된 응답에서 서로 다른 유니그램 및 바이그램의 수를 계산하여 다양성 측면에서 응답을 측정하는 데 자주 사용됩니다.
- 정확도는 응답의 감정 카테고리가 실제 감정 레이블과 같은지를 측정합니다.
- GPT4-Eval 등을 사용해보는것은 어떤지?
- Human Evaluations.
- [11, 12, 19]를 따라, 우리는 DSCL과 기준 모델에서 무작위로 100개의 샘플을 선택한 다음, 세 명의 전문 평가자에게 세 가지 기준을 기반으로 응답을 비교하도록 요청합니다.
- 즉, Empathy, Relevance and Fluency입니다.
- 공감은 응답의 감정이 대화 시나리오에 적합한지를 측정합니다.
- 관련성은 응답이 과거 주제에 부합하는지를 평가합니다.
- 유창성은 생성된 응답의 문법적 정확성과 가독성을 측정합니다.
- 우리는 평가 지표를 강하게 동의에서 동의, 반드시 그렇지 않음, 동의하지 않음, 강하게 반대하는 5부터 1까지 다섯 단계로 나눕니다.
4.5 Implementation Details
- 이 하위 섹션에서는 실험 설정에 관련된 구체적인 구현 세부 사항을 상세히 설명합니다.
- 구체적으로, 우리의 실험에서는 모든 모델을 PyTorch 1.12.1에서 구현하고 옵티마이저로 Adam [8]을 사용합니다.
- 우리는 사전 훈련된 임베딩 GloVE 벡터 [22]를 사용하며 이 벡터는 네 가지 차원(즉, 50, 100, 200, 300)으로 구성되어 있습니다.
- 여기서 은닉 차원은 300으로 설정됩니다.
- 학습에는 Adam [8] 옵티마이저를 사용하며, 이때 𝛽1 = 0.9 및 𝛽2 = 0.9입니다.
- DSCL의 초기 학습률은 0.0001이고 최대 디코딩 단계는 30입니다.
- 기준 모델의 모든 학습 매개변수는 해당 논문에서 언급된 구성을 따릅니다.
- 모든 모델은 배치 크기가 16인 단일 NVIDIA GeForce RTX 3090 GPU에서 학습됩니다.
- DSCL의 훈련 중에는 조기 종료가 적용됩니다.
5 EXPERIMENTAL RESULTS
5.1 Overall Performance (RQ1)
- RQ1에 대답하기 위해, 우리는 DSCL과 기준 모델이 생성한 응답의 의미적 품질과 감정적 정확도를 자동 평가 및 인간 평가를 통해 조사했습니다.
- 결과는 표 1에 나와 있습니다.

- 일반적으로, 우리의 방법인 DSCL은 모든 메트릭에 대해 최첨단 결과를 일관되게 얻어, 다중 턴 대화에서 공감적 응답을 생성하는 효과적임을 입증합니다.
- 특히, Distinct-1 및 Distinct-2에서 DSCL의 개선은 각각 약 22.72% 및 24.08%에 이를 정도로 최상의 성능을 보이는 기준 모델 대비 DSCL의 개선을 보여줍니다.
- Automatic Evaluation Results.
- 우리는 독립적인 감정 지식 분석 모듈을 갖는 방법(CEM, KEMP, DSCL)이 성능이 더 좋다는 것을 발견했습니다.
- 이는 응답 생성에 대한 감정 분석의 보조 역할을 설명합니다.
- DSCL의 감정 상태 학습 모듈은 특히 감정 분석의 역할을 강화할 수 있으며, 대화를 통해 사용자의 과거 감정 상태도 DSCL에서 고려됩니다.
- 이는 더 포괄적인 신호를 제공하여 예측을 더 잘 할 수 있도록 합니다.
- 또한, KEMP는 다양성 지표에서 성능이 낮은데, 이는 생성 과정에서 감정 신호에 과도하게 집중되어 있기 때문일 수 있습니다.
- 반면, DSCL은 응답의 의미적 품질과 감정적 정확도를 훌륭하게 균형잡힌다는 점에서 우수한 성과를 보입니다.
- 이는 우리의 이중 의미 대조 학습 모듈이 사용자의 감정을 더 잘 반영하는 다중 수준의 의미적 표현을 학습할 수 있다는 것을 나타냅니다.
- Human Evaluation Results.
- 표 1에 나타난 것처럼, DSCL은 세 가지 지표 모두에서 기준 모델을 능가합니다.
- 이는 DSCL이 모델의 인간 언어 모방 능력을 향상시키고 더 인간 같은 응답을 생성하는 데 기여한다는 것을 보여줍니다.
- 그 중에서도 공감 지표의 개선이 가장 유의미한데, 이는 대화의 과거 감정 상태를 모델링하여 사용자에 대한 공감을 더 잘 이끌어 낼 수 있다는 것을 설명합니다.
- 기준 모델 중에서 KEMP가 공감 지표 점수가 가장 높은데, 이는 자동 평가 결과와 일관된 결과입니다.
- CEM, KEMP 및 DSCL은 다른 모델보다 관련성 면에서 더 좋은 결과를 달성합니다.
- 이는 모두가 컨텍스트에서 공통 지식 관계를 분석하기 위해 COMET을 활용함으로써, 대화 주제와 관련이 더 높은 응답을 생성할 수 있기 때문으로 추정됩니다.
- 그리고 우리는 유창성 측면에서 모델 간에 명백한 차이가 없다는 것을 발견했습니다.
- 이는 Transformer에 의해 생성된 응답이 이미 유창하고 문법적이기 때문이라고 추론합니다.

5.2 Ablation Study (RQ2)
- RQ2에 대답하기 위해, 우리는 각 구성 요소의 개별 기여를 결정하기 위해 축소 실험을 수행합니다. 다음과 같은 변형이 개발되었습니다:
- w/o DCL: 이중 의미 대조 학습 모듈 (식 3-10)을 제거합니다.
- w/o SCL: Enc𝑣𝑎𝑟 𝑐𝑡𝑥의 대조 대상을 제거합니다 (식 10은 식 6으로 대체됩니다).
- w/o KEM: 감정 지식 추출 인코더와 감정 강화 인코더를 제거합니다 (식 11 및 13).
- w/o CEM: 대화 기록 중 사용자의 감정 상태를 제거합니다 (식 16), e는 H𝑒𝑚𝑜 [0]로 대체됩니다.
- 표 2에 표시된 바와 같이, 우리는 이중 의미 대조 학습과 사용자의 과거 감정적 상태 모델링에 대한 통제된 실험을 설정했습니다.

- 우리는 먼저 w/o DCL, w/o SCL의 결과에 집중합니다.
- w/o DCL은 가장 높은 Distinct 점수를 얻는 것으로 나타나며, 이는 대조 학습이 응답 다양성을 저해한다는 것을 나타냅니다.
- w/o SCL과 비교하면, w/o DCL은 낮은 퍼플렉서티와 높은 Distinct 점수를 가지는데, 이는 이중 의미 대조 학습 모듈이 응답 다양성을 향상시키면서 의미적 품질을 보장할 수 있다는 것을 검증합니다.
- 또한, 이중 의미 대조 학습 모듈은 정확도 점수 측면에서도 감정 카테고리를 예측하는 데 도움이 됩니다.
- 그런 다음 w/o KEM, w/o CEM의 결과에 집중하고 w/o KEM과 w/o CEM의 정확도가 비슷하다는 것을 발견했습니다.
- 이는 대화의 과거 감정적 상태를 고려하는 것이 효과적이고 필요하다는 것을 시사합니다.
- 그들의 다른 세 가지 지표에 대한 점수는 크게 다르지 않으며, 이는 공통 지식 관계에서 감정 정보 추출에 뚜렷한 잡음이 없다는 것을 나타냅니다.

5.3 Impact of Embedding Dimension (RQ3)
- RQ3에 대한 답변으로, 우리는 모든 모델의 성능을 다른 임베딩 차원인 𝑑𝑒𝑚𝑏 = {300, 200, 100, 50}에서 분석합니다.
- 그림 3은 네 가지 최상의 성과를 보이는 모델의 결과를 직접 보여줍니다 (부록 A에 자세한 자동 평가 결과가 표시됩니다).

- 일반적으로 대부분의 경우에 DSCL은 모든 메트릭에 대해 기준 모델을 모든 임베딩 차원에서 능가합니다 (𝑑𝑒𝑚𝑏 = 50에서 Distinct-2를 제외하고).
- 이는 DSCL이 다양한 임베딩 차원에서의 강건성을 확인합니다.
- 특히, DSCL은 100 𝑑𝑒𝑚𝑏 = 100에서 가장 뚜렷한 장점을 갖습니다.
- 이는 DSCL이 낮은 차원의 사전 훈련 벡터에서 풍부하고 유용한 대화 정보를 학습한다는 것을 나타냅니다.
- 기준 모델과 비교하여 DSCL은 가장 안정적인 결과를 갖고 있으며, 이는 DSCL의 탁월한 일반화 능력을 보여줍니다.
- 임베딩 차원이 KEMP의 성능에 가장 큰 영향을 미치는 것으로 나타납니다.
- 그리고 그의 퍼플렉서티와 정확도 점수는 완전히 반대의 추세를 보입니다.
- 이는 KEMP가 생성 단계에서 감정 신호를 반복적으로 강화하여 생성 과정에서 의미 신호의 안내 역할을 약화시켰기 때문일 수 있습니다.
- MIME과 DSCL의 경우, 임베딩 차원이 증가함에 따라 일관된 추세를 유지했습니다.
- 이는 양수 샘플과 음수 샘플 간의 변동성에 중점을 둔 두 모델 모두에 해당됩니다.
- 특히, CEM의 퍼플렉서티 점수는 매우 불안정합니다.
- 이는 CEM의 매개변수가 𝑑𝑒𝑚𝑏 = 300 일 때 더 적합하며, 다른 낮은 차원에서는 과적합이 발생할 수 있기 때문일 수 있습니다.
- 따라서 우리는 그것을 그림 3의 비교 대상으로 포함하지 않았습니다.

5.4 Impact of Context Length (RQ4)
- RQ4에 대답하기 위해, 우리는 DSCL과 세 가지 기준 모델(MIME, MoEL 및 KEMP)의 성능을 다른 컨텍스트 길이(단어 수로 측정)의 테스트 샘플에서 조사했습니다.
- 우리는 테스트 샘플을 그들의 컨텍스트 길이에 따라 그룹으로 분할하고 표 3에서 컨텍스트 길이별 테스트 분포를 제시합니다.

- 더 긴 텍스트는 더 많은 정보를 포함할 수 있지만, 60 단어 이상의 긴 텍스트 샘플은 소수만 차지합니다.
- [14, 18]를 따라, 우리는 각각 Distinct-1, Distinct-2, BLEU-1 및 BLEU-2로 모델 성능을 평가합니다.
- BLEU-1 및 BLEU-2는 생성된 응답과 실제 응답 사이의 단어 중복을 측정합니다.
- 더 높은 BLEU 점수는 생성된 응답이 실제 응답에 더 가깝다는 것을 의미합니다.
- 실험 결과는 그림 4에 나와 있습니다.

- 일반적으로, DSCL은 모든 메트릭에서 모든 컨텍스트 길이에서 기준 모델을 능가합니다.
- 이는 DSCL이 다양한 컨텍스트 길이에서의 강건성을 확인합니다.
- 특히 30 이하의 길이의 컨텍스트에 대해서는 DSCL이 다른 길이의 컨텍스트보다 BLEU 점수에서 기준 모델보다 더 잘 수행하는 것을 분명히 보여줍니다.
- 이는 DSCL이 짧은 컨텍스트에서의 효과적임을 증명합니다.
- 이중 의미 대조 학습에 의해 추출된 고차 의미적 특징은 DSCL이 짧은 컨텍스트에서의 대화 정보를 최대한 활용할 수 있도록 합니다.
- MIME은 Distinct 점수에서 가장 낮은 성과를 내는 기준 모델입니다.
- 이는 표 1에서 보인 전반적인 성과와 일치합니다.
- 또한, 컨텍스트 길이가 증가함에 따라 거의 모든 모델이 Distinct 점수에서 증가하고(BLEU-1에서 KEMP 제외) BLEU 점수는 감소합니다.
- 이는 컨텍스트 길이가 증가함에 따라 대화 기계가 응답 생성 과정에서 실제 응답과 유사성과 문장 다양성을 균형잡기가 점점 어려워진다는 것을 의미합니다.
- 이는 긴 컨텍스트가 대화 정보를 풍부하게 하면서 동시에 잡음을 도입한다는 것 때문일 수 있습니다.


5.5 Case Study
- 표 4는 DSCL과 기준 모델들의 생성된 응답을 나열합니다.

- 첫 번째 사례에서 DSCL은 "too bad"라는 답변으로 사용자의 슬픔과 공감합니다.
- 동시에 DSCL은 사용자를 대화의 다음 턴으로 이끌며 컨텍스트 주제 주변의 대화를 유도합니다.
- 이것은 고차 의미적 특징을 얻기 위해 이중 의미 대조 학습 모듈을 사용하는 것으로 인해 이루어질 수 있습니다.
- 두 번째 사례에서 각 모델은 적절한 감정 "미안합니다"로 응답을 생성하지만, EmpDG, CEM 및 DSCL 모델만이 대화 컨텍스트를 이해하며 외부 지식을 적용하기 때문에 아마도 그들은 모두 외부 지식을 적용한다.
- 그러나 DSCL은 대화 상대의 아내에게 바람직한 감정을 정확하게 표현했으며, 이는 또한 실제 결과에 매우 적합하므로 DSCL의 우수한 생성 능력을 나타냅니다.
- 더 나아가 두 가지 경우를 비교하여, 긴 컨텍스트는 모델이 대화 역사와 더 많은 정보를 얻어 감정적인 응답을 생성하는 데 도움이 되는 것을 발견했습니다.
- 세 번째 사례에서는 DSCL만이 "nostalgic" 감정과 일치하는 응답을 생성했으며, 다른 모델들은 사용자의 현재 발화에서 "nice"와 "tough times"에 영향을 받아 적절하지 않은 감정을 표현했습니다.
- 이는 DSCL이 사용자의 과거 감정 상태를 모델링하는 데 있어서 필수적이고 효과적임을 보여줍니다.
- 의미적 일관성 측면에서도 DSCL이 생성한 응답만이 대화 컨텍스트에 적합하며, 이는 대조 학습에서의 양성 샘플이 모델의 의미 이해 능력에 강력한 보조 역할을 한다는 것을 보여줍니다.

6 CONCLUSION
- 이 연구에서는 공감적인 응답 생성 작업을 위한 이중 의미 대조 학습(DSCL) 모델을 제안합니다.
- DSCL 모델은 대조 학습 기술을 통합하고 사용자의 대화적 맥락 내에서의 과거 감정 상태를 통합하여 감정적으로 정확하고 주제와 관련이 있으며 의미 있는 응답을 생성합니다.
- 공개적으로 이용 가능한 대화 데이터셋에서의 경험적 검증은 DSCL의 효능을 입증하며, 자동 및 인간 평가 측면에서 기존의 공감적 응답 생성 기준 모델을 능가하는 우수성을 보여줍니다.
- 더 나아가, DSCL은 대화의 다음 턴을 안내하는 능력을 보여줌으로써 인간-기계 상호 작용의 지속 가능성에 기여합니다.
- 향후 연구는 [34]에서 언급된 대로 대규모 언어 모델을 활용하여 응답 다양성을 향상시키는 동시에 감정 정확도를 유지할 수 있는 방법을 탐구할 것입니다.
- 또한, 다양한 사용자의 다양한 요구를 충족시키기 위해 맞춤형 대화 시스템의 개발에 노력을 기울일 것입니다.
- 또한, 다른 클라이언트를 사용하는 사용자에 대해서는 맞춤형 대화 기계를 구축하는 것을 목표로 하고 있습니다.
Reference
- https://drive.google.com/file/d/1URYA58o2wkYsNmpFtiZPly1HZus29H09/view?usp=drive_link
댓글
댓글 쓰기