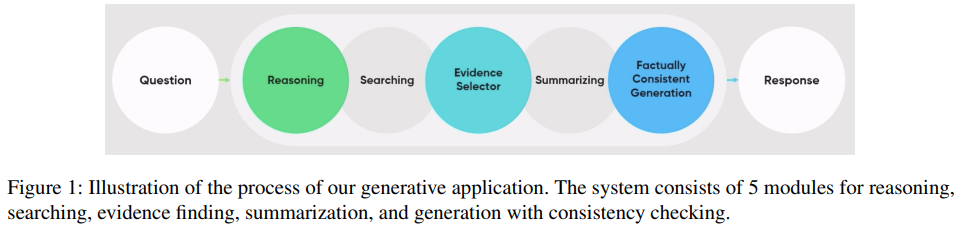
*NL-215, Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection, ICLR 2024

ABSTRACT 거대한 언어 모델 (LLMs)은 놀라운 능력을 가지고 있지만, 종종 그들이 단독으로 포함하는 매개 변수 지식에 의존하여 사실에 부합하지 않는 응답을 생성합니다. 검색 증강 생성 (RAG)은 이러한 문제를 감소시키는 임시적인 접근 방식으로, LMs를 관련 지식 검색으로 보강합니다. 그러나 검색이 필요한지 여부나 통합할 문장이 관련한지 여부에 관계없이 일정 수의 검색된 문장을 무차별적으로 검색하고 통합하는 것은 LM의 다양성을 줄이거나 도움이 되지 않는 응답 생성으로 이어질 수 있습니다. 우리는 Self-Reflective Retrieval-Augmented Generation (SELF-RAG)이라는 새로운 프레임워크를 소개합니다. 이는 검색과 self-reflection을 통해 LM의 품질과 사실성을 향상시킵니다. 우리의 프레임워크는 단일 임의의 LM을 훈련시키고 필요에 따라 적응적으로 문장을 검색하고, 검색된 문장과 자체 생성물에 대해 special tokens 인 reflection tokens을 사용하여 반영합니다. reflection tokens을 생성하면 추론 단계에서 LM을 제어할 수 있으므로, 다양한 작업 요구 사항에 맞게 그 동작을 맞춤화할 수 있습니다. 실험 결과 SELF-RAG (7B 및 13B 매개 변수)가 다양한 작업 집합에서 최첨단 LLMs와 검색 증강 모델을 크게 능가한다는 것을 보여줍니다. 특히 SELF-RAG는 오픈 도메인 QA, 추론 및 사실 확인 작업에서 ChatGPT 및 검색 증강 Llama2-chat을 능가하며, 이러한 모델과 비교하여 장문 생성에 대한 사실성 및 인용 정확도를 향상시키는 데 상당한 이득을 보입니다. 1 INTRODUCTION 모델과 데이터 규모가 증가하더라도 최첨단 LLMs는 사실적인 오류에 여전히 고민하고 있습니다 (Mallen et al., 2023; Min et al., 2023; Ouyang et al., 2022). 검색 증강 생성 (RAG) 방법 (그림 1 왼쪽;